The four key APIs of the Apache Kafka distributed streaming platform is the Producer API, Consumer API, Streams API, and Connector API. In addition to offering redundant storage of massive data volumes, the Connector API and its features such as a message bus capable of throughput reaching millions of messages per second are capable of processing streaming data from real-time applications. In this Kafka tutorial, we’ll discuss the Kafka architecture. We will discuss API in Kafka. We will also learn about Kafka brokers, Kafka consumers, zookeepers, and producers. We will also get to know some fundamental Kafka concepts.
Let’s get started with the Apache Kafka architecture.
Introduction and Trends
The Producer, Consumer, Streams, and Connector APIs of Apache Kafka provide four key services: persistent storage of massive data volumes, message bus capable of throughput reaching millions of messages every second, redundant storage of massive data volumes, and parallel processing of huge amounts of streaming data. It is a solution designed for processing streaming data from real-time applications that have the capacity to handle millions of messages every second.
To run Kafka, a platform, you must first register with the Kafka Producer API and Consumer API, then connect to the Kafka cluster through Brokers, Consumers, Producers, and ZooKeeper. The Kafka Producer API, Kafka Streams API, and Kafka Connect API are used to manage the platform, while the Kafka cluster architecture is made up of Brokers, Consumers, Producers, and ZooKeeper.
Apache Kafka’s architecture is, in fact, simple, albeit for a reason: It eliminates the Kafkaesque complexities that often accompany messaging architectures. The intent of the architecture is to deliver an easier-to-understand method of application messaging than most of the alternatives. Kafka is known for being a fault-tolerant, fault-diffusional scalable log with a very simple data design.
Kafka allows for a persistent ordered data structure. A record cannot be deleted, or modified, only appended to the log. Kafka cluster keeps track of the order of items in Kafka logs and guarantees that the log is partitioned into distinct commits with equal priority. Messages are stored in the order they are received, which ensures the order and integrity of the record structure. Every record has an assigned unique sequential ID known as an offset, which is used to retrieve data. This ensures the log has a unique start and end point.

By providing set ordering and deterministic processing, Kafka addresses typical issues with distributed systems. In addition to sequential disk reads, Kafka benefits from ordered-on-disk message data storage because it keeps data on disk and in an ordered manner. Disk seeks are costly in terms of resource waste, and Kafka’s process of first reading and writing at a consistent pace, followed by simultaneous reads and writing, reduces resource waste. In addition to that, because Kafka reads and writes simultaneously, it does not get in the way of each other; it also offers great resource efficiency.
The fact that Kafka can scale up makes horizontal scaling effortless. For example, if you ask Kafka to handle a simple list update, it can do it with the same level of performance.
Kafka Architecture
The producer API, the consumer API, the streams API, and the connector API are the four core APIs in the Apache Kafka architecture. We will discuss them one by one:
- Producer API: An application can publish a stream of records to a Kafka topic using the Producer API.
- Consumer API: An application can subscribe to one or more topics and also process the stream of records generated to them using this API.
- Streams API: The streams API enables applications to convert input streams to output streams, which is accomplished by consuming an input stream from one or more topics and producing an output stream from one or more output topics. Furthermore, to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams into output streams, the streams API permits an application.
- Connector API: The Connector API is used to connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.

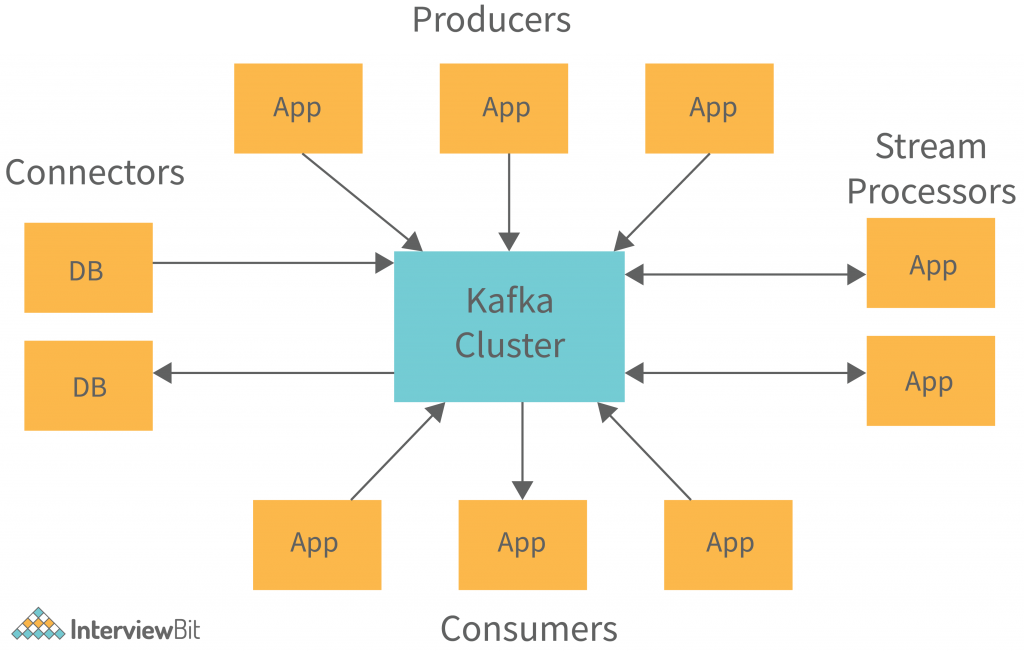
Kafka Cluster Architecture
The diagram provides information about the cluster structure of Apache Kafka:


The structure diagram above provides a detailed description of its architecture of Kafka, including:
Kafka Broker: When maintaining the state of the cluster, the Kafka cluster typically uses ZooKeeper. However, these are stateless brokers, so keeping the cluster state is a stateful task. Despite the fact that one Kafka Broker instance can handle hundreds of thousands of reads and writes per second, keeping the cluster state is a stateful process.
A broker can handle tens of millions of messages without performance impact, but ZooKeeper must perform Kafka broker-leader election.
Kafka – ZooKeeper: Kafka broker uses ZooKeeper to coordinate, manage, and report on the status of a Kafka broker in the Kafka system. It also informs producers and consumers about the presence of any new brokers or the failure of the current brokers.
Immediately after Zookeeper sends the notification regarding the broker’s presence or absence, producers and consumers make the decision and begin coordinating their work with another broker.
Kafka Producers: Kafka brokers receive data from Producers. In addition, all the Producers send messages to the new brokers when they start, thus automatically connecting all the Producers.
While the Kafka producer hands out messages as fast as the broker can process them, it does not wait for acknowledgments from the broker.
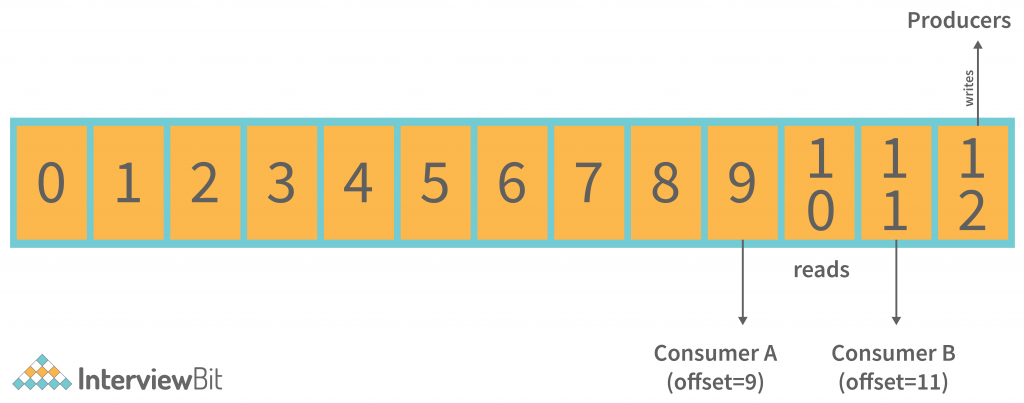
Kafka Consumers: The main advantage of partition offset is that the Kafka Consumer keeps track of how many messages have been consumed by keeping track of the partition offset. In addition, you can ensure that the consumer has consumed all prior messages by acknowledging every message offset.
There must be a buffer of bytes available to consume in order for the consumer to initiate a pull request. For example, if the offset is 5, consumers can rewind or skip to any point in a partition by supplying 5 as an offset value. ZooKeeper informs consumers of the offset value.
Fundamental Concepts of Kafka Architecture
We have listed some of the fundamental concepts of Kafka Architecture that you must understand.
Kafka Topics
Messages are received by producers through logical channels to which they publish messages and from which consumers receive messages.
- A data topic defines the stream of data of a particular type/classification. In Kafka.
- The way messages are structured or organised here impacts how they are received. A certain type of message is published on a certain topic.
- A producer initially writes its messages to the topics. Once consumers read those messages from topics, they are read by other consumers.
- A Kafka cluster has a topic named by its name and must be unique.
- You can cover any number of topics, but there is no limit to them.
- Data has to be published before it can be changed or updated.
The image provides information about the partitioning relationship between Kafka Topics and partitions:

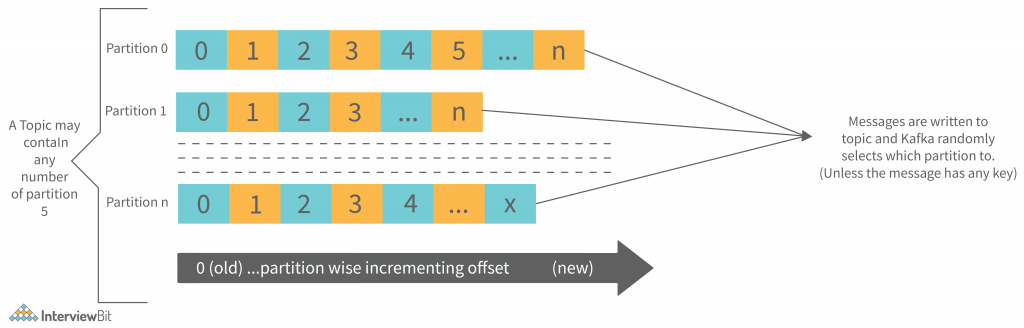
Partitions in Kafka
Partitions and also replicated across brokers are employed to divide up Topics in a Kafka cluster.
- Regardless of which partition the message is written to, there is no guarantee that it will be published to that partition.
- If a producer publishes a message with a specific key to Kafka, it will be ensured that all such messages (with the same key) will be delivered to the same partition. This feature ensures message sequencing. Even without a key being added to it, data is written to partitions randomly.
- Each message is stored in a sequence fashion in one partition.
- The messages are partitioned into chunks, and each chunk is assigned an incremental id, also known as offset.
- The offsets within a partition are only meaningful within that partition; however, the values across partitions are meaningless.
- There is no limit to the number of Partitions.
Topic Replication Factor in Kafka
When designing a Kafka system, it’s important to include topic replication in the algorithm. When a broker goes down, its topic replicas from another broker can solve the crisis, assuming there is no partitioning. We have 3 brokers and 3 topics.
Topic 1 and Partition 0 both have a replication factor of 2, and so on and so forth. Broker1 has Topic 1 and Partition 0, and Broker2 has Broker2. It has got a replication factor of 2; which means it will have one additional copy other than the primary copy. The image is below:

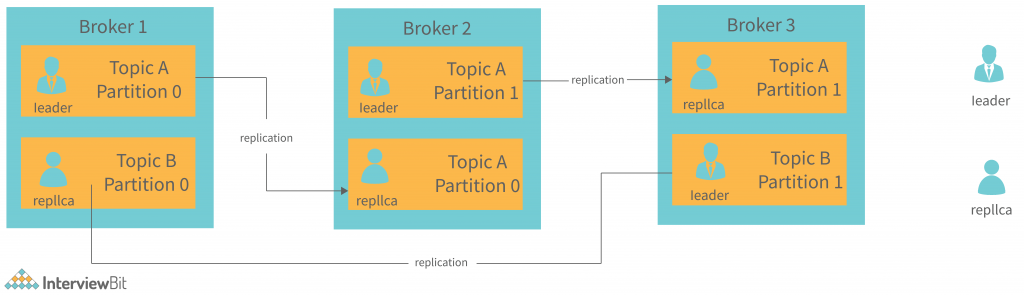
Some important points are stated:
- The level of replication performed is partition level only.
- There can be only one broker leader at a time for a given partition. Meanwhile, other brokers will maintain synchronised replicas.
- Having more than the number of brokers would result in an over-saturation of the replication factor.
Consumer Group
- There can be multiple consumer processes running.
- Every consumer group has its own group-id, which is basically one consumer group.
- Reading the data from one partition in one consumer group, at the time of reading, exactly one consumer instance reads the data.
- Consumer groups can read from one single partition since there is more than one consumer group.
- If the number of consumers exceeds the number of partitions, there will be some inactive consumers. We will discuss it with an example if there are 8 consumers and 6 partitions in a single consumer group. We have 2 inactive consumers in that situation.
Advantages of Kafka Architecture
Apache Kafka has the following features that make it worthwhile:
- The Apache Kafka platform offers a low latency value, i.e., up to 10 milliseconds. Because it decouples the message, the consumer can consume that message at any time.
- When using Kafka, businesses such as Uber can handle a lot of data at the same time because of its low latency. Kafka is able to handle a lot of messages in a second. Uber uses Kafka to store a lot of data.
- Kafka must have the ability to survive a node or machine failure within the cluster.
- A Kafka cluster can use the replication function, which makes data or messages persist on the cluster in addition to being written on a disk. This makes the cluster durable.
- A single Kafka integration handles all of a producer’s data. Therefore, we only need to create one Kafka integration, which automatically integrates us with every producing and consuming system.
- Anyone who has access to Kafka data can easily view it.
- The distributed system includes a distributed architecture that makes it scalable. Partitioning and replication are two of the distributed systems’ capabilities.
- With Apache Kafka, you can build a real-time data pipeline. It can handle a real-time data pipeline. Processors, analytics, storage, and the rest of the staff are required to build a real-time data pipeline.
- Kafka works as a batch-like operation and can also function as an ETL tool due to its data persistence abilities.
- A scalable software product is one that can handle large amounts of messages simultaneously. Kafka is such a product.
Disadvantages of Kafka Architecture
There are certain restrictions/disadvantages to Apache Kafka.
- An exception to the rule is that Apache Kafka does not come with a complete set of monitoring and management tools. Because of this, new ventures or enterprises avoid using Kafka.
- A message being tweaked by the Kafka broker requires system calls. In case the message needs some work, its performance of Kafka is reduced. So, it is advisable to keep the message the same.
- Apache Kafka does not permit wildcard topic selection. Instead, it applies only the exact topic name. The reason for this is that ignoring wildcard topics is unable to meet certain demands.
- The reduction in the data flow caused by brokers and consumers padding and decompressing the data flow affects its performance as well as its throughput.
- When there are more than one Kafka Queue in the Kafka Cluster, Apache Kafka can be a bit clumsy.
- Some message paradigms, such as point-to-point queues, request/reply, and so on, are absent from Kafka for certain use cases.
Conclusion
We discussed Kafka’s architecture earlier in the post. We also saw the Kafka components and basic concepts. We also saw a brief description of Kafka’s brokers, consumers, and producers. We also mentioned Kafka Architecture API in this post. If you want to know more about Kafka’s Architecture, please read the official documentation.