

For those who have been following the news, you might know that the open-source startup Apache Hadoop has finally become an available technology. It has been a long journey, but we’re now at a point where we can all enjoy the benefits of being able to build more productive data centres with less hardware and software. If you are still struggling to see how building your own data centre stacks up against purchasing hardware from big vendors like Dell or HP, keep reading. There are many advantages to owning your own hardware, especially when it comes to implementing a robust Hadoop architecture. You get to choose from a variety of different platforms and storage architectures. You also get to pick the most optimized formula for running your workloads. In this article, you will learn about the major components of an effective Hadoop architecture as well as how to best balance cost, performance and scalability in order to achieve greater success with your own data centres.
History of Hadoop
Hadoop is a software framework for data processing. It was developed by Google in the late 2002s and was first released in 2009. It was designed to be an open-source alternative to the proprietary Hadoop software used by companies like Yahoo and Facebook. Hadoop is used to store and process large amounts of data, such as data from websites, social media, and sensors. It is also used to analyze large datasets. Hadoop is designed to be scalable and flexible. This allows it to be used in a variety of different environments, including large-scale data centres and online services. Hadoop was originally developed as a way to store and process large amounts of data. However, it has since been adapted to be used for a variety of other purposes, including analysis and storage.

What is Hadoop?
Hadoop is a software framework that allows you to store and analyze large amounts of data. It was originally developed by Google to help them analyze large datasets and make sense of them. Today, it is used by many different companies to store, process, and analyze data. Hadoop is a great tool for data scientists because it lets you store and analyze large amounts of data in a secure and efficient way. It can also be used by companies to store and analyze their data in a way that is more efficient than traditional methods. Hadoop is a software framework that allows you to store and analyze large amounts of data. It was originally developed by Google to help them analyze large datasets and make sense of them. Today, it is used by many different companies to store, process, and analyze data.
Components of Hadoop
The diagram illustrates remove how Hadoop how it interacts with the other ecosystem components.
- HDFS: This large-scale storage solution has become essential in today’s highly distributed data centres. Google’s GFS is a fully-featured file system that delivers performance that is up to four times faster than HDFS. Google’s HDFS is a popular open-source solution for Hadoop file storage. It is scalable, optimized for high volumes of read-intensive data, and includes built-in analytics to track usage and plan for future growth. Google’s approach to data management with its GFS has resulted in a storage solution that is easy to scale and can process large amounts of distributed data rapidly. It is an attractive solution for large-scale data analysis and processing.
- Yarn: The Resource Scheduler is responsible for determining who gets what resources at what time. It might be responsible for determining who gets which resources at which time, or it might be responsible for determining when resources are available for use. Mutual back-off might be used to determine who will get what resources and when. There are many variations on this theme.
- Map Reduce: Map reduce is a data processing technique that has become increasingly popular in recent years. It is a form of parallel computing that allows you to perform large-scale, repetitive tasks on large datasets in a way that is efficient and effective. In a map-reduce system, each task is given a set of input data and a set of output data. The task is then asked to combine the input data with the output data to produce new data. The end result is then stored in a database, which can be queried by other applications to retrieve the required information. Map-reduce systems are particularly useful for tasks such as data mining, data analysis, and machine learning.
- Hadoop Common: Hadoop is a highly scalable, open-source, distributed computing platform that allows you to store and process large amounts of data. It is used to store and analyze data from a variety of sources, including databases, web servers, and file systems. Hadoop is designed to be scalable by distributing the processing of data across a large number of computers. It also allows you to store and analyze data in a way that is faster than traditional methods. Hadoop is used to store and analyze data from a variety of sources, including databases, web servers, and file systems. It is designed to be scalable by distributing the processing of data across a large number of computers. It also allows you to store and analyze data in a way that is faster than traditional methods.
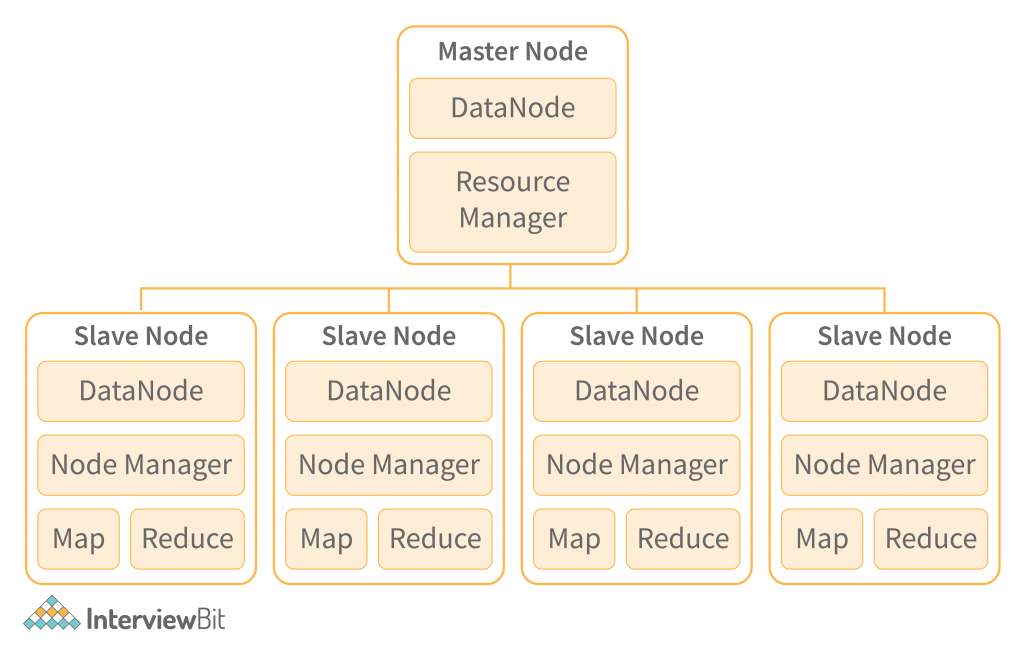
Hadoop Architecture
Hadoop is a highly scalable, open-source, distributed computing platform that allows you to store and process large amounts of data. It is used to store and analyze data from a variety of sources, including databases, web servers, and file systems. Hadoop is designed to be scalable by distributing the processing of data across a large number of computers. It also allows you to store and analyze data in a way that is faster than traditional methods. Hadoop is used to store and analyze data from a variety of sources, including databases, web servers, and file systems. It is designed to be scalable by distributing the processing of data across a large number of computers. It also allows you to store and analyze data in a way that is faster than traditional methods.
1. HDFS
The master node keeps track of the status of all the data nodes. If a data node goes down, the master node takes over the processing of that block. The slave nodes process the data on their own. HDFS requires a high-speed Internet connection. It is usually best to have at least a 10 Mbps network connection. HDFS works on a time-based algorithm, which means that every block is processed in a predetermined time interval. This provides a high degree of scalability as all the nodes process the data in real time. HDFS is a great solution for data warehouse and business intelligence tasks. It is also a good solution for high-volume, high-frequency data analysis.
i) NameNode and DataNode:
When a client connection is received from a master server, the NameNode running on the master server looks into both the local namespace and the master server’s namespace to find the matching records. The NameNode running on the master server then executes the lookup and returns a list of records that match the query. DataNodes then get the records and start storing them. A data block is a record of data. Data nodes use the data blocks to store different types of data, such as text, images, videos, etc. NameNode maintains data node connections with clients based on the replication status of DataNodes. If a DataNode goes down, the client can still communicate with the NameNode. The client then gets the latest list of data blocks from the NameNode and communicates with the DataNode that has the newest data block.

Thus, DataNode is a compute-intensive task. It is therefore recommended to use the smallest possible DataNode. As DataNode stores data, it is recommended to choose a node that is close to the centre of the data. In a distributed system, all the nodes have to run the same version of Java, so it is recommended to use open-source Java. If there are multiple DataNodes, then they are expected to work in tandem to achieve a certain level of performance.
ii) Block in HDFS
A file stored in Hadoop has the default 128 MB or 256 MB block size.


We have to ensure that the storage consumed by our application doesn’t exceed the level of data storage. If the storage consumed by our application is too much, then we have to choose our block size to avoid excessive metadata growth. If you are using a standard block size of 16KB, then you are good to go. You won’t even have to think about it. Our HDFS block size will be chosen automatically. However, if we are using a large block size, then we have to think about the metadata explosion. We can either keep the metadata as small as possible or keep it as large as possible. HDFS has the option of keeping the metadata as large as possible.
iii) Replication Management
When a node fails, the data stored on it is copied to another healthy node. This process is known as “replication”. If a DataNode fails, the data stored on it is not lost. It is simply stored on another DataNode. This is a good thing because it helps in the high availability of data. When you are using a DataNode as the primary storage for your data, you must keep in mind that it is a highly-available resource. If the primary storage for your data is a DataNode, you must make sure to have a proper backup and restoration mechanism in place.

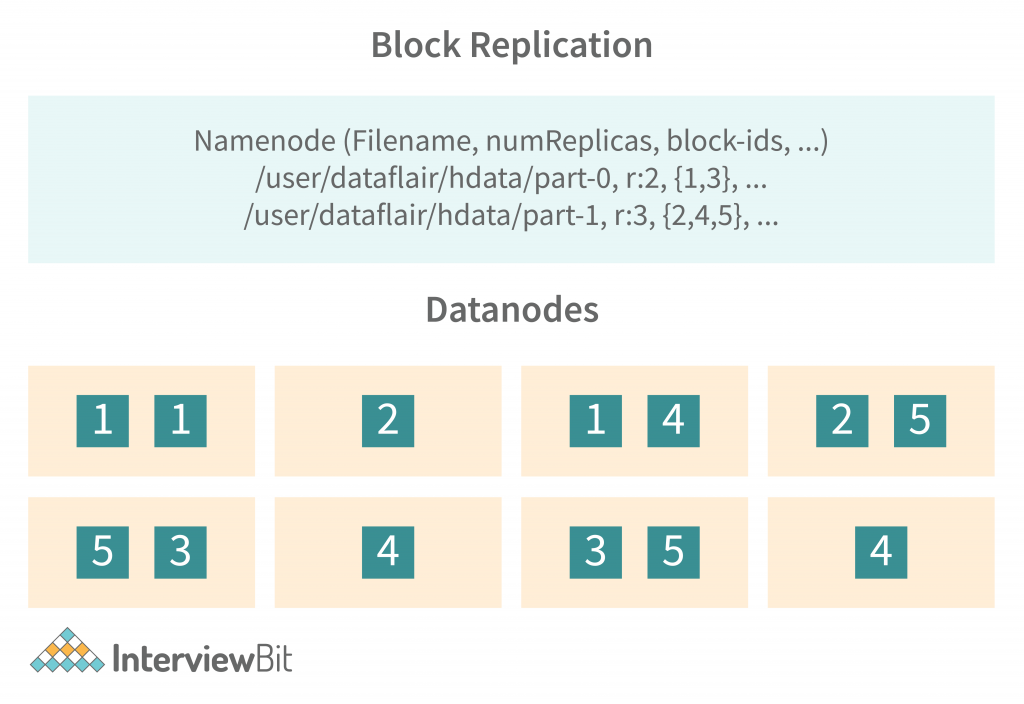
A given file can have a replication factor of 3 or 1, but it will require 3 times the storage if we keep using a replication factor of 3. The NameNode keeps track of each data node’s block report and whenever a block is under-or over-replicated, it adds or removes replicas accordingly.
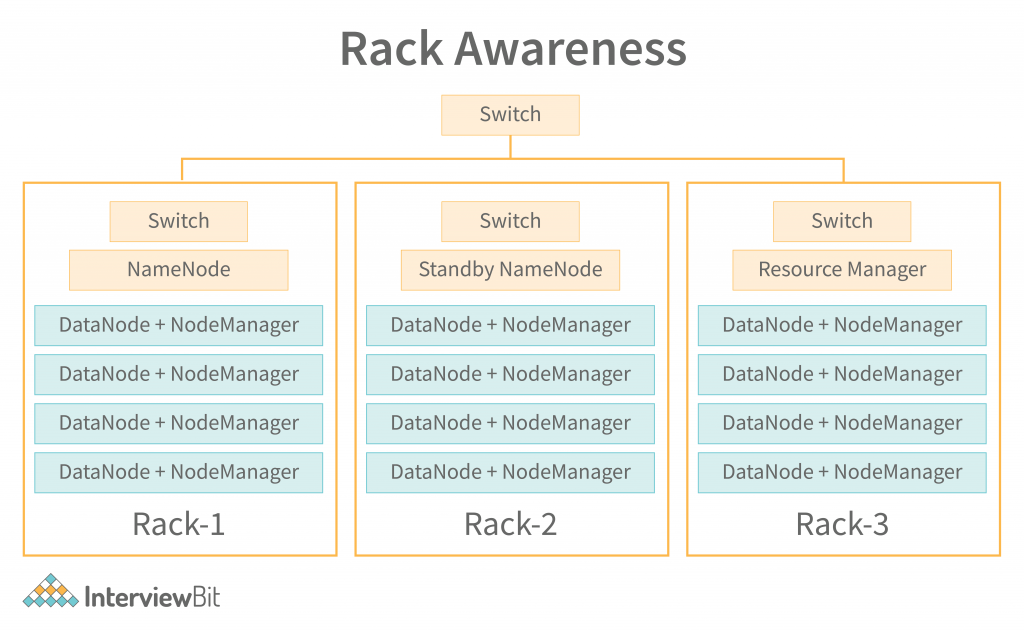
iv) Rack Awareness
When a block is deleted from a rack, the next available block will be placed on the rack. When a block is updated, the previous block is automatically updated in the same rack. This ensures data consistency across the storage network. In case of a fault in any of the data storage nodes, other storage nodes can be alerted through the rack awareness algorithm to take over the responsibility of the failed node. This helps in providing failover capability across the storage network. This helps in providing high availability of data storage. As data stored in HDFS is massive, it makes sense to use multiple storage nodes for high-speed data access. HDFS uses a distributed data store architecture to provide high-speed data access to its users. This distributed data store architecture allows for parallel processing of data in multiple data nodes. This parallel processing of data allows for high-speed storage of large data sets.

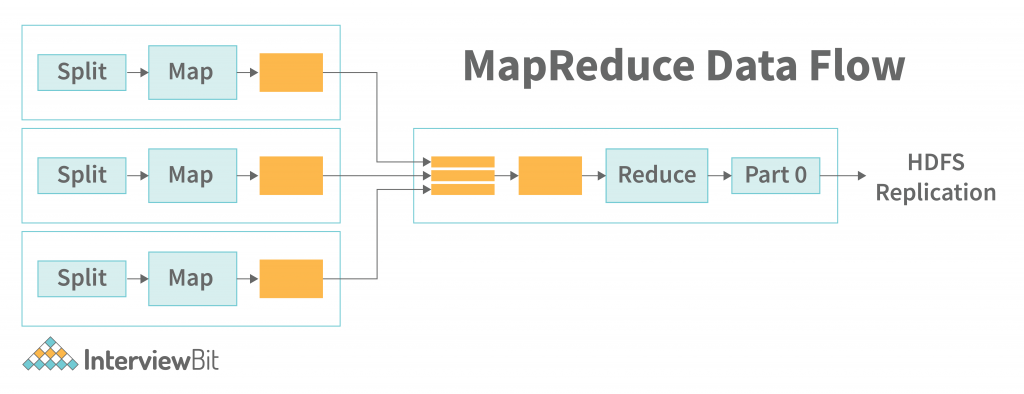
2. MapReduce
MapReduce is a data processing language and software framework that allows you to process large amounts of data in a reliable and efficient manner. It is a great fit for data-intensive, real-time and/or streaming applications. Basically, MapReduce allows you to partition your data and process items only when they are needed.
A map-reduce job consists of several maps and reduces functions. Each map function generates, parses, transforms, and filters data before passing it on to the next function. The reduced function groups, aggregates, and partitioning of this intermediate data from the map functions. The map task runs on the same node as the input source. Map tasks are responsible for generating summary statistics about data in the form of a report. The report can be viewed on a web browser or printed.
The output of a map task is the same as that of a reduced task. The only difference is that the map task returns a result whereas the reduced task returns a data structure that is applicable for further analysis. A map task is usually repetitive and is triggered when the data volume on the source is greater than the volume of data that can be processed in a short period of time.

3. Yarn
YARN, also known as Yet Another Resource Negotiator, is a resource management and job scheduling/monitoring daemon in Hadoop. A resource manager in YARN isolates resource management from job scheduling and monitoring. A global Resource Manager oversees operations for the entire YARN network, including per-application ApplicationMaster. A job or a DAG of jobs may be defined as an application. The Resource Manager manages resources for all the competing applications in the YARN framework. The NodeManager monitors resource usage by the container and passes it on to ResourceManger. There are resources such as CPU, memory, disk, and connectivity, among others. To perform and monitor the application, the ApplcationMaster talks to the ResourceManager and the NodeManager to handle and manage resources.


Advantages of Hadoop Architecture
- The huge data sets that Hadoop can store and distribute across hundreds of inexpensive servers are also capable of processing a great deal of data. Unlike RDBMSs which can’t function as a scaling storage platform, Hadoop enables businesses to run applications on thousands of nodes where many thousands of terabytes of data are being processed.
- A company’s exploding data sets are a costly headache in traditional relational database management systems. This is because computing such enormous quantities of data is extremely costly. To cut costs, some companies have pasted data down-sample as they wished, assuming that certain types of data were more important than others. This procedure could have worked in the short term, but it might have destroyed the entire raw data set as it was too costly to keep.
- A single data source (such as social media) can be accessed by a business using Hadoop, providing access to a large variety of data types (structured and unstructured). Businesses can use Hadoop to gain new business insights from data sources such as social media, and email communications. Hadoop can be used for a range of purposes, from log processing to data warehousing to fraud detection, among others.
- Hadoop’s distributed file system “maps” data wherever it is located on a cluster, therefore reducing storage costs. It also makes data processing quicker because the tools for data processing are often on the same servers where the data is located. Big volumes of unstructured data can be processed effectively using Hadoop in minutes or hours, depending on how much data is involved.
- Hadoop’s fault tolerance is a significant advantage. When data is transferred to individual nodes in the cluster, it is also duplicated to other nodes in the event of failure, so that when the node is down, there is another copy available to use.
Disadvantages of Hadoop Architecture
- A complex Hadoop application like security is hard to manage. Hardly any straightforward example can be found in the security model. If anyone is incapable of enabling it, your data may be at risk. Hadoop is also lacking encryption at the storage and network levels, despite its popularity as a government surveillance tool.
- The very nature of Hadoop makes it a risky endeavour to run it. Because of Java’s widespread use and continued controversy, it has been extensively abused by cybercriminals and other miscreants.
- Big data is not primarily used by big corporations, however small data platforms such as Hadoop are not equipped for it. The Hadoop Distributed File System, because of its capacity, is unable to efficiently handle small files. For example, small quantities of data cannot be stored in the Hadoop Distributed File System.
- It is important for organizations to ensure that they are running the latest stable version of Hadoop or that they use a third-party vendor that can deal with issues like these.
- A possible solution is described in the article. Each of these platforms can improve the efficiency and reliability of data collection, aggregation, and integration by adding value to it. The main idea is that companies could be missing out on big benefits by using Hadoop alone.
Conclusion
Hadoop is a software framework for data processing. It is designed to be scalable, flexible, and easy to use. It is used to store and process large amounts of data, such as from databases, web services, and batch files. Hadoop is used in a variety of applications, including data warehousing, Big Data analytics, and cloud computing.
Hadoop has several components that work together to process data. The core component is the MapReduce framework. This framework allows for data processing by dividing tasks into small pieces and then recombining them into larger tasks. Hadoop also uses a distributed file system called HDFS to store data. HDFS allows for large amounts of data to be stored efficiently on multiple machines. Hadoop is designed to be easy to use and flexible. It can be used in a variety of environments, including the cloud, on-premise installations, and in the data centre.


