


- What is Hadoop?
- Architecture of Hadoop
- Hadoop Ecosystem
- Features of Hadoop
- 1. Hadoop is Open Source
- 2. Hadoop Cluster is Extremely Scalable
- 3. Hadoop provides Fault Tolerance
- 4. Hadoop guarantees High Availability
- 5. Hadoop is very Cost-Effective
- 6. Hadoop is quite fast in Data Processing
- 7. Hadoop relies on the concept of Data Locality
- 8. Hadoop provides Feasibility
- 9. Hadoop assures Data Reliability
- Advantages of Hadoop
- Disadvantages of Hadoop
- Conclusion
- FAQ’s
What is Hadoop?
Hadoop has become a well-known term and is quite renowned in today’s digital world. If you have ever pondered what Hadoop is and why is it so popular, then you have come to the right place. This article talks explicitly about the features of Hadoop. Hadoop is an open-source framework, from the Apache foundation, proficient in processing huge chunks of heterogeneous data sets in a distributed manner across groups of commodity computers and hardware employing a simplified programming model. Hadoop implements a secure shared storage and analysis system.
Applications developed using Hadoop are operated on large data sets spread across groups of commodity computers. Commodity computers are affordable and are available widely. These are chiefly beneficial for obtaining greater computational power at a low cost.
In Hadoop, data resides in a distributed file system, which is known as a Hadoop Distributed File system, which is quite similar to data residing in a local file system of a personal computer system. The processing model is devised on the concept of ‘Data Locality’, where computational logic is sent to cluster nodes(servers) containing data. This computational logic is a consolidated variant of a program written in a high-level language like Java. Such a program processes data stored in Hadoop HDFS.
Architecture of Hadoop
Mentioned below is an advanced architecture of the multi-node Hadoop Cluster.

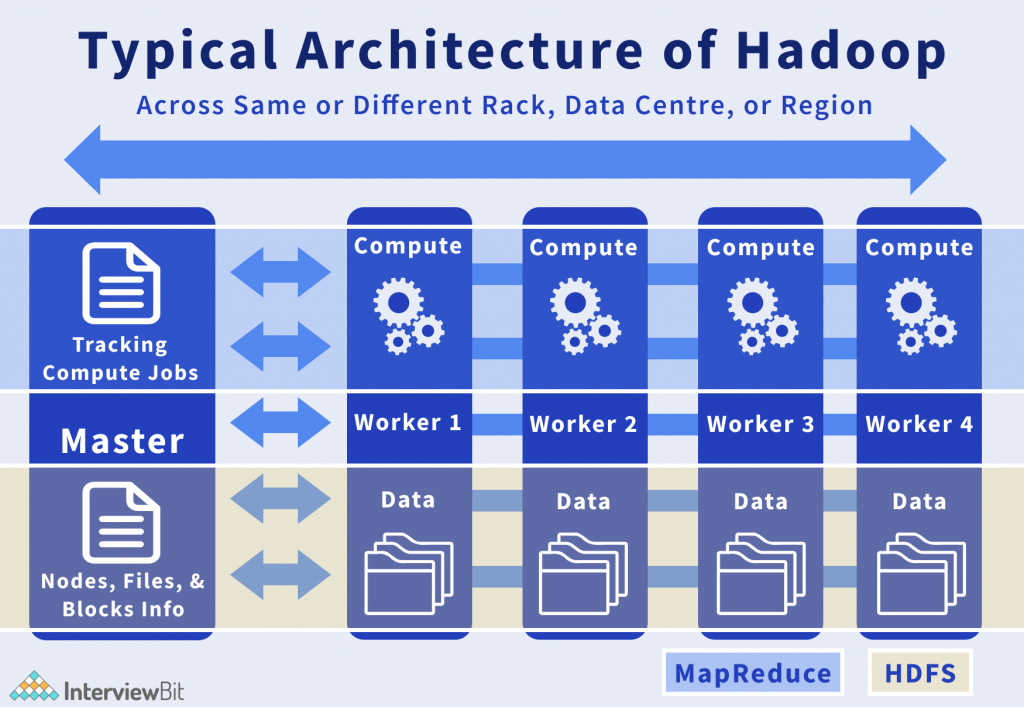
Let’s look at some of the few spotlights of the Hadoop Architecture:
- Hadoop operates in a master-worker or master-slave fashion.
- Hadoop has 2 major components: HDFS and MapReduce.
- Hadoop Distributed File System (HDFS) grants an extremely secure and distributed storage, and guarantees reliability, even on commodity hardware, by replicating the data across numerous nodes. Unlike the other regular file systems, when data is pushed to HDFS, it will automatically split into multiple blocks (configurable parameter) and store/replicates the data across various data nodes. It guarantees high availability and fault tolerance.
- MapReduce presents an analysis system that can deliver complex computations on large datasets. This component is responsible for delivering all the computations and operates by breaking down a large complex computation into various tasks and assigning those to individual slave or worker nodes and looks after consolidation and coordination of results.
- Even though Hadoop is considered for MapReduce and its distributed file system- HDFS, it is also used for similar projects that fall under large-scale data processing and distributed computing. Some Hadoop-related projects at Apache are HBase, Hive, Sqoop Mahout, ZooKeeper, and Flume.
- The master comprises Namenode and Job Tracker components.
- Namenode keeps all the information about all the other nodes in the Hadoop Cluster, existing files in the cluster, constituent chunks of files and their respective locations in the cluster, and other information helpful for the operation of the Hadoop Cluster.
- Job Tracker looks after the individual tasks or jobs allocated to each of the nodes and regulates the interchange of information and results.
- Each Worker or Slave includes the Datanode components and Task Tracker.
- Task Tracker is accountable for managing the task or computation assigned to it.
- Datanode is liable for holding the data.
- The computers present in the cluster can be present in any location and there doesn’t depend on the location of the physical server.
Hadoop Ecosystem
Hadoop can be beneficial for executing your production environment. It has four phases.
- Where is the Data?
- How much is the data?
- How do the data grow?
- What to do with the data?
These are some fundamental questions that are commonly asked when someone implements the Hadoop ecosystem. We can execute when we have a clear picture before us.
So, the essential steps are:
- Acquire: Flume, Kafka, Sqoop are the acquired tools. Sqoop is used for relational database sources to attain the data, Flume and Kafka can be implemented for semi-unstructured data ingestion. Once we have the data then we can arrange the data.
- Arrange: Data is organized on HDFS, post which, we have to process it.
- Process: There are a few tools with the help of which we process i.e Yarn (SOLR, MapReduce, Apache Giraph, Spark)
- Analyze: Hive, Pig, and Impala help to analyze the data.
Features of Hadoop
1. Hadoop is Open Source
Hadoop is an open-source project. Open-source indicates that its source code is available free of cost for adjustment, inspection, and analysis. It enables businesses to adjust the code as per their requirements.
2. Hadoop Cluster is Extremely Scalable
Hadoop is a very scalable storage platform as it can deposit and distribute massive data sets across hundreds of economical servers that run in parallel. Unlike the traditional relational database systems (RDBMS) that cannot scale to process huge chunks of data, Hadoop lets enterprises run applications on several nodes involving thousands of terabytes of data.
3. Hadoop provides Fault Tolerance
Fault tolerance is the most significant aspect of Hadoop. HDFS in Hadoop is equipped with a replication mechanism to incorporate fault tolerance. Hadoop produces a copy of each block on the different machines, which depends on the replication factor (by default, it is 3). So, if any machine in a cluster ever goes downhill, data will be reached from other machines bearing a copy of similar data. Hadoop 3 has superseded this replication mechanism by erasure coding. Erasure coding offers the exact level of fault tolerance with less space. With the help of Erasure coding, the storage overhead is not more than 50 per cent.
4. Hadoop guarantees High Availability
This particular aspect of Hadoop assures the high availability of data, even in unsuitable conditions. Due to the fault tolerance trait of Hadoop, if any of the DataNodes fails, the data is available to the user from various DataNodes enclosing a copy of the same data.
Additionally, the high availability Hadoop cluster comprises two or more running NameNodes (passive and active) in a hot standby configuration. The active node is known as the NameNode, which is active. The passive node is regarded as the standby node that studies edit logs modification of active NameNode and implements them to its namespace.
If an active node crashes, the passive node takes charge of the active node. Therefore, even if the NameNode fails, files are free and accessible to users.
5. Hadoop is very Cost-Effective
Hadoop also allows a cost-effective storage solution for businesses exploring data sets. The difficulty with conventional relational database management systems is that it is very cost-prohibitive to scale to such a degree in order to process such huge quantities of data. Earlier, to decrease costs, several organizations would have had to down-sample data and analyze it based on some assumptions as to which data was the most worthy. The raw data would be erased because it would be too cost-prohibitive to retain. While this strategy may have served in the short term, this meant that when organizational priorities changed, the entire raw data set was not available, since it was too expensive to store. On the other hand, Hadoop is devised as a scale-out architecture that can affordably save all of a company’s data for later use. The cost savings are unbelievable: instead of costing thousands to tens of thousands of pounds per terabyte, Hadoop allows computing and storage capacities for hundreds of pounds per terabyte.
6. Hadoop is quite fast in Data Processing
Hadoop strongly advocates distributed processing of data, implying faster processing. The data in Hadoop HDFS is saved in a distributed manner and MapReduce is accountable for the parallel processing of the data.
7. Hadoop relies on the concept of Data Locality
Hadoop is commonly acknowledged for its data nativity feature. It means moving computation logic to the data, instead of moving data to the computation logic. This aspect of Hadoop decreases the bandwidth usage in a system.
8. Hadoop provides Feasibility
Unlike the conventional system, Hadoop has the ability to process unstructured data. This feature renders feasibility to the users to interpret data of any format and size.
9. Hadoop assures Data Reliability
In Hadoop, owing to the replication of data in the cluster, data is saved on the cluster machines even when the machine fails.
The framework itself gives a mechanism to guarantee data reliability by Volume Scanner, Block Scanner, Directory Scanner, and Disk Checker. If your machine fails or data gets corrupted, even in that scenario your data is saved reliably in the cluster and is obtainable from the other machine containing a copy of data.
Advantages of Hadoop
Given below are some basic advantages of Hadoop.
- Hadoop undertakes a plethora of data. Data can come from a variety of sources such as social media, email conversations etc, and can be of a structured or unstructured form. Hadoop can obtain value from different data. It can accept data in an XML file, text file, CSV file, images, etc.
- Hadoop is a cost-effective solution since it utilizes a cluster of commodity hardware to save data. Commodity hardware is affordable machines therefore the cost of adding nodes to the framework is not on the higher side. In Hadoop 3.0 we just have 50 per cent of storage overhead as compared to 200 per cent in Hadoop2.x. This demands fewer machines to store data as the irrelevant data decreased significantly.
- The Hadoop framework looks after parallel processing, MapReduce developers do not need to care much about obtaining distributed processing, it is automatically done at the backend.
- Most of the latest technologies of Big Data work well with Hadoop like Spark, Flink, etc. They have processing engines with them that work over Hadoop as a backend. It means e employ Hadoop as a data storage platform for them.
- Hadoop attains a special place when it comes to storage methods on the file systems distribution, which assists in data mapping on the cluster. The processing tools are available on data servers and result in the speed of processing of data. When dealing with substantial disorganized volumes of data, it is competent to efficiently process data in terabytes.
- The fundamental benefit of Hadoop is fault tolerance. If the data is shifted to a single node, then the data is replicated in the cluster. Its distribution moved ahead of the deletion of name nodes; its architecture gives security from single and multiple nodes’ failure.
Disadvantages of Hadoop
Below mentioned are some disadvantages of Hadoop.
- Managing the applications like Hadoop may be difficult, and it may be presented as the security model of Hadoop. When we don’t have certainty in our data management, then our data is prone to risk. There is also the possibility of encryption missing to store at various levels of networking.
- Java is used for its scriptwriting, which is one of the well-known programming languages, hence cybercriminals can explore it and imply various breaches for numerous protection.
- As huge data is not exclusive to large companies, in the same way, all large data platforms are not ideal for the requirements of small data. Hadoop is also regarded as one of them, as it is devised with a high capacity to distribute file systems.
- Hadoop has problems with potential stability because it is a platform of open source, which means it is devised with different developers’ contributions.
- Read and write operation in Hadoop is unbalanced because we are dealing with large-size data i.e. in TB or PB. In Hadoop, the data read or write is performed from the disk making it challenging to implement in-memory calculation and leading to processing overhead or High up processing.
- Hadoop supports only batch processing. The batch process is nothing but the processes working in the background and does not have any kind of interaction with the user. The engines employed for these processes inside the Hadoop core are not effective. Generating the output with moderate latency is not possible with it.
Conclusion
Hadoop is an open-source framework, renowned for its unique characteristics like fault tolerance and high availability. It manages scalable clusters, and its frameworks are easy to use. It assures us that our data speed is processed for its distribution. Its trait of data locality reduces the system utilization of bandwidth. Java is used to write its structure using some C codes and scripts of shell, which runs in different commodity hardware for huge datasets working with the basic programming model. Hadoop is a data scientist skill for humongous data technology, and companies are paying a substantial amount for it and becoming a sought-after skill in the future and popularising in the market.
Every software used by the industry is packed with an assortment of shortcomings and gains. If the software is crucial for the company then one can utilize the benefits and take actions to reduce the shortcomings. We can observe that Hadoop has advantages that outweigh its faults making it a mighty solution to Big Data needs.
FAQ’s
Q.1: What are the key advantages of Hadoop?
Ans. The key advantage of Hadoop is it’s open-source in nature, that is its source code is freely available. Secondly, Hadoop is highly scalable. Thirdly, Hadoop can work on various types of data. It is flexible enough to save different forms of data and can run on both data with schema-less data (unstructured) and schema (structured).
Q.2: What is the function of Hadoop?
Ans: Hadoop, an open-source software framework’s major function is to store data and run apps on clusters of commodity hardware. It offers massive storage for any kind of data, immense processing power, and the capacity to manage virtually unlimited concurrent tasks or jobs.
Q.3: Why is Hadoop Important?
Ans: Hadoop makes it easier to utilize all the storage and processing capacity in cluster servers and to administer distributed processes against massive amounts of data. Hadoop confers the building blocks on which different services and applications can be devised.


