


- Why should you utilise SOLID design principles?
- SOLID Principles
- S: Single-responsibility principle
- O: Open/Closed Principle (OCP)
- L: Liskov Substitution Principle
- I: Interface Segregation Principle
- D: The Dependency Inversion Principle (DIP)
- Benefits of the SOLID principle
- Conclusion
- FAQs
- Q.1: What are SOLID principles?
- Q.2: Where are SOLID principles used?
- Q.3: Why do we use SOLID principles in C#?
- Q.4: What are the advantages of SOLID principles?
- Additional Resources
It’s easy to document software that fulfils its customers’ current needs but is challenging to expand and maintain. Such software turns problematic for organisations aiming to remain competitive.
In this article about SOLID Principles for C#, you will know about the five basic principles of object-oriented design that will keep your software loosely coupled, maintainable and testable.
First, you will learn about the way to keep classes small and focused, and how to expand their behaviour without the need to edit their source code. Second, you will discover the effect of perfectly designing abstractions and interfaces in your systems. Last, you will know about how to layout dependencies in your system so other implementations can be incorporated or plugged in as required, giving a truly modular design.


SOLID design principles are basic design principles, in C#. SOLID Principles facilitate us to win most of the design issues. Robert Martin, in the 1990s, composed these principles. These principles showed us different approaches to overcoming least encapsulation and tightly coupled code. Generally, programmers initiate the process of application building with clean and good designs depending on their experience. But, with time, applications might develop bugs and the application has to be modified for each new feature or change request. After a long time, we have to more effort possibly, even for minor tasks, and it might need a lot of energy and time. But since they are software development’s part, we cannot ignore them as well.
Let’s look at a few design issues which are creating damage to any software in many cases:
- When we put more stress on specific classes by assigning them more responsibilities to them, which are not related to that class.
- When we impose the class to hinge on each other or when they are tightly coupled.
- When we utilise duplicate code in the application
To overpower these concerns, we can incorporate the following tactics:
- We must select the appropriate architecture for the application
- We must adhere to the design principles carried out by experts.
- We must select the right design patterns to develop the software as per its specifications and requirements.
SOLID stands for the following:
- S = Single Responsibility Principle
- O = Open Closed Principle
- L = Liskov Substitution Principle
- I = Interface Segregation Principle
- D = Dependency Inversion Principle
Why should you utilise SOLID design principles?
As software programmers, the common tendency is to develop applications on the basis of your own hands-on experience and understand them right away. Nevertheless, with time, concerns in the application appear, adaptations to changes, and new features develop. Since then, gradually you realise that you have to invest a lot of effort into one thing: changing the application. Even when incorporating a basic task, it also demands comprehending the entire system. You can’t condemn them for modifications or new features as they are necessary parts of software development. So, what is the major problem here?
We could determine the evident answer from the design of the application. Keeping the system design scalable and clean is one of the significant things that any experienced programmer should devote their time to. And here is where the principles of SOLID design principles come into action. It helps programmers ignore design smells and develop the best designs for a set of features. In 2000, the SOLID design principles were first proposed by the leading Computer Scientist Robert C. Martin in his paper, later Michael Feathers introduced its acronym. Martin is also the writer of the best-selling books, Agile Software Development: Principles, Patterns, and Practices, Clean Architecture, Clean Code, and Designing Object-Oriented C++ Applications Using The Booch Method.
SOLID Principles
S: Single-responsibility principle
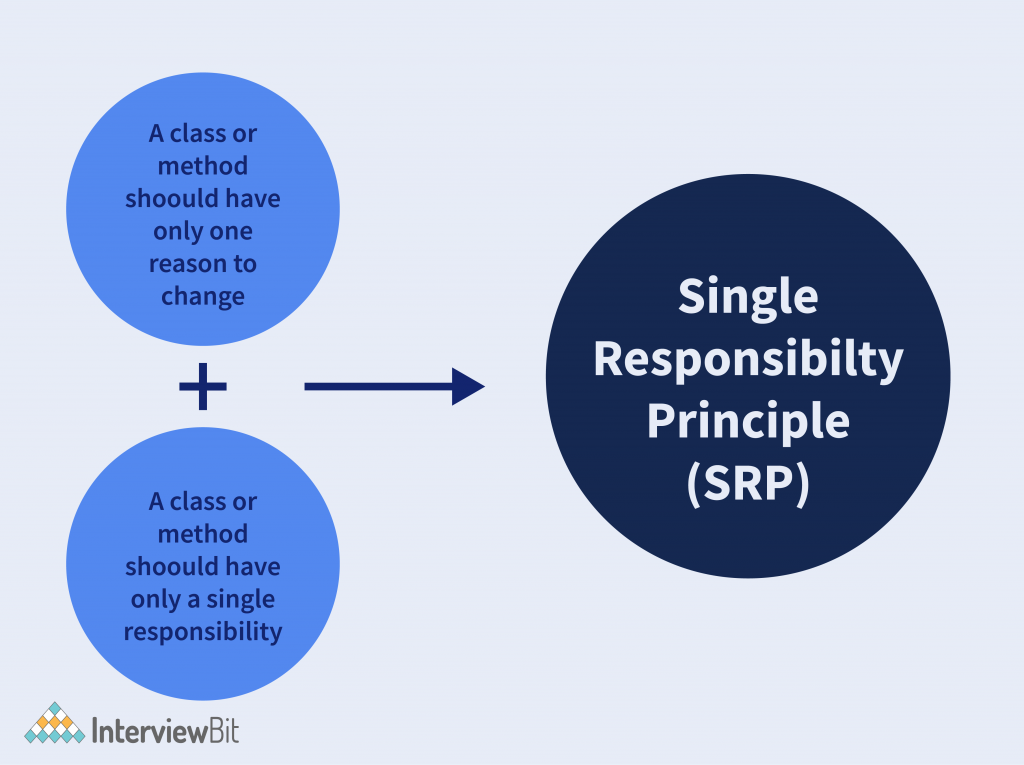
“A class should only have a single responsibility, that is, only changes to one part of the software’s specification should be able to affect the specification of the class.”
One of the most popularly utilised design principles, The Single Responsibility Principle, helps to achieve object-oriented goals. By implementing the single responsibility principle, we can cut down dependency between functionalities, therefore can better handle our code for incorporating new features over the long run. The single-responsibility principle (SRP) explains that every class, function or module in your program should only carry out one responsibility.
Each should take the job for a single functionality of the program. The class should comprise only methods and variables relevant to its functionality. Classes can function together to accomplish larger complicated tasks, but every class must execute a function from the beginning to the end before it sends the output to another class. Martin described this by stating “a class should have only one reason to change”. Here, the “reason” is that we wish to alter the single functionality this class pursues. If we do not choose this single functionality to vary, we will never alter this class, as all components of the class should relate to that behaviour.
SRP makes it simple to adhere to another well-respected principle of OOP, encapsulation. It is simple to hide data from the customer when all methods and data for a job are within the exact single-responsibility class. If you incorporate a getter and setter approaches into a single-responsibility class, the class matches all criteria of an encapsulated class. The advantages of programs that adhere to SRP are that you can adjust the behaviour of a function by modifying the single class responsible for it. Additionally, if a single functionality collapses, you know where the bug will be in the code and can count on the fact that only that class will break.

Example:
Let us look at the code below:
public class BankAccount
{
public BankAccount() {}
public string AccountNumber { get; set; }
public decimal AccountBalance { get; set; }
public decimal CalculateInterest()
{
// Code to calculate Interest
}
}
Here, BankAccount class comprises the properties of the account and computes the interest of the account. Now, look at the change Request we received from the business:
- Please implement a new Property AccountHolderName.
- Some new rule has been incorporated to calculate interest.
These are very different kinds of change requests. One is changing features while the other one is affecting the functionality. We have 2 separate kinds of reasons to change one class, which violates SRP.
Let’s use SRP to resolve this violation. Let us look at the code below:
public interface IBankAccount
{
string AccountNumber { get; set; }
decimal AccountBalance { get; set; }
}
public interface IInterstCalculator
{
decimal CalculateInterest();
}
public class BankAccount : IBankAccount
{
public string AccountNumber { get; set; }
public decimal AccountBalance { get; set; }
}
public class InterstCalculator : IInterstCalculator
{
public decimal CalculateInterest(IBankAccount account)
{
// Write your logic here
return 1000;
}
}
Our BankAccount class is just responsible for the properties of the bank account. If we wish to incorporate any additional business rule for the Calculation of Interest, we don’t require to change BankAccount class. Also InterestCalculator class needs no changes, in case we have to add a new Property AccountHolderName. Thus, this is the implementation of the Single Responsibility Principle.
Advantages of the Single Responsibility Principle
Let’s talk about the most significant questions before we delve into this design principle: Why should you use it?
The reasoning for the single responsibility principle is comparatively straightforward: it makes your software simpler to incorporate and restrict unforeseen side-effects of future changes.
- You should modify your class more often, and every modification is more complex, has more side effects, and needs a lot more effort than it should have. Thus, it’s good to ward off these problems by ensuring that each class has just one responsibility. Apart from that, if you wish to have a better understanding of what’s happening in your application, you can make use of Retrace’s code profiling solution.
- The class is simpler to comprehend. When the class just does “one thing”, usually its interface has a few methods that are reasonably self-explanatory. It should also have a few member variables (less than seven).
- The class is effortless to manage. Changes are isolated, cutting down the probability of splitting other unrelated areas of the software. As programming flaws are inversely proportional to complexity, being simpler to figure out makes the code less inclined to bugs.
- The class is more reusable. If a class has different responsibilities, and just one of those is required in another area of the software, then the additional irrelevant responsibilities deter reusability. Owning a single responsibility implies the class should be reusable without modification.
O: Open/Closed Principle (OCP)
This is the second principle of Solid Principles, which is described as follows:
“A software class or module should be open for extension but closed for modification”


If we have jotted a class, then it has to be flexible enough that we should not modify it (closed for modification) until bugs are there, but a new feature can be incorporated (open for extension) by implementing a new code without changing its existing code. This principle highlights that it should be plausible to expand functionality in classes without the need to alter the existing code in the classes. i.e. it should be feasible to expand the behaviour of the software without changing its core existing implementation. Basically, it specifies that devise your classes or code in such a manner that to insert new features into the software; you add new code without modifying existing code. Not modifying existing code has the advantage that you will not bring in new bugs into already working code.
By “open for extension” it implies that you should devise your code implementations in such a manner that you can utilise inheritance to incorporate new functionality in your application. Your design should be such that rather than modifying the existing class, add a new class that obtains from the base class and include a new code to this derived class. For inheritance, look towards interface inheritance rather than class inheritance. If the derived class revolves around the implementation in the base class, then you are building a dependency that is a tight coupling between the derived class and the base. With the interface, you can offer new features by including a new class that incorporates this interface without modifying the interface and prevailing other classes. The interface also facilitates loose coupling between classes that carry out the interface.
Example
Let us look at a scenario that violates OCP and then we’ll fix that.
public class Rectangle{
public double Width {get; set;}
public double Height {get; set;}
}
public class Circle{
public double Radious {get; set;}
}
public double getArea (object[] shapes){
double totalArea = 0;
foreach(var shape in shapes){
if(shape is Rectangle){
Rectangle rectangle = (Rectangle)shape;
totalArea += rectangle.Width * rectangle.Height;
}
else{
Circle circle = (Circle)shape;
totalArea += circle.Radious * circle.Radious * Math.PI;
}
}
}
If we have to calculate another type of object (say, Trapezium) then we’ve to add another condition. But from the rules of OCP, we have an idea that Software entities should be closed for modification. Hence it violates OCP. Let’s try to resolve this violation by using OCP.
public abstract class shape{
public abstract double Area();
}
public class Rectangle : shape{
public double Width {get; set;}
public double Height {get; set;}
public override double Area(){
return Width * Height;
}
}
public class Circle : shape{
public double Radious {get; set;}
public override double Area(){
return Radious * Radious * Math.PI;
}
}
public double getArea (shape[] shapes){
double totalArea = 0;
foreach(var shape in shapes){
totalArea += shape.Area();
}
return totalArea;
}
Now if we have to calculate another type of object, we don’t have to alter logic (in getArea()), we just have to add another class like Rectangle or Circle.
Implementation Guidelines for the OCP in C#
- The simplest approach to carry out the Open-Closed Principle in C# is to include the new functionalities by building new derived classes that need to be inherited from the original base class.
- Another step is to let the client access the original class with the help of an abstract interface.
- So, when there is a difference in need or any additional need comes, then rather than touching the prevailing functionality, it’s always better proposed to design new derived classes and let the original class implementation be as it is.
Issues of not following the OCP in C#:
If you are not adhering to the OCP during the process of the application development process, then your application development may result in the following problems:
- If you let a function or class include new logic, then as a programmer you have to test the entire functionalities, including the old functionalities and the latest functionalities of the application.
- As a programmer, the onus is on you to inform the QA (Quality Assurance) team about the modifications beforehand so that they can, in advance, prepare themselves for regression testing along with testing the new features.
- If you are not adhering to the Open-Closed Principle, then it also splits the Single Responsibility Principle, since the module or class is going to achieve several responsibilities.
- If in a single class you are incorporating all the functionalities, then the maintenance of the class becomes challenging
Owing to the above mentioned important points, we need to abide by the open-closed principle in C# while building the application.
L: Liskov Substitution Principle
“Objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.”

Barbara Liskov introduced the Liskov Substitution Principle in her conference keynote data abstraction in 1987. The chief title was Data abstraction and hierarchy in a computer program. A few years down the line, in collaboration with Jeanette Wing, they published a paper where they described the principle as:
Let Φ(x) be a property provable concerning objects x of type T. Then Φ(y) has to be true for objects y of type S, where S is a subtype of T.
This interpretation appears to be too much pedagogical than practical. Liskov Substitution Principle is about how you design your solution hierarchy with the help of abstractions while retaining the logic as robust and intact. If the academic definition has to be explained, an object B inherits/extends object A, we assume that any logic expecting A should function accurately if B is passed to it. If you are already functioning with an OOP (Object Oriented Programming) language, you would learn that most compilers would perform static checking to ensure that if class B inherits from class A, all members in A can be found in B. Thus, this is not actually the point. You should make sure that the code of B is not hiding any intentions that could split the logic. This will not be detected by the compiler, you need to do it yourself.
Example
LSP Rules
When you’re struggling to comprehend the Liskov Substitution Principle, it’s hard to look for a concise description of the rules. The rules are modest enough to describe, but the implications can be tricky to figure out. The effect of the violation of the Liskov Substitution Principle can be important, and it can end in investing a lot of time spent fixing bugs. Hence, Liskov Substitution Principle is essential if your prevailing code consists of a lot of supertype-subtype relationships.
The LSP rules are:
- Subclass should incorporate all classes of the base class. This implies there should be no techniques that throw “NotImplementedException”.
- Overridden method of the parent class has to accept the exact parameters in the child class. For instance, you possess a method “CalculateSquare” in the parent class that accepts an int as a parameter. This implies you can’t point out the exact method in the child class, override it with the keyword new, and design an extra rule that will confirm that the number is not negative. If you attempt to pass -3 in the client code but utilise the child class rather than the superclass, the client code will have the exception. And that’s not the behaviour that was proposed by the base class.
Advantages
- Stops code to break if someone by mistake has altered the base class with the derived class since its behaviour does not change
- Derived classes can readily throw exceptions for the method which are not managed by them.
Example:
Supposedly we are designing the payment module for our eCommerce website. Customers order products on the site and pay with the payment instruments like a credit card or a debit card.
When a customer provides their card details, we want to
- validate it,
- run it through a third-party fraud detection system,
- and then send the details to a payment gateway for processing.
Here is an example of a class structure which violates LSP:
public class Project
{
public Collection<ProjectFile> ProjectFiles { get; set; }
public void LoadAllFiles()
{
foreach (ProjectFile file in ProjectFiles)
{
file.LoadFileData();
}
}
public void SaveAllFiles()
{
foreach (ProjectFile file in ProjectFiles)
{
if (file as ReadOnlyFile == null)
file.SaveFileData();
}
}
}
public class ProjectFile
{
public string FilePath { get; set; }
public byte[] FileData { get; set; }
public void LoadFileData()
{
// Retrieve FileData from disk
}
public virtual void SaveFileData()
{
// Write FileData to disk
}
}
public class ReadOnlyFile : ProjectFile
{
public override void SaveFileData()
{
throw new InvalidOperationException();
}
}
Here the Project class has been changed to include two collections rather than one. One collection comprises all of the files in the project and one holds references to writeable files only. The LoadAllFiles method loads data into all of the files in the AllFiles collection. As the files in the WriteableFiles collection will be a subset of the same references, the data will be visible via these also. The SaveAllFiles method has been replaced with a method that saves only the writeable files.
The ProjectFile class now comprises just one method, which loads the file data. This method is needed for both writeable and read-only files. The new WriteableFile class extends ProjectFile, incorporating a method that saves the file data. This reversal of the hierarchy means that the code now complies with the LSP.
The refactored code is as follows:
public class Project
{
public Collection<ProjectFile> AllFiles { get; set; }
public Collection<WriteableFile> WriteableFiles { get; set; }
public void LoadAllFiles()
{
foreach (ProjectFile file in AllFiles)
{
file.LoadFileData();
}
}
public void SaveAllWriteableFiles()
{
foreach (WriteableFile file in WriteableFiles)
{
file.SaveFileData();
}
}
}
public class ProjectFile
{
public string FilePath { get; set; }
public byte[] FileData { get; set; }
public void LoadFileData()
{
// Retrieve FileData from disk
}
}
public class WriteableFile : ProjectFile
{
public void SaveFileData()
{
// Write FileData to disk
}
}
I: Interface Segregation Principle
“Many client-specific interfaces are better than one general-purpose interface.”


ISP (interface segregation principle) demands that classes will only be capable of performing behaviours that are helpful in achieving their end functionality. Classes do not consist of behaviours they do not use. This refers to our first SOLID principle. Together, ISP and OCP principles remove a class of all methods, behaviours, or variables that do not directly add to their role. Methods should add to the end goal in their entirety. This principle defines that the client should not be made to hinge on methods it will not implement. This principle supports the incorporation of several small interfaces rather than one big interface since it will let clients choose the needed interfaces and implement the same.
The aim of this principle is to split the software into minor classes that do not carry out the interface or methods which will not be used by the class. This will facilitate keeping the class stay put, lean and decoupled from dependencies. This principle advises not to enforce one big interface rather, there should be several small interfaces that can be chosen by classes that require implementing those. The interface which is incorporated by the class has to be closely related to the responsibility which will be implemented by the class. While creating interfaces, we should design according to the Single Responsibility Principle in Solid Principles. We should aim to keep our interfaces small since larger interfaces will involve additional methods and all implementors might not require several methods. If we keep interfaces large, it might result in many functions in the implementor class, which can also go against the Single Responsibility Principle.
The benefit of ISP is that it breaks large methods into minor, more precise methods. This makes the program simpler to debug for the below-mentioned reasons:
- There is limited code transferred between classes. Less code implies fewer bugs.
- A single method handles a smaller range of behaviours. If there is an issue with a behaviour, you are only required to look over the minor methods.
If a general method with several behaviours is transferred to a class that doesn’t back all behaviours, including calling for a property which the class doesn’t own, there will be a bug if the class seeks to utilize the unsupported behaviour.
Example
Let’s look at an example of an ISP violation and then refactor that violation.
ISP violation :
public interface IMessage{
IList<string> ToAddress {get; set;}
IList<string> BccAddresses {get; set;}
string MessageBody {get; set;}
string Subject {get; set;}
bool Send();
}
public class SmtpMessage : IMessage{
public IList<string> ToAddress {get; set;}
public IList<string> BccAddresses {get; set;}
public string MessageBody {get; set;}
public string Subject {get; set;}
public bool Send(){
// Code for sending E-mail.
}
}
public class SmsMessage : IMessage{
public IList<string> ToAddress {get; set;}
public IList<string> BccAddresses {
get { throw new NonImplementedException(); }
set { throw new NonImplementedException(); }
}
public string MessageBody {get; set;}
public string Subject {
get { throw new NonImplementedException(); }
set { throw new NonImplementedException(); }
}
public bool Send(){
// Code for sending SMS.
}
}
In the SmsMessage we don’t require BccAddresses and Subject, but we are forced to implement it because of IMessage interface. So it violates the ISP principle.
Remove violation as per ISP:
public interface IMessage{
bool Send(IList<string> toAddress, string messageBody);
}
public interface IEmailMessage : IMessage{
string Subject {get; set;}
IList<string> BccAddresses {get; set;}
}
public class SmtpMessage : IEmailMessage{
public IList<string> BccAddresses {get; set;}
public string Subject {get; set;}
public bool Send (IList<string> toAddress, string messageBody){
// Code for sending E-mail.
}
}
public class SmsMessage : IMessage{
public bool Send (IList<string> toAddress, string messageBody){
// Code for sending SMS.
}
}
SmsMessage needs only toAddress and messageBody, so now we can utilise IMessage interface to avoid unnecessary implementation.
D: The Dependency Inversion Principle (DIP)
“One should depend upon abstractions, [not] concretions.”
The dependency inversion principle is the fifth principle of Solid Principles, which is described as follows. This principle indicates that loose coupling between high level and low-level classes should exist and to get this, loose coupling elements should rely on abstraction. In straightforward terms, it suggests that classes should rely on abstract classes/interfaces and not on concrete types.
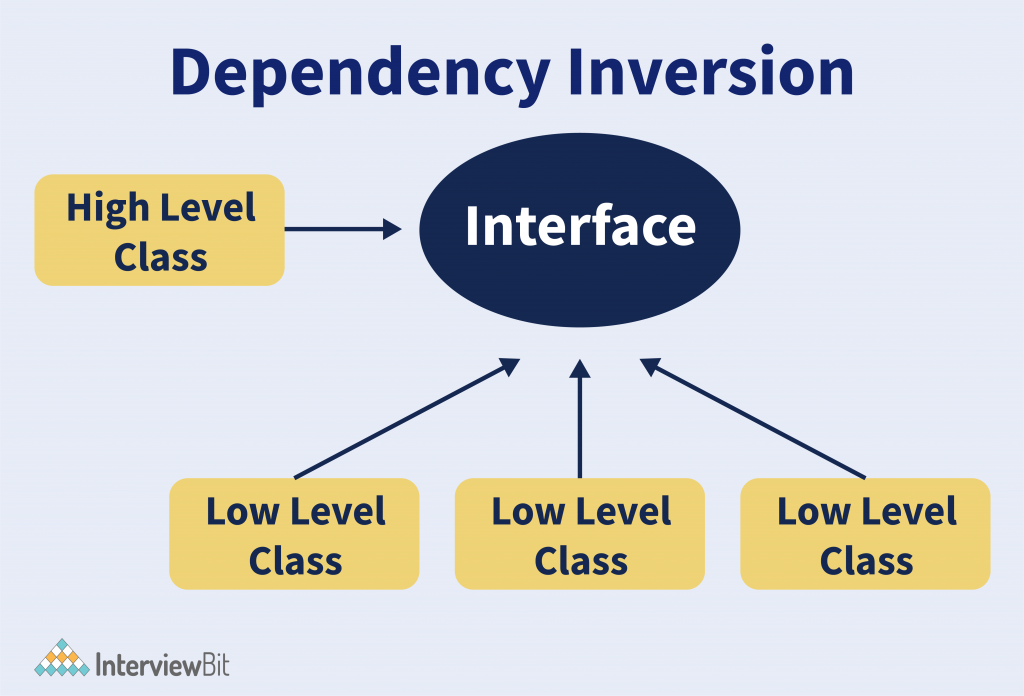
This principle in Solid Principles is also regarded as Inversion of control (IoC) and was initially hailed IoC, but Martin Fowler proposed the name DI i.e. Dependency Inversion or Dependency Injection. This principle simply states that you should bring in abstraction between high level and low-level classes that lets us decouple the high level and low-level classes from each other. If classes rely on each other, then they are tightly coupled with each other. When classes are tightly coupled, then modifications in one class bring about modifications in all other dependent classes. Rather, low-level classes should incorporate contracts using abstract classes or interface and high-level classes should adopt these contracts to access concrete types. We relate this principle to other principles in Solid Principles. If you adhere to both the Liskov Substitution Principle and Open/Closed Principle in your code, then it will indirectly also abide by the Dependency Inversion Principle.
What are the Low-Level and High-Level Modules?
The low-level modules involve more precise individual components, concentrating on details and minor parts of the application. These modules are utilised within the high-level modules in our application.
The high-level modules define those operations in our application that possess an extremely abstract nature and comprise more complicated logic. These modules deal with low-level modules in our application.
What we ought to know when we talk about the Dependency inversion principle and these modules is that both, the low-level and high-level modules, rely on abstractions. We can identify several opinions concerning if the DIP inverts dependency between high-level and low-level modules or not. Some comply with the first opinion and others adopt the second. But the familiar ground is that the DIP forms a decoupled structure between high-level and low-level modules by presenting abstraction between them.
Benefits
- Classes rely on abstraction and do not depend on concrete types
- Low-level and high-level classes are loosely coupled
- As long as you are not modifying contracts, variation in one class will not trigger a shift in another class
- Since classes rely on abstraction, change in one class will not split another class
Example
Let’s imagine that we are designing a notifications client (for example, a trite. We want to be able to send both email and SMS text notifications. Here is a sample class:
public class Email
{
public string ToAddress { get; set; }
public string Subject { get; set; }
public string Content { get; set; }
public void SendEmail()
{
//Send email
}
}
public class SMS
{
public string PhoneNumber { get; set; }
public string Message { get; set; }
public void SendSMS()
{
//Send sms
}
}
public class Notification
{
private Email _email;
private SMS _sms;
public Notification()
{
_email = new Email();
_sms = new SMS();
}
public void Send()
{
_email.SendEmail();
_sms.SendSMS();
}
}
Notice that a higher-level class, the Notification class, has a dependency on both the Email class and the SMS class, which are lower-level classes. Since DIP wants us to have both high and low-level classes depending on abstractions, we are currently violating the Dependency Inversion Principle.
public class Notification
{
private ICollection<IMessage> _messages;
public Notification(ICollection<IMessage> messages)
{
this._messages = messages;
}
public void Send()
{
foreach(var message in _messages)
{
message.SendMessage();
}
}
}
Here we have allowed both high-level and low-level classes to rely on abstractions, thereby upholding the Dependency Inversion Principle.
Benefits of the SOLID principle
Mentioned below are the benefits of the SOLID principle when implemented in your software design process:
Accessibility
The SOLID Principle assures uncomplicated to control and access to object entities. The integrity of stable object-oriented applications gives easy access to objects, reducing the chances of unintended inheritance.
Ease of refactoring
Software changes with time. Thus, programmers are required to develop applications, considering the possibility of future changes. Software applications which are poorly constructed make it challenging to refactor, but it is quite easy to refactor your codebase with the SOLID principle.
Extensibility
The software goes through stages of improvement, including extra features. If the features of an application are not extended tactfully, this could affect prevailing functionalities and lead to unexpected problems. The process of extensibility could be a tiring process since you require to design existing functionalities in the codebase, and if the existing functionalities are not rightly designed, this can make it even more challenging to include extra features. But the application of SOLID principles causes the extensibility procedure to be smoother.
Debugging
Debugging is an important aspect of the software development process. When software applications are not rightly devised, and the codebase gets clustered like spaghetti, it becomes difficult to debug applications. The SOLID principle embodies the feature of assuring that the software’s debugging process is much more comfortable.
Readability
A well-designed codebase can be simple to comprehend and easy to read. Readability is also a crucial element in the software development process as it makes the refactoring and debugging operations easier, specifically in open-source projects. The SOLID principle method assures that your code is comparatively easier to read and interpret.
Conclusion
In this article, we talked about Solid Principles and covered every principle with the definition, explanation and benefits of using it. Solid Principles will assist you to document a loosely coupled code that makes it less error-prone. So far, the above explanation helps you determine SOLID principles in the right and wrong way. While refactoring many projects, it’s really tricky to modify the code structure if you don’t apply the SOLID principles. Simple, comprehensible, scalable, and loosely coupled are all critical aspects we should focus on. Without these principles, the codebase will turn into a nightmare for other programmers to manage and update later. Hopefully, this article will inspire you to implement these principles in the C# code structure and benefit from their characteristics. You should make the most of each chance you get to use SOLID as much as possible. It will enhance your experiences in devising the most beautiful codebase. Implement Solid Principles to your code and you will notice that your code will be flexible, easy on maintenance and your code lifespan will increase.
FAQs
Q.1: What are SOLID principles?
Answer: SOLID is the short form of the five important design principles:
- Single responsibility principle
- Open-closed principle
- Liskov substitution principle
- Interface segregation principle
- Dependency inversion principle.
Software engineers commonly implement all five principles and provide some important benefits for developers.
Q.2: Where are SOLID principles used?
Answer: It can be applied to software components, microservices, and classes. Utilising this principle, the code becomes easier to maintain and test; it makes software simpler to implement, and it helps to ward off unexpected side effects of future changes.
Q.3: Why do we use SOLID principles in C#?
Answer: The SOLID Design Principles in C# are the design principles that enable us to resolve most of the software design problems.
Q.4: What are the advantages of SOLID principles?
Answer: It can be applied to software components, microservices, and classes. Utilizing this principle, the code becomes easier to maintain and test; it makes software simpler to implement, and it helps to ward off unexpected side effects of future changes.


