

- What is a Data Warehouse?
- Characteristics of Data Warehouse
- Data Warehouse Components
- Data Warehouse Database
- Sourcing, Acquisition, Cleanup, and Transformation Tools (ETL)
- Metadata
- Query Tools
- Data Marts
- Data Warehouse Management and Administration
- Information Delivery System
- Need for Data Warehousing
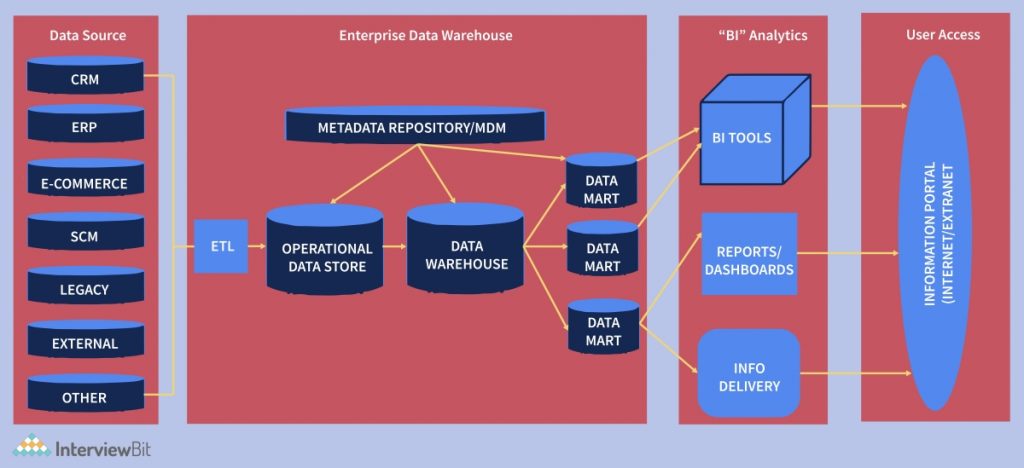
- Best Practices Data Warehouse Architecture
- Conclusion
- FAQs
- Q.1: What is a data warehouse framework?
- Q.2: What are the types of data warehouses?
- Q.3: What are data sourcing, transformation, and migration tools used for?
- Q.4: Name the four categories of query tools
- Additional Resources
The major element of the Business Intelligence (BI) system, Data Warehousing is liable for managing, storing, and collecting information from various heterogeneous sources to interpret the data for business decisions. For the last few years, the data warehouse architecture has been the support of corporate data ecosystems. And despite multiple modifications over the past five years in the field of cloud computing, Big Data, information technologies, predictive analysis, and data warehouses have only garnered more attention. Today, one cannot deny the significance of data warehousing, and there are more prospects available for examining, storing, and indexing data than ever. This article will talk about the data warehousing components, their characteristics, and the need for data warehousing.

What is a Data Warehouse?
A central repository, where raw data is transformed and stowed in query-able forms is the data warehouse. It is an information system that includes commutative and historical data from single or numerous sources. It streamlines the process of reporting and analysis of the organization. The data warehouse is also a single version of truth for any organization for forecasting and decision-making. Without it, data analysts and data scientists have to extract information straight from the production database and may end up documenting various results to the same question or render delays and even outages.
Bill Inmon, the father of the data warehouse and renowned author of multiple data warehouse books says that a data warehouse is an integrated, subject-oriented, non-volatile, time-variant, set of data, supporting management’s decision-making process. Technically, a data warehouse is a relational database enhanced for aggregating, reading, and querying enormous chunks of data. The DWH (Datawarehouse) streamlines the job of a data analyst, letting it manipulate all data from a single interface and deriving analytics, statistics, and visualizations. Generally, data warehouses are updated less frequently and are created to provide a historical, long-range view of data. The analytics that are run in a data warehouse, then, is more of an exhaustive view of your organization’s history instead of a snapshot of the existing condition of your business. As the data in a data warehouse is already transformed and integrated, it lets you compare older, historical data easily and track sales and marketing trends. These historical comparisons can be utilized to track failures and successes and indicate how to best move with your business ventures to improve profit and long-term ROI.
Characteristics of Data Warehouse
The following are the characteristics of a Data Warehouse:

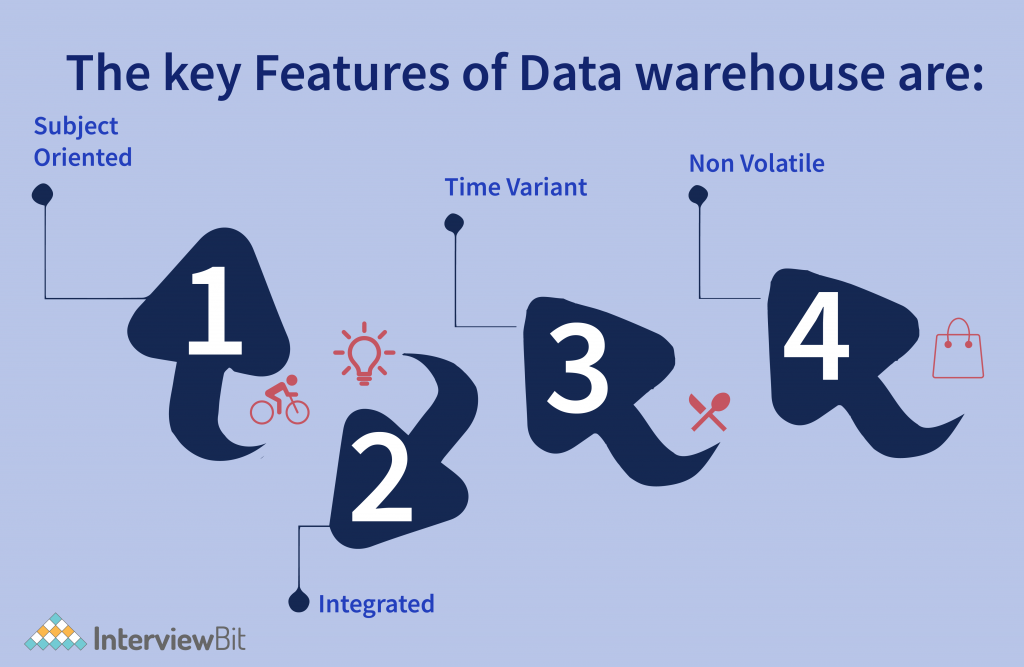
- Integrated: Integrated implies the establishment of a standard unit of measure for all equivalent data from the different databases. A data warehouse is created by combining data from various sources like relational databases, mainframes, flat files, etc. This integration helps in the effective analysis of data. Consistency in naming conventions, attribute measures, encoding structure etc. has to be ensured. Furthermore, it should keep consistent naming conventions, coding, and format.
- Subject-oriented: Being subject-oriented, Data Warehouse provides information regarding a theme rather than the organization’s existing operations. It can be accomplished on a specific theme, which indicates the data warehousing process is suggested to handle with a specific theme that is more specified. These themes can be marketing, sales, distribution, etc. A data warehouse never focuses only on current operations. Rather, it concentrates on establishing and analysis of data to make various decisions. It also provides an easy and clear demonstration around a particular theme by deleting data that is not needed to make the decisions.
- Non-volatile: The data living in the data warehouse is permanent and determined by its names. It also indicates that the information in the data warehouse cannot be deleted/erased when new data is incorporated into it. Data is read-only in the data warehouse, and can only be refreshed at a certain interval of time. Operations like update, delete, and insert that is accomplished in a software application over data are lost in the data warehouse environment. There are just two kinds of data operations that can be accomplished in the data warehouse:
- Data Loading
- Data Access
- Time-Variant: In this, data is maintained at various intervals of time like weekly, monthly, or annually, etc. It establishes different time limits which are structured between the enormous datasets and are held in the OLTP (online transaction process). The data warehouse’s time limit is wide-ranged as compared to that of operational systems. The data that lives in the data warehouse is predictable with a specific interval of time and provides information from a historical perspective. It contains aspects of time implicitly or explicitly. Another element of time variance is that once data is stowed in the data warehouse then it cannot be changed, adjusted, or updated. Every primary key contained with the DW should have either implicitly or explicitly an element of time. Like the day, week month, etc.
Read More About Characteristics of Data Warehouse
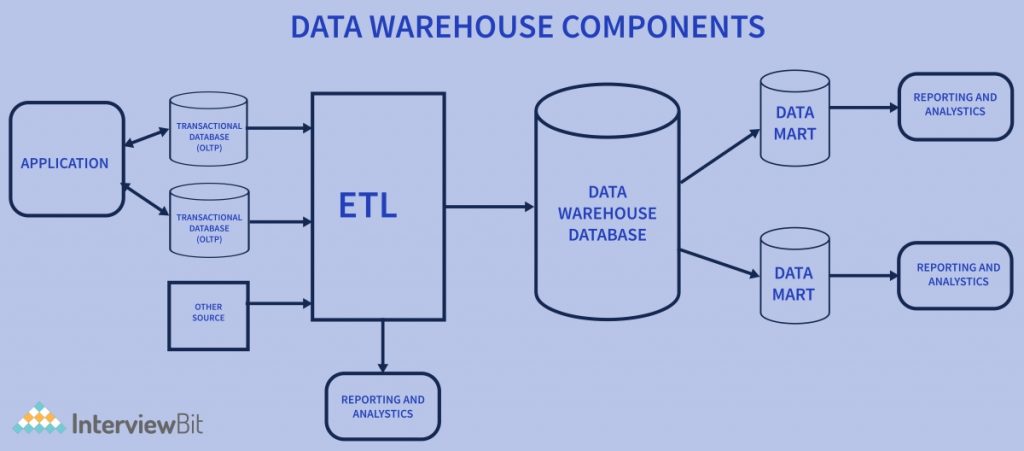
Data Warehouse Components

Data Warehouse Database
The foremost element of a Data Warehouse architecture is a database that stores all company data and makes it manageable to report.. This implies you ought to pick which type of database you’ll use to stow data in your warehouse.
Mentioned below are the four database types that you can utilize:
- Typical relational databases: You perhaps use these row-centred databases on an everyday basis, for instance, SAP, Oracle, Microsoft SQL Server, and IBM DB2.
- Analytics databases are specifically designed for storing data to support and handle analytics, like Greenplum and Teradata.
- Data warehouse applications aren’t exactly storage databases, but lots of dealers now provide applications that offer software for data management along with hardware for data storage. For instance, Oracle Exadata, IBM Netezza, and SAP Hana.
- Cloud-based databases can be retrieved and hosted on the cloud so that you don’t need to obtain any hardware to set up your data warehouse—for instance, Google BigQuery, Microsoft Azure SQL and Amazon Redshift.
Sourcing, Acquisition, Cleanup, and Transformation Tools (ETL)
A substantial part of the implementation effort is spent pulling data from operational systems and putting it in a format appropriate for informational applications that operate off the data warehouse. The data sourcing, cleanup, migration, and transformation tool fulfill all of the summarizations, conversions, structural changes, key changes, and condensations required to convert disparate data into data that can be utilized by the decision support tool. They produce the programs and control statements, such as the MVS job-control language (JCL), UNIX scripts, SQL data definition language (DDL), and COBOL programs, required to transfer data into the data warehouse for numerous operational systems. Metadata is also maintained by these tools. The functionality includes:
- Erasing undesirable data from operational databases
- Transforming to common data definitions and names
- Setting defaults for missing data
- Accommodating source data definition modifications
- Anonymize data as per regulatory stipulations.
- Eliminating unwanted data in operational databases from loading into Data warehouse.
- Search and replace common names and definitions for data arriving from different sources.
- Calculating summaries and derived data
- In case of missing data, populate them with defaults.
- De-duplicated repeated data arriving from multiple datasources.
The data sourcing, cleanup, extract, transformation, and migration tools have to deal with challenges of Database & Data heterogeneity
- Database heterogeneity. DBMSs are very diverse in data access language, data models, concurrency, data navigation, operations, recovery, integrity, etc.
- Data heterogeneity. This is the distinction in the way data is depicted and utilized in various models – synonyms, homonyms, unit compatibility (the U.S. vs metric), diverse attributes for the identical entity, and different ways of modelling similar fact.
A considerable amount of time and effort is saved with these tools. Nevertheless, substantial drawbacks can be seen. For instance, numerous available tools are generally good for easier data extracts.
Often, customized extract routines ought to be developed for the more complex data extraction methods.
Metadata

Metadata defines the data warehouse database and presents a framework for data, in the data warehouse architecture. It assists in handling, preserving, constructing, and making use of the data warehouse. Metadata helps to answer the following questions
What tables, attributes, and keys does the Data Warehouse contain?
Where did the data come from?
How many times do data get reloaded?
What transformations were applied with cleansing?
In data warehousing, there are two kinds of metadata:
- Technical Metadata includes data that can be utilized by programmers and managers when performing administration tasks and warehouse development.
- Business Metadata contains data that shows a readily comprehensible standpoint
of the information stowed in the warehouse.
Metadata has an essential role to play for companies and technical teams to comprehend the information present in the warehouse and transform it into information. Your data warehouse is a process and isn’t a project. To make your performance as efficacious as possible, you ought to, indeed take an agile approach, which entails a metadata-driven data warehouse architecture. This is a visual method to data warehousing that supports metadata-enriched data models to operate each element of the development process from noting source systems to copying schemas in a physical database and enabling mapping from source to destination.
At the metadata level, the data warehouse schema is set up, which implies you don’t have to get worked up regarding code quality and how it will meet high volumes of data. You can control and manage your data without going into the code. Furthermore, before deploying and replicating your schema in any leading database, you can concurrently test data warehouse models. A metadata-driven method expedites an iterative development culture and your data warehouse deployment is future-proofed. Hence, you can modify the current infrastructure with the new prerequisites without disturbing your data warehouse’s usability and integrity. Paired with automation capabilities, a metadata-driven data warehouse architecture can simplify deployment, design, and development, causing a rich data warehouse implementation.
Query Tools
The main intent of data warehousing is to deliver data to business users for the purpose of strategic decision-making. Utilizing front-end tools, these users interact with the data warehouse. A few of these tools need an information specialist, though many end users acquire specialization in the tools. Tools are categorized into four types: application development tools, query and reporting tools, data mining tools, and online analytical processing tools
- Query and Reporting tools can be segregated into two levels: reporting tools and managed query tools. Additionally, reporting tools can be split into report writers and production reporting tools.
- Production reporting tools allow businesses to develop regular operational reports or back high-volume batch jobs including computing and printing paychecks.
- On the other hand, Report writers are affordable desktop tools developed for end-users.
- Production reporting tools allow businesses to develop regular operational reports or back high-volume batch jobs including computing and printing paychecks.
- Managed query tools to protect end users from the intricacies of SQL and database structures by adding a meta-layer between the database and users. These tools are created for ease of use, point-and-click operations that accept SQL or develop SQL database queries.
Usually, the analytical requirements of the data warehouse user community surpass the built-in capacities of reporting and query tools. In these circumstances, companies usually rely on the tried-and-true approach of in-house application development with the help of graphical development conditions like Visual Basic, PowerBuilder, and Forte. These application development platforms blend well with common OLAP tools and access all significant database systems such as Sybase, Informix, and Oracle.
- OLAP tools are based on the notions of dimensional data models and connected databases, and let users study the data utilizing multidimensional and elaborate views. Standard business applications contain the effectiveness of a sales program or marketing campaign, product profitability and performance, capacity planning, and sales forecasting. These tools believe that the data is managed in a multidimensional model.
Today, a crucial success element for any enterprise is the capability to utilize data efficiently. The process of locating significant new correlations, trends, and patterns by exploring huge chunks of data stowed in the warehouse utilizing statistical and mathematical techniques and artificial intelligence is data mining.
Data Marts
The notion of a data mart is generating dollops of excitement and draws considerable attention in the data warehouse industry. Mainly, data marts are offered as an alternative to a data warehouse that takes very little time and money to create. Nevertheless, data mart implies various things to various people. Another meaning of it is a data store, the subsidiary of a data warehouse of integrated data. The data mart is directed at a division of data, referred to as a subject area that is designed for the benefit of a dedicated set of users. It might be a collection of summarized, denormalized, or aggregated data. Oftentimes, such a set could be situated in the data warehouse rather than a physically distinct store of data. However, in certain cases, the data mart is a physically distinct store of data and resides on a separate database server, oftentimes a local area network serving a certain user group. At times, the data mart just includes relational OLAP technology, which makes a highly denormalized dimensional model, for instance, star schema, executed on a relational database. The resultant hypercubes of information are utilized for research by users having a shared interest in a restricted part of the database. These kinds of data marts are known as dependent data marts as their data is received from the data warehouse, and maintains a high value since various users are all accessing the data views received from the single integrated version of the data, no matter the way they are deployed and how many other enabling technologies are utilized.
Sadly, the ambiguous statements regarding the simplicity and lower price of data marts occasionally lead to organizations wrongly placing them as an alternative to the data warehouse. This perspective describes independent data marts that in fact, portray fragmented point solutions to a spectrum of business issues in the enterprise. This kind of undertaking should be seldom deployed in the context of a general technology or applications architecture. Certainly, it is missing the element that is at the core of the data warehousing notion — that of data integration. Every self-reliant data mart makes its inferences regarding how to capsulize the data, and the data across different data marts may not be uniform. Also, the notion of an autonomous data mart is precarious — just as the first data mart is made, other institutions, subject areas, and groups within the enterprise venture on the job of creating their data marts. Therefore, you build an environment where numerous operational systems provide numerous non-integrated data marts that are frequently overlapping in job scheduling, data content, management, and connectivity. In a nutshell, you have converted a complicated many-to-one issue of creating a data warehouse from external and operational data sources to a many-to-many management and sourcing nightmare.
Data Warehouse Management and Administration
Data warehouses appear to be as much as 4 times as extensive as related operational databases, almost terabytes in size, which depends on how much history requires to be preserved. In real-time, they are not synchronized to the associated operational data but are revised as frequently as once a day, considering the needs of the application. Additionally, almost all products of data warehouses such as gateways can clearly access numerous enterprise data sources without the need to rewrite applications to analyze and use the data. Also, in a heterogeneous data warehouse environment, the different databases live on disparate systems, which requires inter-networking tools. The necessity to handle this environment is obvious. Handling data warehouses such as security and priority management, data quality checks, tracking updates from multiple sources, auditing and reporting data warehouse usage and status, handling and revising metadata, purging data, copying, subsetting, and distributing data, backup and retrieval, and data warehouse storage management.
Information Delivery System
The data delivery component is utilized to allow the method of subscribing for data warehouse data and getting it delivered to one or more places as per a certain user-specified scheduling algorithm. The information delivery system allocates warehouse-stored data and additional information objects to different data warehouses and end-user products like local databases and spreadsheets. Delivery of data can be based on the time of day or the fulfilment of an external event. The idea for the delivery systems component is made based on the fact that once the data warehouse is set and functional, its users will not have to be cognizant of its maintenance and location. All they require is a report or an analytical thesis of data at an exact point in time. With the expansion of the World Wide Web and the Internet, such a delivery system may support the benefit of the Internet by providing warehouse-enabled information to several end-users through the universal worldwide network.
Need for Data Warehousing
Data Warehousing is a progressively important tool for business intelligence. It allows companies to make quality business judgments. The data warehouse benefits by enhancing data analytics, it enables it to gain significant revenue and the power to compete strategically in the market. By effectively offering contextual, systematic, data to the business intelligence tool of an organization, the data warehouses can discover more practical business approaches.
- Business User: Business customers or users require a data warehouse to examine compiled data from the past. As these people hail from a non-technical background also, the data may be portrayed to them in an uncomplicated manner.
- Maintains consistency: Data warehouses are programmed in such a manner that they can be used in a standard format for all compiled data from various sources, which makes it easy for company decision-makers to share and study data insights with their associates around the world. By standardizing the data, the chance of mistakes in understanding is also decreased and enhances overall accuracy.
- Store historical data: Data Warehouses are also utilized to store historical data that indicates the time variable data from the past, and this input can be utilized for various purposes.
- Make strategic decisions: Data warehouses contribute in making more suitable strategic findings. Certain business strategies may be relying upon the pieces of information saved within the data warehouses.
- High response time: Data warehouse should be prepared for somewhat hasty masses and kinds of queries that require a significant degree of flexibility and quick latency.
Best Practices Data Warehouse Architecture
To create Data Warehouse Architecture, you must follow the below-mentioned best practices:
- Begin by determining the logic of the organization’s business. Comprehend what data is important to the organization and the way it will flow via the data warehouse. Choose the appropriate designing approach as a top-down and bottom-up approach in Data Warehouse.
- Ought to ensure that Data is processed fast and correctly. At the same time, you should opt for a method that converges data into a single version of the truth.
- Develop the data acquisition and cleansing method meticulously for the Data warehouse.
- Devise a MetaData architecture that permits metadata sharing between components of Data Warehouse
- Incorporate an ODS model when the data recovery requirement is close to the bottom of the data abstraction pyramid or when several operational sources need to be accessed.
- Make sure that the data model is not just consolidated but integrated. In that scenario, you should the 3NF data model can be considered. It is also perfect for attaining ETL and Data cleansing tools
Conclusion
The Web is transforming the data warehousing scenario since at a very high level the objectives of both the Web and data warehousing are the same: uncomplicated access to data. The value of data warehousing gets elevated when the correct information gets into the hands of those individuals who require it, where they need it and where they need it the most. Nevertheless, many companies have floundered with complicated client/server systems to provide end-users with the access they require. The cases become even more complicated to fix when the users are physically remote from the location of the data warehouse. The Web erases many of these issues by providing users with universal and comparatively inexpensive access to data. Pair this access with the capability to provide essential information on demand and the outcome is a web-enabled data delivery system that lets users scattered across continents perform sophisticated business-critical analysis and involve in collective decision-making.
FAQs
Q.1: What is a data warehouse framework?
Ans: The framework backs data warehouse schema evolution that can occur for several reasons, such as scenarios when schemas of data sources are modified. The supported modifications are deletion, insertion, and revising of a source relation, renaming, insertion, deletion, and modification of a type of source relation attribute.
Q.2: What are the types of data warehouses?
Ans: The three major kinds of data warehouses are operational data store (ODS), enterprise data warehouses (EDW), and data marts.
Q.3: What are data sourcing, transformation, and migration tools used for?
Ans: The data sourcing, transformation, and migration tools are used for performing all the conversions and summarizations.
Q.4: Name the four categories of query tools
Ans:
- Query and reporting, tools
- Application Development tools
- Data mining tools
- OLAP tools


