
A data warehouse is a database or data store that is optimized for analytical queries, and is a subject-oriented distributed database. It is used to store data that is gathered from different sources, cleansed, and structured for analysis. This includes large volumes of structured, semi-structured, and unstructured data that have been collected from multiple sources such as mobile phones, click-streams, social media, and sensor data (such as RFID and GPS) that can be analyzed to reveal patterns and trends. Data warehouses are used in different business domains such as healthcare, retail, financial sectors, telecommunications, etc. It is also used within large organizations to analyze the information stored in databases, generating insights and recommendations to achieve better business performance.
The Trend for Data Warehouse
Data warehousing, a concept that has been around for more than 2 decades, is a critical part of any company’s business intelligence strategy. With the growing importance of data, the data warehouse market has seen tremendous growth in the last 5 years. The data warehouse market size is projected to reach $26.50 Billion by 2022, at a CAGR of 15.3% during the forecast period 2016–2022. Data warehousing methods will evolve with the coexisting technology trends in the coming years. Here are a few expected trends for a data warehouse in 2022:
- Pay attention to the analysis of unstructured data such as video files, seismic images, audio data, permissible user data, etc. This data can help unlock valuable insights and train machine learning systems to be more efficient.
- Right Data Analytics will take over Big Data analytics. Experts are working on solutions to find precise data in place irrespective of its origin.
- Multi-cloud strategies will solve storage-related issues, and help expand the existing data warehouses.
- Using synthetic data to prevent data privacy issues and generate data for analytics at the same time. Synthetic data is artificially generated information by a statistical model, without revealing any real-world information.
Uses of Data Warehouse
Data warehouses can be used in the following ways:
Confused about your next job?
- Tactical Reporting – data from the warehouses can be converted into reports and used by companies as a proof statement while pitching about their products or services. For example, talking about high placement rates due to services that help crack technical interviews attracts more students and helps build trust and brand labels.
- Data validation – to cross-check new data with existing data in the warehouses, to confirm that the information is true. For example, the bank data warehouse contains data that says customers who pay their interest on time for 6 months are loyalty customers. When a new customer has fulfilled the criteria just then, their data is compared with the existing information for validation.
- Information exploration – to search for ideas, knowledge, or even a new perspective by exploring the data; eg data mining techniques.
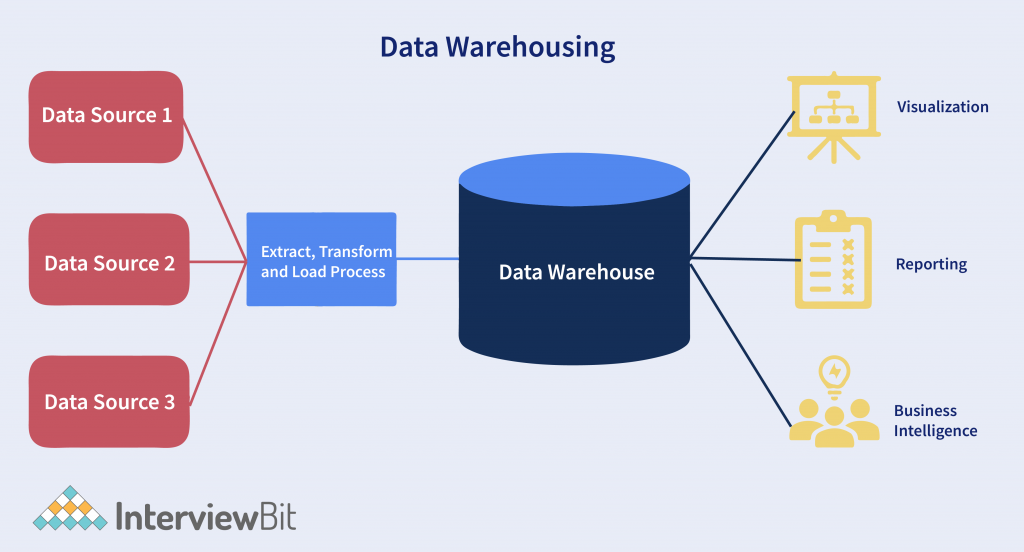
To stay on par with the Big Data technologies that transform the way we store, interpret and use data, we need to understand the characteristics of Data warehouses. Understanding the characteristics of data warehouses enables us to put our data to valuable use and boost the performance of our businesses. Without further ado, let’s delve into the blog!
Top Characteristics of Data Warehouse
Here are a few characteristics of data warehouses:
A Data Warehouse is Subject-Oriented
A data warehouse provides information on the topic rather than the current operations of organizations. It is subject-oriented and does not mainly concentrate on ongoing processes. A data warehouse aids in creating emphasized models and analytical reports. This is in turn used in decision-making processes. It provides a brief description of the concerned subject and filters all information that does not contribute to the decision-making processes.
Subject-oriented data warehouse (SODW) is a type of data warehouse that is designed to support complex event processing (CEP) and similar applications. The subject-oriented data warehouse is designed to deliver information based on user-defined topics. The information in a subject-oriented data warehouse is structured based on user-defined topics, where a topic is a set of related data that is of interest to a specific business user. This is in contrast to a traditional data warehouse which is designed to support online analytical processing (OLAP) queries.
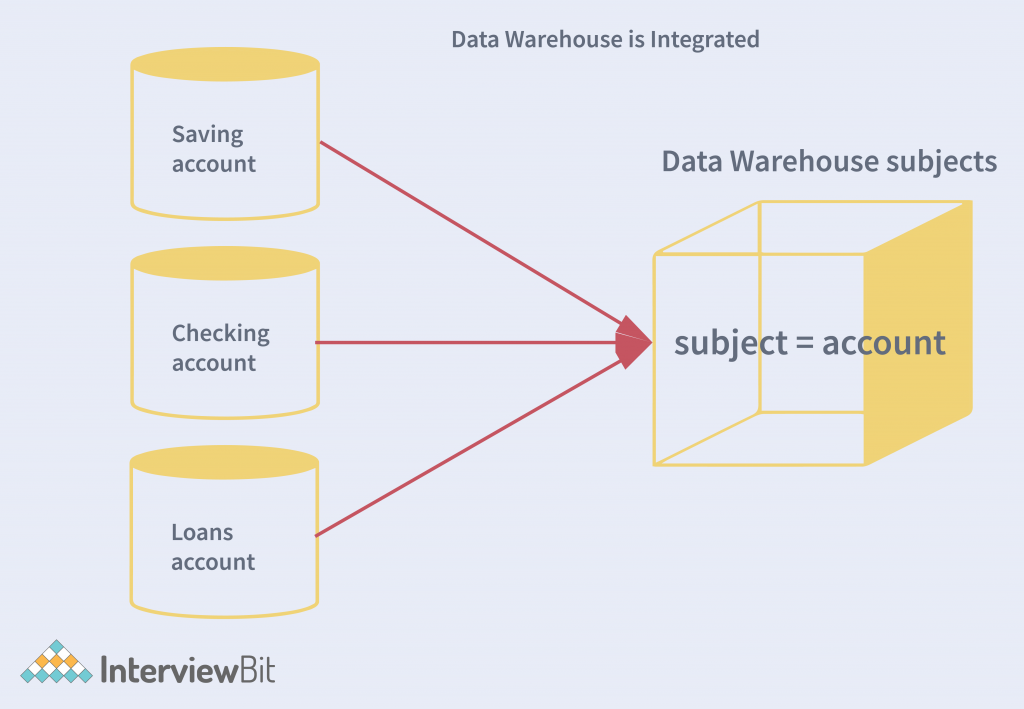
To provide information, data cubes are created from a subset of the attributes in the datasets in the warehouse. A cube is a schema used to store and analyze data from a data warehouse. It is also in contrast to a star schema which is a cube where the dimension tables are connected to the fact table through a single table.
Let us understand this with an example. A company wants to learn more about its sales data. To support their needs a data warehouse that concentrates on sales is built. The architecture of the data warehouse is trained to gather sales-related information such as the company’s revenue growth, products that sold more or less than others, industrial comparisons, number of regular customers, etc. Using this data warehouse, the company can derive insights about the best customers of the month, the product that was highly sold in a month, etc.
Data Warehouses Support Integration
Integration goes hand in hand with the previous characteristics; subject orientation. A data warehouse is capable of combining data from various sources such as a mainframe, relational databases, flat files, etc.
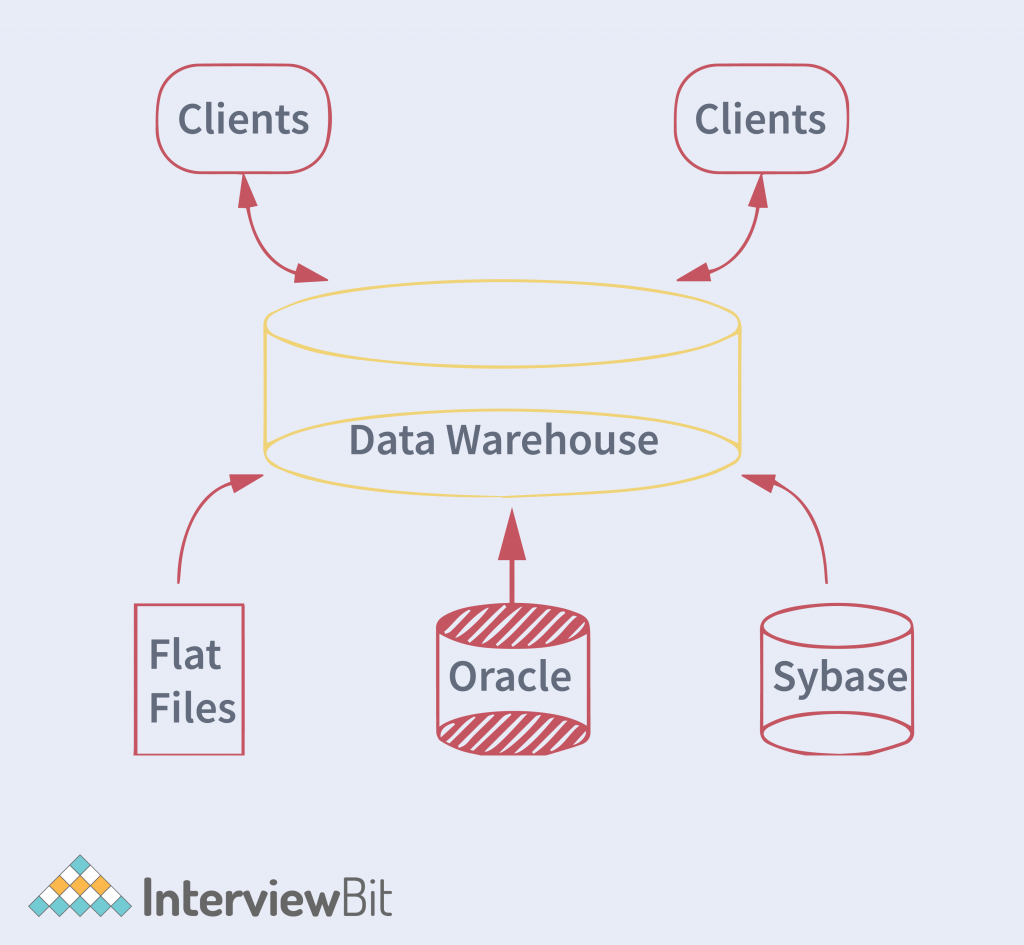
These warehouses are designed to store and organize data from both transactional and analytical data sources of various types. A data warehouse is typically built for and by the business users in an organization. These users are usually more concerned with how data is used rather than how it is stored. An integrated data warehouse is a central place for reporting, analysis, and business intelligence. This involves a multidimensional data model and a metadata repository. It is also called an enterprise data warehouse or knowledge data warehouse.
The data warehouse adopts a variety of data integration techniques including;
- ETL (Extract Transform and Load): data from different sources are gathered, transformed, and loaded into the warehouse.
- ELT( Extract Load and Transform): data is first loaded as it is into the big data system and transformed later for specific analytical use cases.
- Data-capture changes: identifies real-time changes in the databases and updates them to the data warehouse.
- Data Replication: data in one database is replicated to others to ensure that the information is not lost if any disaster occurs.
- Data virtualization: data from the different systems are combined virtually to create a unified view at a single warehouse. For example, a sales-related data warehouse combines customer purchase details and product information in one place, instead of two separate windows.
The data warehouse resolves issues like naming conflicts and inconsistencies among units of measurement. The naming conventions, format, coding, measurements, encoding specifications, etc must be consistent throughout the data warehouse. A standard unit of measurement from the different databases for all the similar data is established. This helps in identifying various aspects of the data at-hand quicker. These features of the data warehouse support robust data analysis.
The integrated data warehouse has two benefits. The first benefit is that it eliminates data redundancy by having one version of the truth across the enterprise. The second benefit is that it allows for ad hoc reporting.
Let us understand the benefits with an example. An e-commerce company X provides a mobile app to its users. It uses Google ads and Facebook Ads to acquire new users. The company now wants to increase its advertising budget, but they are unsure whether to spend more on Facebook Ads or Google Ads. They need to know the types of users they have acquired through both channels to make an informed decision. When the user acquisition data via these channels are synchronized in a data warehouse, it helps the company to analyze and compare both the channels using BI tools, and come up with relevant strategies.
Data Warehouses are Non-Volatile
Data is a company’s wealth as it can be manipulated in several ways to gain insights on many aspects. We never know when a dataset that is ignored and deleted would come in handy for a crucial analytics report. To support this cause, data warehouses are non-volatile, which means that any prior data will not be erased upon the entry of new data in the warehouse. This is done by omitting functions of an operational application environment such as deleting, updating, and inserting.
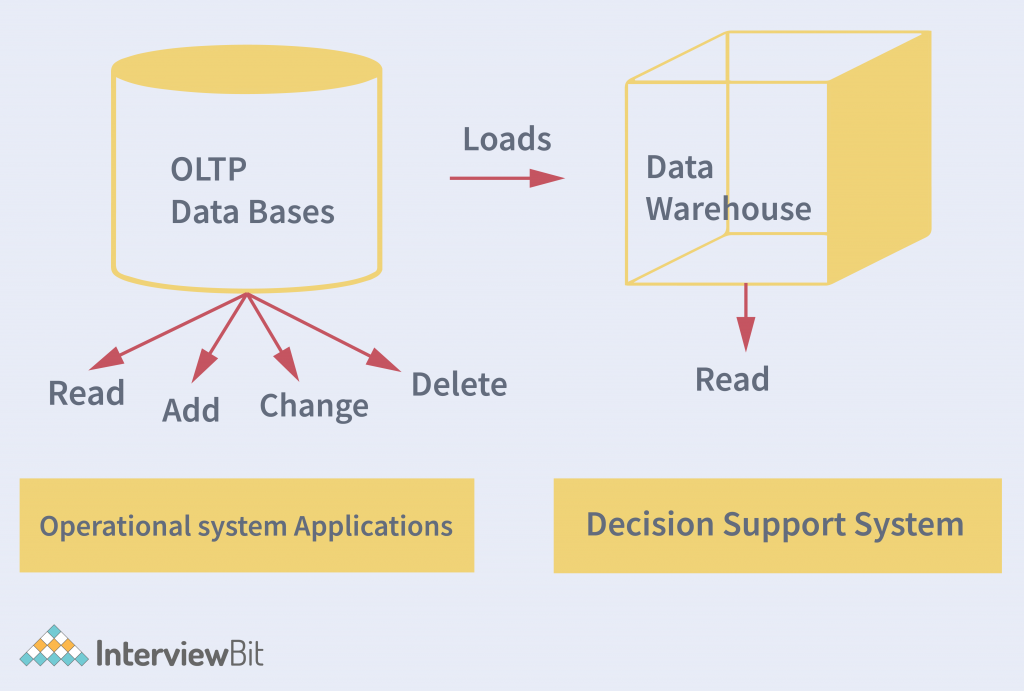
As a result, transaction process, recovery, and competitiveness control mechanisms are not strictly needed.
Data in a data warehouse is subject to the same standards of quality and consistency as data used in the business. Generally, data in a data warehouse is more current and more accurate than data in operational systems. Data warehouses can be used for historical, current, and predictive analysis. They are also well suited for ad hoc queries and applications that perform real-time analytics.
Let us understand the benefits with an example. A retail company Y wants to find out their revenue growth for the past 2 years. With the help of non-volatile data warehouses, they can pull the data directly from their warehouses, instead of going through multiple random accounting files.
Data in Warehouses are Predictable with Time Intervals
In the previous characteristics of data warehouses, we read that all data is to be retained for better analytical purposes, but wouldn’t it bombard the system? To answer this question, data warehouses have another special feature. The data in a warehouse is maintained via different intervals of time such as hourly, weekly, monthly, annually, etc.
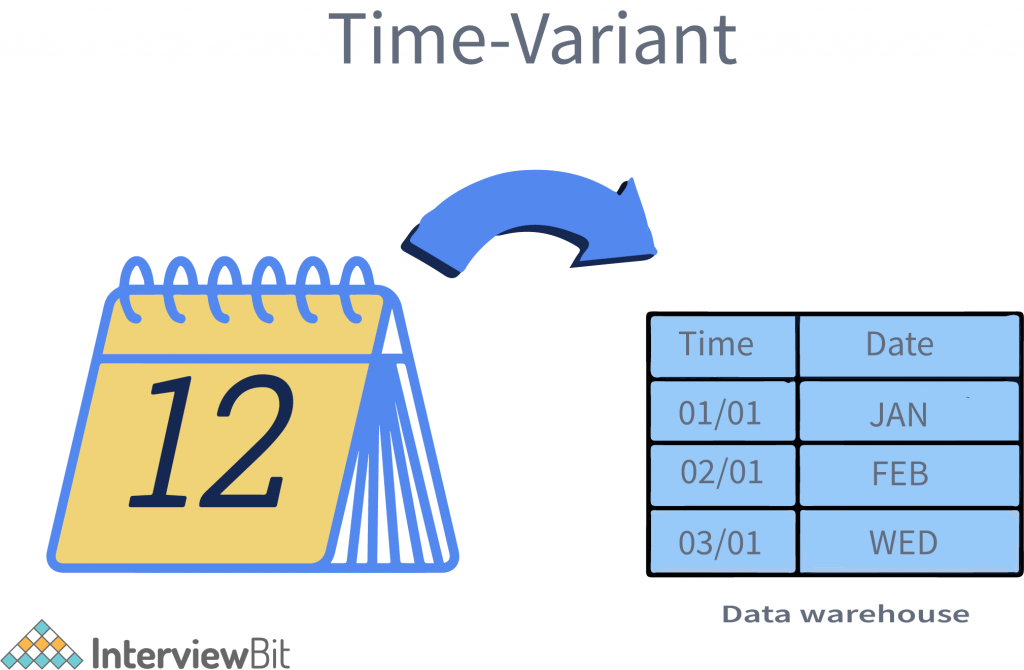
In comparison to operational systems supporting OLTP(online transaction processes), time limits for data warehouses are wide-ranging. The data comprises elements of time either implicitly or explicitly, thus supporting the non-volatility features of data warehouses.
We need to remember that a time-variant data warehouse is a data warehouse that changes with time. The data in the warehouse is transformed as frequently as possible so that the existing data is a true reflection of current business transactions. The original data is retained, but the way the data transformation is carried out is based on the current needs.
Conclusion
To summarize, a data warehouse is a database system that you can use for analysis. It is typically created by taking a copy of the source data tables and removing any unwanted columns or rows. You can then create queries and reports that analyze the data in the copy. A data warehouse is a good platform for reporting because of its consistent data, speed, and size. With this information, you can answer a few questions asked in your next data science job interview! To learn more, pick any Fast-Track courses provided by InterviewBit.
InterviewBit helps you crack interviews by providing you with the latest content on technology, data science, and machine learning. We’re always excited to answer your questions and get you on your way to landing your dream job. If you have any topics you would like us to cover, or any feedback for us, please don’t hesitate to contact us. Thank you for reading and we hope you enjoyed this post!
FAQs
Q: What are the components of a data warehouse?
A: The following are the components of a data warehouse:
- Central database
- ETL tools
- Metadata tools
- Access tools
Q: What are the types of data warehouses?
A: There are three main types of data warehouses:
- Enterprise data warehouse(EDW)
- Virtual data warehouse
- Datamart
Q: What is the purpose of a data warehouse?
A: Data warehouses are database management systems designed to enable and support Business Intelligence (BI) activities. They perform queries, analyses, and retain large volumes of historical data.
Q: What are the benefits of data warehouses?
- Improves Business Intelligence
- Increases data security
- Improves data standardization and quality
- Saves time
Q: Name a few popular data warehouses.
A: Amazon Redshift, Snowflake, IBM Db2, BigQuery, Microsoft, Databricks Lakehouse platform, Vertica, Dremio, etc are a few popular data warehouses.

