People are getting more fascinated with Artificial Intelligence, Machine Learning, and Deep Learning in the current world. These fields have been using a wide range of techniques and algorithms to give humans the best results. If you specifically consider deep learning, it uses neural networks to mimic the human brain. Several kinds of neural networks are used in a wide range of applications of deep learning like image processing, image segmentation, self-driving cars, etc. One such popular neural network is CNN which stands for Convolutional Neural Network.
What is CNN?
Convolutional Neural Networks (CNN, or ConvNet) are a type of multi-layer neural network that is meant to discern visual patterns from pixel images. In CNN, ‘convolution’ is referred to as the mathematical function. It’s a type of linear operation in which you can multiply two functions to create a third function that expresses how one function’s shape can be changed by the other. In simple terms, two images that are represented in the form of two matrices, are multiplied to provide an output that is used to extract information from the image. CNN is similar to other neural networks, but because they use a sequence of convolutional layers, they add a layer of complexity to the equation. CNN cannot function without convolutional layers.
In a variety of computer vision tasks, CNN artificial neural networks have risen to the top. It has picked people’s interest in a variety of fields.
A convolutional neural network is made up of numerous layers, such as convolution layers, pooling layers, and fully connected layers, and it uses a backpropagation algorithm to learn spatial hierarchies of data automatically and adaptively. You will learn more about these terms in the following section.
Confused about your next job?
Typical CNN Architecture
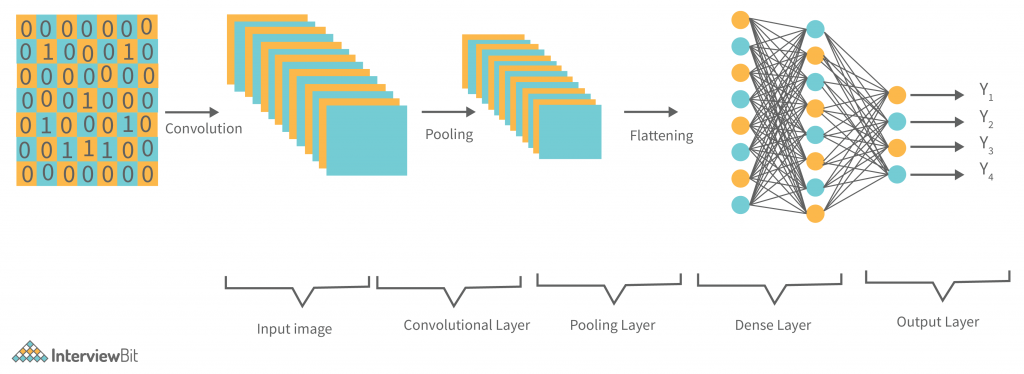
The ConvNet’s job is to compress the images into a format that is easier to process while preserving elements that are important for obtaining a decent prediction. This is critical for designing an architecture that is capable of learning features while also being scalable to large datasets.
A convolutional neural network, ConvNets in short has three layers which are its building blocks, let’s have a look:
Convolutional Layer (CONV): They are the foundation of CNN, and they are in charge of executing convolution operations. The Kernel/Filter is the component in this layer that performs the convolution operation (matrix). Until the complete image is scanned, the kernel makes horizontal and vertical adjustments dependent on the stride rate. The kernel is less in size than a picture, but it has more depth. This means that if the image has three (RGB) channels, the kernel height and width will be modest spatially, but the depth will span all three.
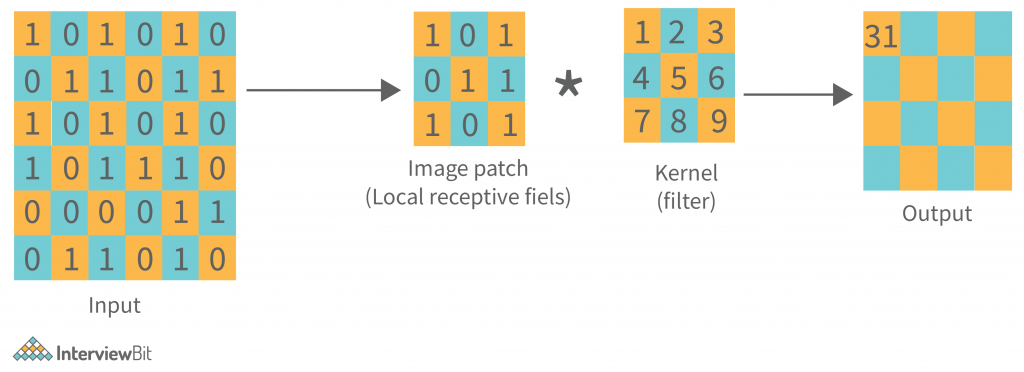
Other than convolution, there is another important part of convolutional layers, known as the Non-linear activation function. The outputs of the linear operations like convolution are passed through a non-linear activation function. Although smooth nonlinear functions such as the sigmoid or hyperbolic tangent (tanh) function were formerly utilized because they are mathematical representations of biological neuron actions. The rectified linear unit (ReLU) is now the most commonly used non-linear activation function. f(x) = max(0, x)
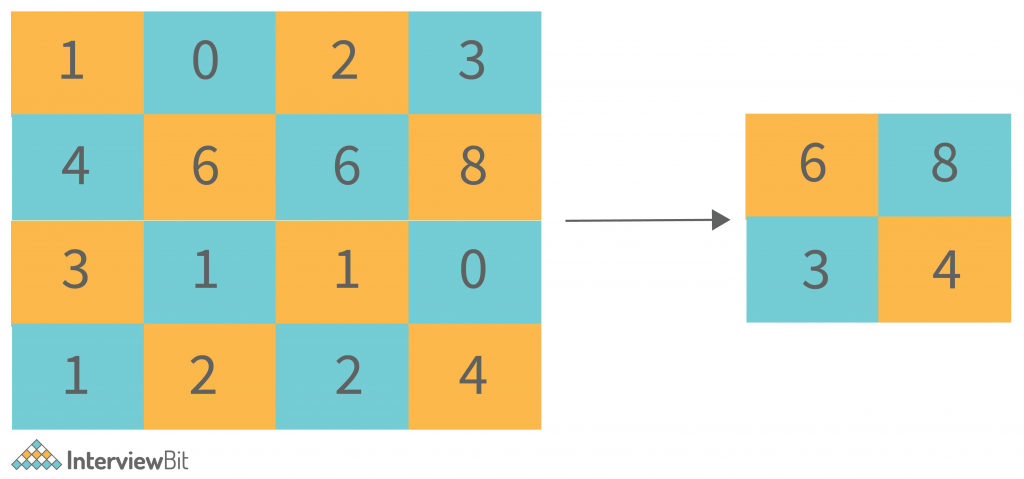
Pooling Layer (POOL): This layer is in charge of reducing dimensionality. It aids in reducing the amount of computing power required to process the data. Pooling can be divided into two types: maximum pooling and average pooling. The maximum value from the area covered by the kernel on the image is returned by max pooling. The average of all the values in the part of the image covered by the kernel is returned by average pooling.
Fully Connected Layer (FC): The fully connected layer (FC) works with a flattened input, which means that each input is coupled to every neuron. After that, the flattened vector is sent via a few additional FC layers, where the mathematical functional operations are normally performed. The classification procedure gets started at this point. FC layers are frequently found near the end of CNN architectures if they are present.
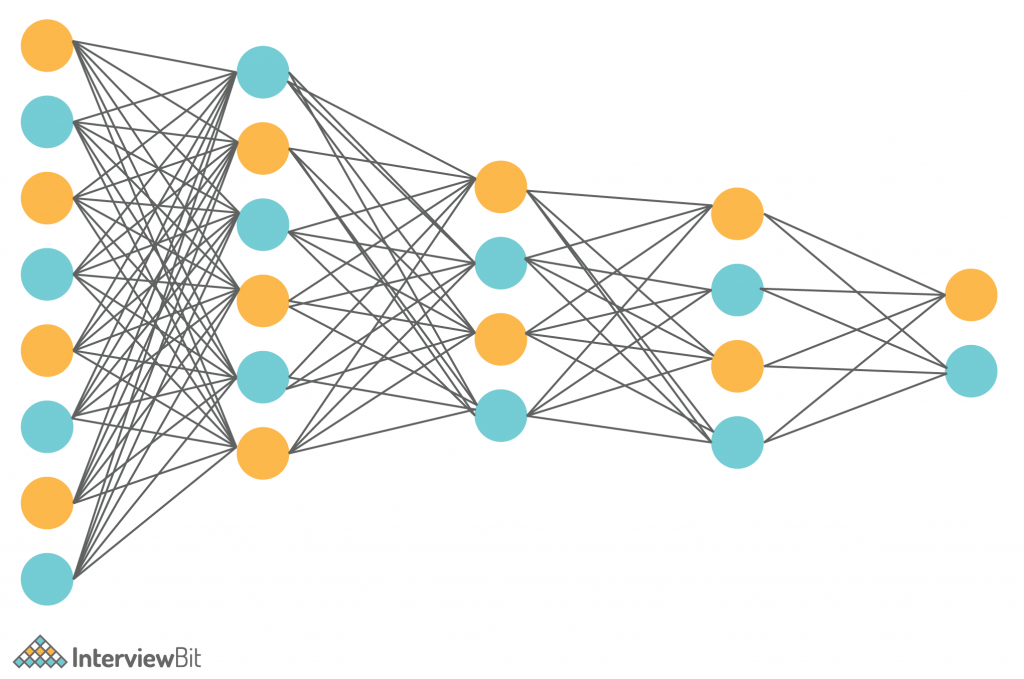
Along with the above layers, there are some additional terms that are part of a CNN architecture.
Activation Function: The last fully connected layer’s activation function is frequently distinct from the others. Each activity necessitates the selection of an appropriate activation function. The softmax function, which normalizes output real values from the last fully connected layer to target class probabilities, where each value ranges between 0 and 1 and all values total to 1, is an activation function used in the multiclass classification problem.
Dropout Layers: The Dropout layer is a mask that nullifies some neurons’ contributions to the following layer while leaving all others unchanged. A Dropout layer can be applied to the input vector, nullifying some of its properties; however, it can also be applied to a hidden layer, nullifying some hidden neurons. Dropout layers are critical in CNN training because they prevent the training data from overfitting. If they aren’t there, the first batch of training data has a disproportionately large impact on learning. As a result, learning of traits that occur only in later samples or batches would be prevented:
Now you have got a good understanding of the building blocks of CNN, let’s have a look to some of the popular CNN architecture.
LeNet Architecture
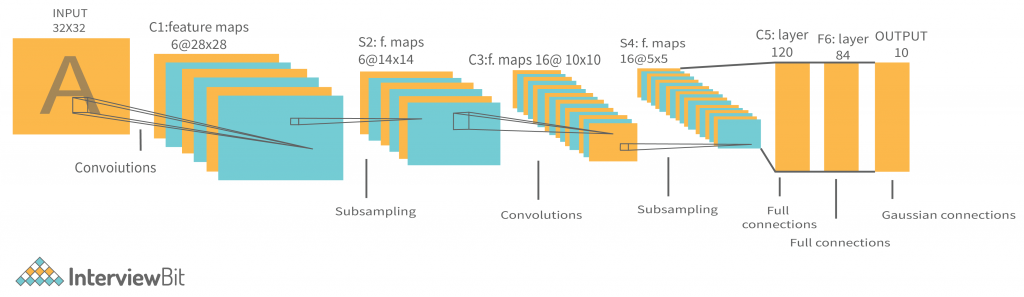
The LeNet architecture is simple and modest making it ideal for teaching the fundamentals of CNNs. It can even run on the CPU (if your system lacks a decent GPU), making it an excellent “first CNN.” It’s one of the first and most extensively used CNN designs, and it’s been used to successfully recognize handwritten digits. The LeNet-5 CNN architecture has seven layers. Three convolutional layers, two subsampling layers, and two fully linked layers make up the layer composition.
AlexNet Architecture
AlexNet’s architecture was extremely similar to LeNet’s. It was the first convolutional network to employ the graphics processing unit (GPU) to improve performance. Convolutional filters and a non-linear activation function termed ReLU are used in each convolutional layer (Rectified Linear Unit). Max pooling is done using the pooling layers. Due to the presence of fully connected layers, the input size is fixed. The AlexNet architecture was created with large-scale image datasets in mind, and it produced state-of-the-art results when it was first released. It has 60 million characteristics in all.
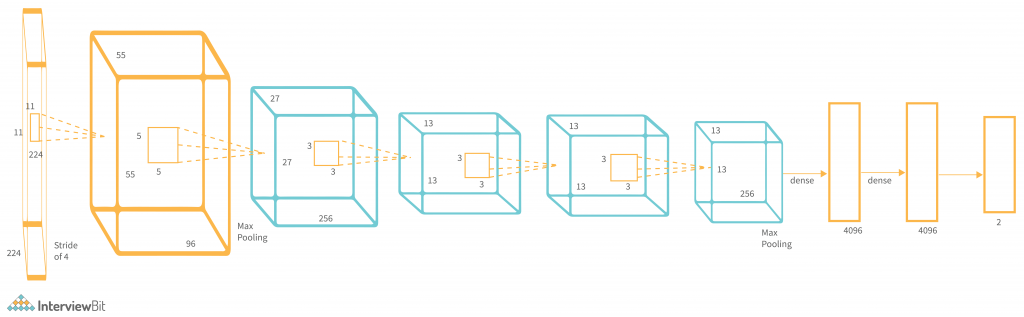
VGGNet Architecture
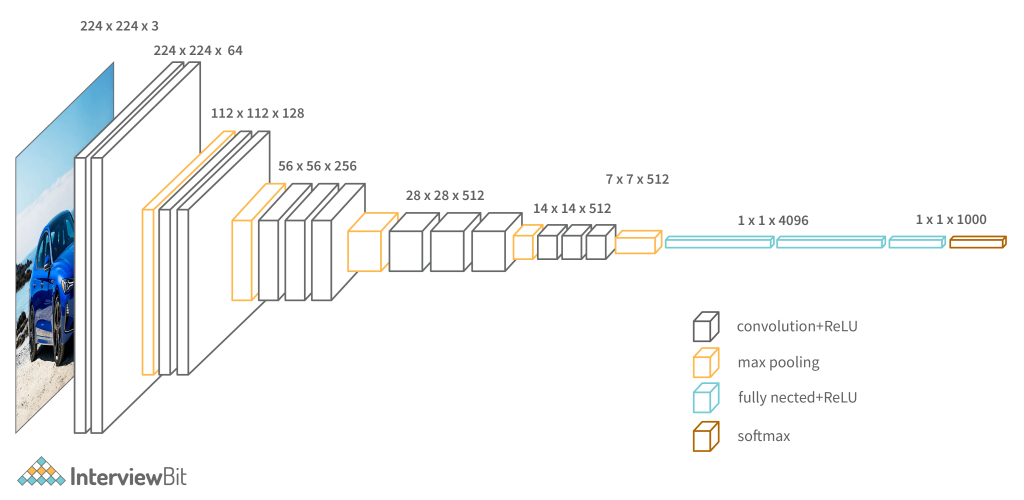
While prior AlexNet derivatives focused on smaller window sizes and strides in the first convolutional layer, VGG takes a different approach to CNN. It takes input as a 224×224 pixel RGB image. To keep the input image size consistent for the ImageNet competition, the authors clipped out the middle 224×224 patch in each image. The receptive field of the convolutional layers in VGG is quite tiny. The convolution stride is set at 1 pixel in order to preserve spatial resolution after convolution. VGG contains three completely connected layers, the first two of which each have 4096 channels and the third of which has 1000 channels, one for each class. Due to its adaptability for a variety of tasks, including object detection, the VGG CNN model is computationally economical and serves as a good baseline for many applications in computer vision.
Advantages of CNN Architecture
Following are some of the advantages of a Convolutional Neural Network:
- CNN is computationally efficient.
- It performs parameter sharing and uses special convolution and pooling algorithms. CNN models may now run on any device, making them globally appealing.
- It finds the relevant features without the need for human intervention.
- It can be utilized in a variety of industries to execute key tasks such as facial recognition, document analysis, climate comprehension, image recognition, and item identification, among others.
- By feeding your data on each level and tuning the CNN a little for a specific purpose, you can extract valuable features from an already trained CNN with its taught weights.
Conclusion
In this blog, you came across a variety of concepts that are part of the Convolutional Neural Network. Each part has its own importance and combined they make up a highly efficient and good performance neural network known as CNN. They are an essential part of deep learning applications.