Today, we live in the digital era where companies produce and deal with vast amounts of data daily. The term “Big Data” describes this massive collection of structured and unstructured data, which continues to grow exponentially with increased digitization. However, because of the sheer volume and complexity of Big Data, traditional data processing software is not able to handle and extract useful information from data. That is why enterprises are turning to Big Data technologies nowadays. With the advent of big data technologies, companies are now able to store, process, and analyze vast amounts of data in order to discover relevant information. As we look forward to 2023, the good news is that there are a number of reliable big data technologies available to choose from. Now, the question is which of these technologies will be most promising going forward? Which Big Data tools can bring you substantial benefits?

To choose the most suitable Big Data technology, it is important to review and compare its features. In light of that, we will highlight the top Big Data technologies that are ready to transform the technical field. In this article, we’ll dive into the world of Big Data and explore the top Big Data technologies list you need to look out for in 2023. As well, we will discuss the features of the different big data technologies and the companies that utilize them.
Before diving into these technologies, let’s get a clear understanding of what Big Data Technology is all about.
What is Big Data Technology?
The term “Big Data” has been in vogue for many years now. “Big data” refers to the large volume, velocity, and variety of information assets that require cost-efficient, innovative methods to process data for enhanced insight and decision-making rather than traditional methods for data processing. Therefore, companies are embracing big data technologies to gain more insight and make more profitable decisions. Big Data Technologies are defined as software utilities that are primarily designed to analyze, process, and extract information from large datasets with extremely complex structures that cannot be handled by traditional data processing technologies.


The advent of Big Data technologies began to bridge the gap between traditional data technologies (such as RDBMS, File systems, etc.) and the rapidly expanding data and business needs. In essence, these technologies incorporate specific data frameworks, methods, tools, and techniques used for storing, examining, remodeling, analyzing, and evaluating data. This enormous amount of real-time data needs to be analyzed with Big Data Processing Technologies to arrive at conclusions and predictions that will help reduce future risks. Such capabilities are increasingly important in an era of the internet.
Types of Big Data Technologies
In general, Big Data Technology can be divided into two categories:
- Operational Big Data Technologies
Operational big data refers to all the data we generate from day-to-day activities such as internet transactions, social media platforms, or any information from a particular company. This data serves as raw data to be analyzed by Operational big data technology. Some examples of Operational Big Data Technologies include:

- Online ticket booking system, such as for trains, flights, buses, movies, etc.
- Online trading or shopping on e-commerce websites such as Flipkart, Amazon, Myntra, etc.
- Online data from social networking sites such as Instagram, Facebook, Messenger, Whatsapp, etc.
- Employee data or executive details in multinational companies.
- Analytical Big Data Technologies
Analytical Big Data may be viewed as a modified variant of Big Data Technologies, which is more complicated than Operational Big Data. Analytical Big Data is typically employed when performance metrics are involved, and when critical business decisions need to be taken on the basis of reports generated through operational big data analysis. Therefore, this type of big data technology pertains to analyzing big data relevant to business decisions. Some examples of Analytical Big Data Technologies include:


- Stock marketing data.
- Weather forecasting data.
- Medical records allow doctors to monitor the health status of a patient.
- Maintaining space mission databases in which every detail about a mission is important.
Top Big Data Technologies
Recently, many big data technologies have impacted the market and IT industries. They can be divided into four broad categories, as follows

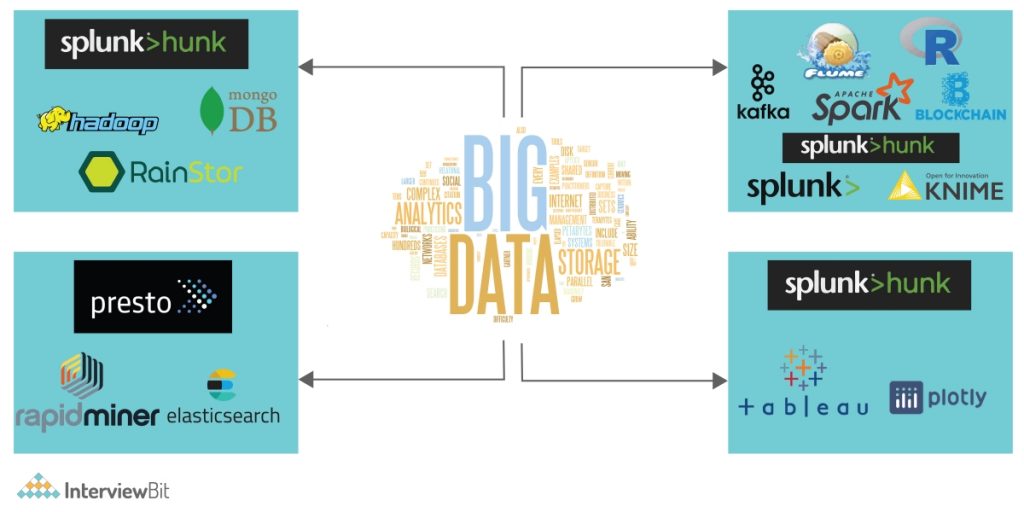
- Data Storage
- Data Mining
- Data Analytics
- Data Visualization
Let’s now examine the technologies falling under each of these categories with facts and features, along with the companies that use them.
Data Storage
Typically, this type of big data technology includes infrastructure that allows data to be fetched, stored, and managed, and is designed to handle massive amounts of data. Various software programs are able to access, use, and process the collected data easily and quickly. Among the most widely used big data technologies for this purpose are:
1. Apache Hadoop
Apache Hadoop is an open-source, Java-based framework for storing and processing big data, developed by the Apache Software Foundation. In essence, it provides a distributed storage platform and processes big data using the MapReduce programming model. The Hadoop framework is designed to automatically handle hardware failures since they are common occurrences. Hadoop framework consists of five modules, namely Hadoop Distributed File System (HDFS), Hadoop YARN (Yet Another Resource Negotiator), Hadoop MapReduce, Hadoop Common, and Hadoop Ozone.


Companies using Hadoop: LinkedIn, Intel, IBM, MapR, Facebook, Microsoft, Hortonworks, Cloudera, etc.
Key features:
- A distributed file system, called HDFS (Hadoop Distributed File System), enables fast data transfer between nodes.
- HDFS is a fundamentally resilient file system. In Hadoop, data that is stored on one node is also replicated on other nodes of the cluster to prevent data loss in case of hardware or software failure.
- Hadoop is an inexpensive, fault-tolerant, and extremely flexible framework capable of storing and processing data in any format (structured, semi-structured, or unstructured).
- MapReduce is a built-in batch processing engine in Hadoop that splits large computations across multiple nodes to ensure optimum performance and load balancing.
2. MongoDB
MongoDB is an open-source, cross-platform, document-oriented database designed to store and handle large amounts of data while providing high availability, performance, and scalability. Since MongoDB does not store or retrieve data in the form of tables, it is considered a NoSQL database. A new entrant to the data storage field, MongoDB is very popular due to its document-oriented NoSQL features, distributed key-value store, and Map Reduce calculation capabilities. This was named “Database Management System of the Year,” by DB-Engines, which isn’t surprising since NoSQL databases are more adept at handling Big Data than traditional RDBMS.

Companies using MongoDB: MySQL, Facebook, eBay, MetLife, Google, Shutterfly, Aadhar, etc.
Key features:
- It seamlessly integrates with languages like Ruby, Python, and JavaScript ; this seamless integration facilitates high coding velocity.
- A MongoDB database stores data in JSON documents, which provide a rich data model that maps effortlessly to native programming languages.
- MongoDB has several features that are unavailable in a traditional RDBMS, such as dynamic queries, secondary indexes, rich updates, sorting, and easy aggregation.
- In document-based database systems, related data is stored in a single document, making it possible to run queries faster than with a traditional relational database where related data is stored in multiple tables and later joined using joins.
3. RainStor
RainStor is a database management system that manages and analyzes big data and is developed by the RainStor company. A de-duplication technique is used in order to streamline the storage of large amounts of data for reference. Due to its ability to sort and store large volumes of information for reference, it eliminates duplicate files. Additionally, it supports cloud storage and multi-tenancy. The RainStor database product is available in two editions: Big Data Retention and Big Data Analytics on Hadoop, which enable highly efficient data management and accelerate data analysis and queries.

Companies using RainStor: Barclays, Reimagine Strategy, Credit Suisse, etc.
Key features:
- With RainStor, large enterprises can manage and analyze Big Data at the lowest total cost.
- The enterprise database is built on Hadoop to support faster analytics.
- It allows you to run faster queries and analyses using both SQL queries and MapReduce, leading to 10-100x faster results.
- RainStor provides the highest compression level. Data is compressed up to 40x (97.5 percent) or more compared to raw data and has no re-inflation required when accessed.
4. Cassandra
Cassandra is an open-source, distributed NoSQL database that enables the in-depth analysis of multiple sets of real-time data. It enables high scalability and availability without compromises in performance. To interact with the database, it uses CQL (Cassandra Structure Language). With scalability and fault tolerance on cloud infrastructure or commodity hardware, this is the ideal platform for mission-critical data processing. As a major Big Data tool, it accommodates all types of data formats, including structured, semi-structured, and unstructured.

Companies using Cassandra: Facebook, GoDaddy, Netflix, GitHub, Rackspace, Cisco, Hulu, eBay, etc.
Key Features:
- Cassandra’s decentralized architecture prevents single points of failure within a cluster.
- Data sensitivity makes Cassandra suitable for enterprise applications that cannot afford data loss, even when the entire data center fails.
- ACID (Atomicity, Consistency, Isolation, and Durability) are all supported by Cassandra.
- It allows Hadoop integration with MapReduce. It also supports Apache Hive & Apache Pig.
- Due to its scalability, Cassandra can be scaled up to accommodate more customers and more data as required.
Data Mining
Data mining is the process of extracting useful information from raw data and analyzing it. In many cases, raw data is very large, highly variable, and constantly streaming at speeds that make data extraction nearly impossible without a special technique. Among the most widely used big data technologies for data mining are:
5. Presto
Developed by Facebook, Presto is an open-source SQL query engine that enables interactive query analyses on massive amounts of data. This distributed search engine supports fast analytics queries on data sources of various sizes, from gigabytes to petabytes. With this technology, it is possible to query data right where it lives, without moving the data into separate analytics systems. It is possible even to query data from multiple sources within a single query. It supports both relational data sources (such as PostgreSQL, MySQL, Microsoft SQL Server, Amazon Redshift, Teradata, etc.) and non-relational data sources (such as HDFS (Hadoop Distributed File System), MongoDB, Cassandra, HBase, Amazon S3, etc.).

Companies using Presto: Repro, Netflix, Facebook, Airbnb, GrubHub, Nordstrom, Nasdaq, Atlassian, etc.
Key Features:
- With Presto, you can query data wherever it resides, whether it is in Cassandra, Hive, Relational databases, or even proprietary data stores.
- With Presto, multiple data sources can be queried at once. This allows you to reference data from multiple databases in one query.
- It does not rely on MapReduce techniques and is capable of retrieving data very quickly within seconds to minutes. Query responses are typically returned within a few seconds.
- Presto supports standard ANSI SQL, making it easy to use. The ability to query your data without learning a dedicated language is always a big plus, whether you’re a developer or a data analyst. Additionally, it connects easily to the most common BI (Business Intelligence) tools with JDBC (Java Database Connectivity) connectors.
6. RapidMiner
RapidMiner is an advanced open-source data mining tool for predictive analytics. It’s a powerful data science platform that lets data scientists and big data analysts analyze their data quickly. In addition to data mining, it enables model deployment and model operation. With this solution, you will have access to all the machine learning and data preparation capabilities you need to make an impact on your business operations. By providing a unified environment for data preparation, machine learning, deep learning, text mining, and predictive analytics, it aims to enhance productivity for enterprise users of every skill level.

Companies using RapidMiner: Domino’s Pizza, McKinley Marketing Partners, Windstream Communications, George Mason University, etc.
Key Features:
- There is an integrated platform for processing data, building machine learning models, and deploying them.
- Further, it integrates the Hadoop framework with its inbuilt RapidMiner Radoop.
- RapidMiner Studio provides access, loading, and analysis of any type of data, whether it is structured data or unstructured data such as text, images, and media.
- Automated predictive modeling is available in RapidMiner.
7. ElasticSearch
Built on Apache Lucene, Elasticsearch is an open-source, distributed, modern search and analytics engine that allows you to search, index, and analyze data of all types. Some of its most common use cases include log analytics, security intelligence, operational intelligence, full-text search, and business analytics. Unstructured data from various sources is retrieved and stored in a format that is highly optimized for language-based searches. Users can easily search and explore a large volume of data at a very fast speed. DB-Engines ranks Elasticsearch as the top enterprise search engine.


Companies using ElasticSearch: Netflix, Facebook, Uber, Shopify, Linkedln, StackOverflow, GitHub, Instacart, etc.
Key Features:
- Using ElasticSearch, you can store and analyze structured and unstructured data up to petabytes.
- By providing simple RESTful APIs and schema-free JSON documents, Elasticsearch makes it easy to search, index, and query data.
- Moreover, it provides near real-time search, scalable search, and multitenancy capabilities.
- Elasticsearch is written in Java, which makes it compatible with nearly every platform.
- As a language-agnostic open-source application, Elasticsearch makes it easy to extend its functionality with plugins and integrations.
- Several management tools, UIs (User Interfaces), and APIs (Application Programming Interfaces) are provided for full control over data, cluster operations, users, etc.
Data Analytics
Big data analytics involves cleaning, transforming, and modeling data in order to extract essential information that will aid in the decision-making process. You can extract valuable insights from raw data by using data analytic techniques. Among the information that big data analytics tools can provide are hidden patterns, correlations, customer preferences, and statistical information about the market. Listed below are a few types of data analysis technologies you should be familiar with.
8. Kafka
Apache Kafka is a popular open-source event store and streaming platform developed by the Apache Software Foundation in Java and Scala. The platform is used by thousands of organizations for streaming analytics, high-performance data pipelines, data integration, and mission-critical applications. It is a fault-tolerant messaging system based on a publish-subscriber model that can handle massive data volumes. For real-time streaming data analysis, Apache Kafka can be integrated seamlessly with Apache Storm and Apache Spark. Basically, Kafka is a system for collecting, storing, reading, and analyzing streaming data at scale.

Companies using Kafka: Netflix, Goldman Sachs, Shopify, Target, Cisco, Spotify, Intuit, Uber, etc.
Key Features:
- With Apache Kafka, scalability can be achieved in four dimensions: event processors, event producers, event consumers, and event connectors. This means that Kafka scales effortlessly without any downtime.
- Kafka is very reliable due to its distributed architecture, partitioning, replicating, and fault-tolerance.
- You can publish and subscribe to messages at high throughput.
- The system guarantees zero downtime and no data loss.
9. Splunk
Splunk is a scalable, advanced software platform that searches, analyzes, and visualizes machine-generated data from websites, applications, sensors, devices, etc., in order to provide metrics, diagnose problems, and gain insight into business operations. In Splunk, real-time data is captured, indexed, and correlated into a searchable repository, which can be used to generate Reports, Alerts, Graphs, Dashboards, and Visualizations. In addition to application management, security, and compliance, Splunk also provides web analytics and business intelligence. The advent of big data makes Splunk capable of ingesting big data from a variety of sources, which may or may not include machine data, and performing analytics on it.

Companies using Splunk: JPMorgan Chase, Lenovo, Wells Fargo, Verizon, BookMyShow, John Lewis, Domino’s, Porsche, etc. Learn More.
Key Features:
- Improve the performance of your business with automated operations, advanced analytics, and end-to-end integrations.
- In addition to structured data formats like JSON and XML, Splunk can ingest unstructured machine data like web and application logs.
- Splunk indexes the ingested data to enable faster search and querying based on different conditions.
- Splunk provides analytical reports including interactive graphs, charts, and tables, as well as allows sharing them with other people.
10. KNIME
KNIME (Konstanz Information Miner) is a free, open-source platform for analytics, reporting, and integration of large sets of data. In addition to being intuitive and open, KNIME actively incorporates new ideas and developments to make understanding data and developing data science workflows and reusable components as easy and accessible as possible. KNIME allows users to visually create and design data flows (or pipelines), execute analysis steps selectively, and analyze the results and models later using interactive views and widgets. As part of the core version, there are hundreds of modules for integration, data transformations (such as filters, converters, splitters, combiners, and joiners), as well as methods used for analytics, statistics, data mining, and text analytics.

Companies using KNIME: Fiserv, Opplane, Procter & Gamble, Eaton Corporation, etc.
Key Features:
- Additional Plugins are added via its Extension mechanism in order to extend functionality.
- Furthermore, additional plugins provide integration of methods for image mining, text mining, time-series analysis, and network analysis.
- The KNIME workflows can serve as data sets for creating report templates that can be exported to a variety of file formats, including doc, pdf, ppt, xls, etc.
- Additionally, KNIME integrates a variety of open-source projects such as machine learning algorithms from Spark, Weka, Keras, LIBSVM, and R projects; as well as ImageJ, JFreeChart, and the Chemistry Development Kit.
- You can perform simple ETL operations with it.
11. Apache Spark
The most important and most awaited technology is now in sight – Apache Spark. It is an open-source analytics engine that supports big data processing. This platform features In-Memory Computing (IMC) for performing fast queries against data of any size; a generalized Execution Model (GEM) that supports a wide range of applications, as well as Java, Python, and Scala APIs for ease of development. These APIs make it possible to hide the complexity of distributed processing behind simple, high-level operators. Spark was introduced by the Apache Software Foundation to speed up Hadoop computation.

Companies using Presto: Amazon, Oracle, Cisco, Netflix, Yahoo, eBay, Hortonworks, etc.
Key Features:
- The Spark platform enables the execution of programs 100 times faster on memory than Hadoop MapReduce or 10 times faster on disk.
- With Apache Spark, you can run an array of workloads including machine learning, real-time analytics, interactive queries, and graph processing.
- Spark has convenient development interfaces (APIs) available in Java, Scala, Python, and R for working with large datasets.
- A number of higher-level libraries are included with Spark, such as support for SQL queries, machine learning, streaming data, and graph processing.
Data Visualization
Data visualization is a way of visualizing data through a graphic representation. Data visualization techniques utilize visual elements such as graphs, charts, and maps to provide an easy way of viewing and interpreting trends, patterns, and outliers in data. Data is processed to create graphic illustrations that enable people to grasp large amounts of information in seconds. Below are a few top technologies for data visualization.
12. Tableau
In the business intelligence and analytics industry, Tableau is the fastest growing tool for Data Visualization. It makes it easy for users to create graphs, charts, maps, and dashboards, for visualizing and analyzing data, thus aiding them in driving the business forward. Using this platform, data is rapidly analyzed, resulting in interactive dashboards and worksheets that display the results. With Tableau, users are able to work on live datasets, obtaining valuable insights and enhancing decision-making. You don’t need any programming knowledge to get started; even those without relevant experience can create visualizations with Tableau right away.

Companies using Tableau: Accenture, Myntra, Nike, Skype, Coca-Cola, Wells Fargo, Citigroup, Qlik, etc
Key Features:
- In Tableau, a user can easily create visualizations in the form of Bar charts, Pie charts, Histograms, Treemaps, Box plots, Gantt charts, Bullet charts, and other tools.
- Tableau supports a wide array of data sources, including on-premise files, CSV, Text files, Excel, spreadsheets, relational and non-relational databases, cloud data, and big data.\
- Some of Tableau’s significant features include data blending and real-time analytics.
- It allows real-time sharing of data in the form of dashboards, sheets, etc.
13. Plotly
Plotly is a Python library that facilitates interactive visualizations of big data. This tool makes it possible to create superior graphs more quickly and efficiently. Plotly has many advantages, including user-friendliness, scalability, reduced costs, cutting-edge analytics, and flexibility. It offers a much richer set of libraries and APIs, including Python, R, MATLAB, Arduino, Julia, etc. It can be used interactively within Jupyter notebooks and Pycharm in order to create interactive graphs. With Plotly, we can include interactive features such as buttons, sliders, and dropdowns to display different perspectives on a graph.


Companies using Plotly: Paladins, Bitbank, etc.
Key Features:
- A unique feature of Plotly is its interactivity. Users can interact with graphs on display, providing an enhanced storytelling experience.
- It’s like drawing on paper, you can draw anything you want. When compared with other visualization tools like Tableau, Plotly enables full control over what is being plotted.
- Additionally to Seaborn and Matplotlib charts, Plotly also offers a wide range of graphs, and charts, such as Statistical Charts, Scientific Charts, Financial Charts, geographical maps, and so forth.
- Furthermore, Plotly offers a broad range of AI and ML charts, which allow you to step up your machine learning game.
Conclusion
Overall, the future of Big Data looks promising. The era of big data technology has given rise to various new innovations that are likely to gain popularity as the industry’s demands increase. These innovations will serve as a catalyst for business development.
In this article, we have seen a whole host of big data technologies including Apache Hadoop, Apache Spark, MongoDB, Cassandra, Plotly, and more that help with storing, mining, analyzing, and visualizing big data. Nevertheless, before settling on a big data tool or technique, it’s important to conduct thorough research because each tool or technique has its own unique features and can be applied to specific businesses. In order to make the most of Big Data technologies that are available on the market, it is essential to identify the type of problems your organization faces. Here’s your chance to make the move you want, according to your requirements. Hopefully, this article will assist the reader in navigating Big Data technologies without getting lost.