Data lakes are collections of large volumes of structured data, such as RDBMS databases or structured text files. They can be public or private; internal or external; analytical or demo. In the early days, the term “data lake” was used to describe a collection of interconnected data lakes that were linked by data pipelines and data telemetry systems. Today, it is more commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make storing and processing large volumes of structured data as easy as possible. The ecosystem is made up of several key components, including software tools and processes that store data and process it; IoT (internet of things) connected devices that store, process and store data about users and products; storage system providers (hardware platforms like VMware vRealize Automation and software tools like Greenplum Realtime Report), data integrator partners (Microsoft Azure Data Lake Software Gateway), etc. With so many different players in the market today, there are many ways to create a data lake ecosystem.
What is a Data Lake?
A data lake is a data storage and analysis platform that stores and analyzes large amounts of data. Typically, data lakes are used to store, analyze, and visualize large amounts of data from different sources, such as web logs, email archives, social media feeds, and so on. The main purpose of a data lake is to store and analyze large amounts of data in a centralized location. The data lake can be created using a variety of different technologies, including databases, NoSQL databases, and cloud storage. The data lake can be used to store all of the data generated by an organization’s systems, from sales transactions to employee performance reviews. By storing all of the data in one place, the data lake allows for easy access and analysis.
When creating a data lake, it is important to keep in mind that the data lake should be used to store only the most important data. This is because the more data that is stored in a data lake, the more likely it is that it will be lost or deleted. Instead, the most important data should be stored in a separate database.
Confused about your next job?
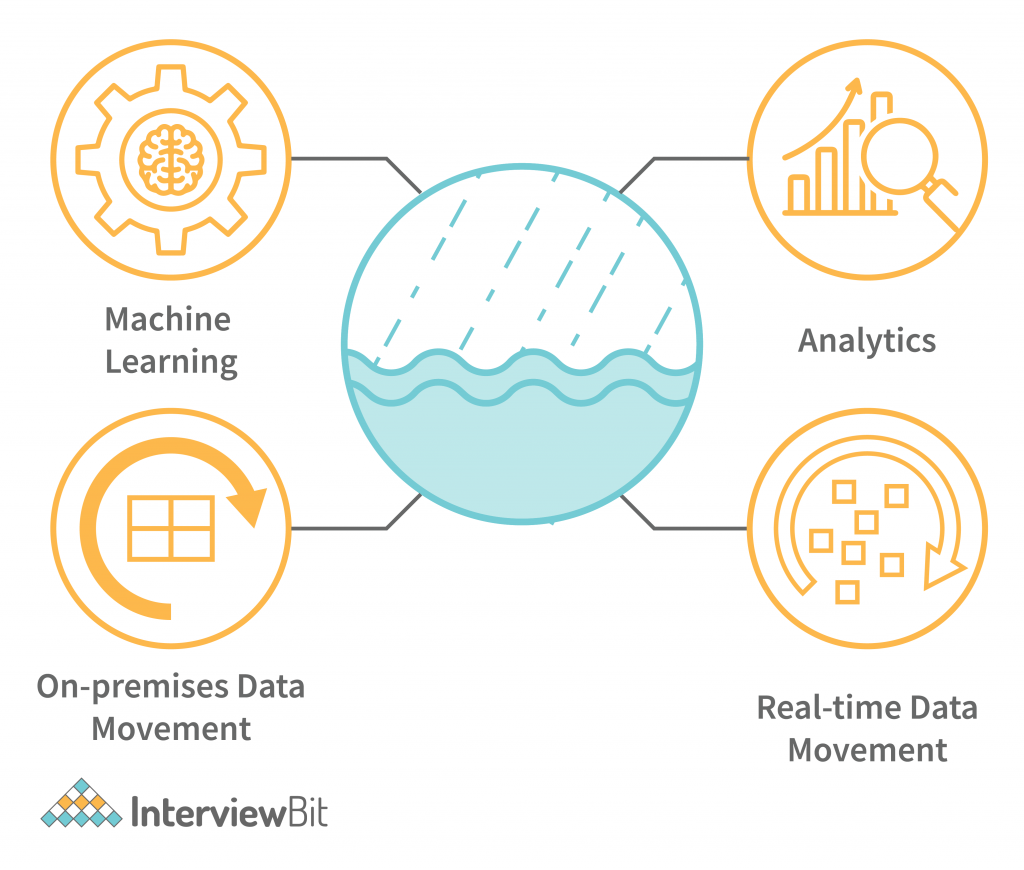
Why Data Lake?
A data lake is a data storage system that stores all of the data generated by an organization. The data lake is typically a collection of databases, but it can also include other types of data such as images, videos, and other types of files. In addition to storing all of the data generated by an organization, the data lake can also be used to analyze the data and make predictions about future trends.
The main purpose of a data lake is to store all of the data generated by an organization. This allows the organization to access all of the data at any time and make decisions based on the data. The benefits of a data lake include being able to quickly access all of the data and making decisions based on the data. Data Lake allows for large amounts of storage to store data from data sources.
The reasons listed below for constructing a Data Lake are:
- The data of the company resides in a variety of systems, including ERP platforms, CRM apps, Marketing apps, etc. It helps to organize data on these platforms. There are instances, however, when it’s necessary to combine all data into one location in order to analyze all funnel and attribution data. A data lake is a great way to create one central Data Source. Using the Data Lake Architecture, a single organization can get a holistic view of data and generate insights from it.
- Data lakes offer businesses the ability to store data and use it directly from BI tools, without having to worry about accessing transactional API drives. Businesses use enterprise platforms to run daily tasks, which provide transactional API access to the data. Data lakes allow businesses to store and use data directly from BI tools. Using ELT, you can quickly load data into Data Lake and use it with other software tools by using a flexible, reliable, and fast method.
- The performance of a particular application can be impacted by data sources that do not offer quicker query processing. The data aggregation process requires faster query speed, which is dependent on the nature of the data and the type of database. Data Lake Architecture enables fast querying by providing a data lake infrastructure that supports fast query processing. Data Lakes are quick to scale up and down, making them easier to query.
- It’s critical to have data in one place before moving on to other phases because loading data from one source makes working with BI tools easier. Data Lake makes your data cleaner and error-free, reducing the chance of data repetition.
Data Lake Architecture
The key components of a data lake architecture are shown in the diagram below. The data lake itself is the UCI. All key technologies are part of the data lake ecosystem. The ETL tools transform the data into a structured or unstructured form, the data warehouse holds the data for long-term storage, and the reasoner solves queries against the data warehouse to get the final result.
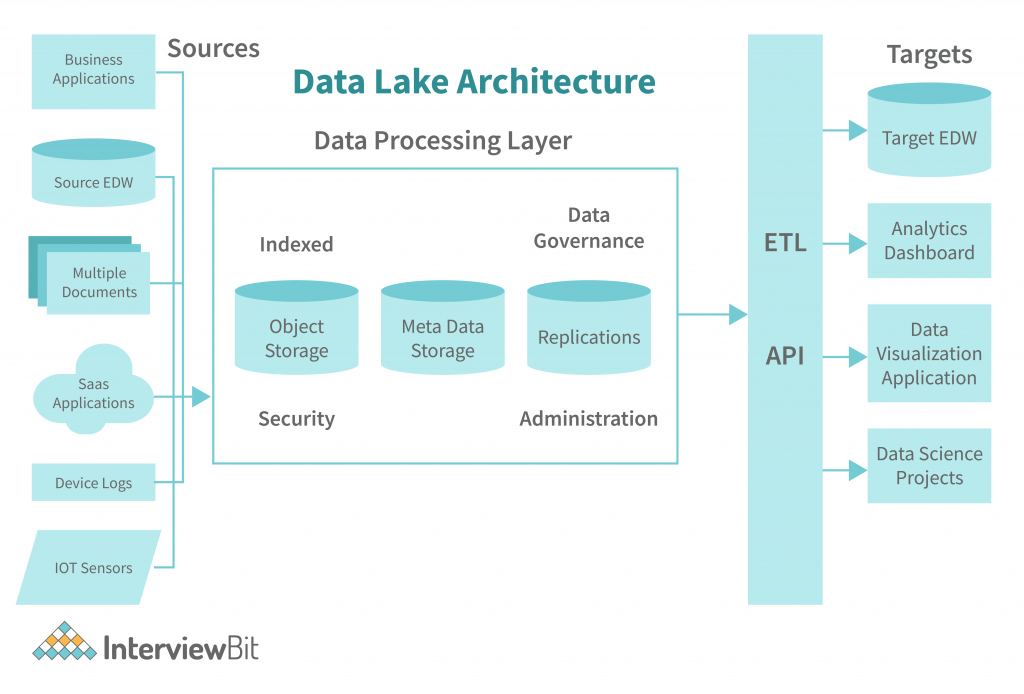
A Data Lake Architecture is a step-by-step process that guides an organization in designing and maintaining a data lake. Data lakes allow organizations to retain a lot of the work that is usually invested in creating a data structure. Here are some of the primary aspects of a robust and effective Data Lake Architectural model:
- It’s critical to monitor and oversee data lake operations in order to measure performance and improve the data lake through monitoring and supervision.
- When determining how to approach the initial phase of an architecture, security must be a key aspect. This differs from relational database security.
- Data that is associated with metadata is referred to as metadata. For example, reload intervals, structures, etc.
- A single organization may have multiple stewardship roles. The individuals who hold these roles are called stewards.
- It is important to be able to track and manage ELT processes in order to perform transformations on the raw data before it reaches the clean space and application layer.
Key Components of Data Lake Architecture
A data lake is an ecosystem where key elements work together to make storing and analyzing large volumes of structured data as easy as possible. There are many different types of data lakes, including public, hybrid and private data lakes. A public data lake is open to everyone to view and use. A private data lake is only available to those who have the necessary security credentials. A hybrid data lake features data from the entire organization and is most likely owned by the Marketing team, though it will be accessible to all business units in their own enterprise copy. An organization should define their own data lake structure based on the following concept.
A Data Lake typically includes five divisions:
Ingestion Layer: The ingesting layer of the Data Lake Architecture is responsible for grabbing raw data and turning it into data inside the data lake. The Raw Data is not modified in this layer. The Ingestion Layer is the first and foremost in the data pipeline to grab the data and process it. The Layer can either be a front-end or a back-end, depending on the requirements of the application. When the data is processed, the information must be transformed into something the application requires. For example, the Social Media Platforms must transform the raw social media data into marketing content, and the Wearable Devices must transform the data into sensor data that can be used to improve the user experience.
Distillation Layer: The Distillation Layer of the Data Lake Architecture is responsible for transforming structured data into an ingestible form in the Ingestion Layer. The data transformation process is also known as cleaning or purging data to meet certain regulatory, compliance, or business needs. Once the data is in a state where it can be easily ingested, it is clear-cut formatted and ready for business users to work with. In the data transformation process, data cleansing is a critical step; it is a key process that must be performed before any other process in the data workflow. A data transformation process must be able to transform the data in a way that is meaningful to the business users. In order to meet this need, the data transformation process must be described in terms of what it does, not what it does not do. We will discuss various stages of data transformation in detail in the following sections. Data transformation is an iterative process, and the first stage is data collection.
Processing Layer: The Data Lake architect first sets the foundation by designing the architecture of the data stores and the analytical tools that will process it. After that, the Data Lake architect determines which parts of the information system will execute the most complex analytical queries and sets up the logical structure of the data. Query and analytical tools are used to transform structured data into usable information. The data management process controls the data, and the analytics process analyses the data. In order to consume the data, it is first extracted and then put into the form required for the analytics process to use it. The data is validated and then loaded into the relevant tables. The controls process validates the data and then records the changes in the control process. The analytics process uses the validated data to produce the desired results. When the process is complete, the data is finally deleted from the systems and systems are restarted as required to maintain the desired state.
Insights Layer: The data is usually stored in the database and then made available through various data sources. The query interface of the Data Lake is used to obtain data from the Data Lake. SQL and NoSQL queries are used to obtain data from the Data Lake. Company users are commonly allowed to use the data if they wish to do so. Once the data is obtained from the Data Lake, it is the same layer that shows it to the user. However, it can be difficult to understand the data when it’s presented in this flat, analytical format. Visualizations and graphs give users a way to understand data in a more visual way, and they can be helpful in conveying complex data trends and facts. Dashboards and reports can be used to give users insight into the health of a company’s data architecture and the efficiency with which queries are processed. They can also be used to monitor the usage of a service or application and identify bottlenecks.
Unified Operations Layer: The workflow management layer is responsible for monitoring and auditing the performance of the various systems in the data lake. It collects data, processes it, and stores the results in the data lake. The data lake also has an auditing layer that monitors the state of the data lake and studies the performance of the various systems in the data lake. It collects data, processes it, analyzes the results to study the state of the data lake and creates reports to help in the decision-making process. Besides data management, the other important functions of the workflow management layer are system and data profiling, data profiling, and data quality assurance. Sandboxes are an open-ended data analysis environment where data scientists can experiment with new data, explore relationships between data sets, and validate predictions with historical data. Sandboxes can be used to model complex real-world phenomena such as climate change, disease epidemics, or economic cycles, and they can be used to help solve business problems by providing data scientists with a place to test new models and collect feedback.
Difference Between Data Lakes and Data Warehouse
In the data lake model, all data is held in a single location and then sent to the ETL tools, which transform the data into a structured or unstructured form. In the data warehouse model, data is held in various locations and then sent to the ETL tools, which create a data warehouse. Both the data lake and data warehouse models are useful, but they have their own set of limitations. With the data lake model, you cannot create granularity or security within the data, and the data lake is not suitable for storing high-value business data. With the data warehouse model, the flexibility of creating an ecosystem around low-cost, open-source tools, etc. can make sense only in specific industries that require low-cost, low-fidelity data analytics.
The following table provides information about the differences between Data Lake and Data Warehouse:
| Data Warehouse | Data Lake |
| • The relational model is used in operational databases, operational analytics, and line of data business applications. | • Relational and non-relational from loT devices, websites, mobile apps, social media, and corporate applications. |
| • Before the DW implementation, the schema was designed (schema-on-write). | • The schema was written at the time of analysis (schema-on-read). |
| • Query results are fastest when using high-cost storage instead of disk. | • Swapping to cheaper storage has helped query results get faster, according to analysis. |
| • The version of the truth that is highly curated is the central version. | • Raw data may or may not be curated, but it can or may not be data curated. |
| • Business analyst | • Data scientists, data developers, and business analysts (using curated data) are employed in the data field. |
| • Reporting, visualizations and batching data are examples of batching. | • Data discovery and profiling are among the many areas where machine learning can be used. |
Benefits of Data Lakes
The main benefits of a data lake are faster data discovery, easier data access, higher data accuracy and reduced data handling and storage costs. With a data lake, you get faster data access because all data is held in the same place, and usage is determined by using the data. E.g. If team members only need certain data in real-time, they can use a real-time feed from the data lake to pull that data and send it to the other teams. With a data lake, easier data access means faster decision-making since users will just need the data and they can find it with ease.
- Data Lakes are computer storage systems specifically designed to collect, store, process, and analyze data. A Data Lake is a large data set that has been collected, stored, and processed in one location. Data Lakes are different from Data Warehouses in that they are not intended to be a permanent storage location for data. Data Lakes are intended to be a transformation or transformation platform that is used to process data and create new data sets to be stored elsewhere.
- The Data Lake, when connected to the real-time world, provides unrivalled accuracy and granularity of answers. Sensitive data is stored in the Data Lake so that it is available anytime, anywhere. This data is immutable, which means that it cannot be changed without updating all records in the system. Advanced data analytics is enabled in the Data Lake through micro-insights, behaviour-based queries, and real-time dashboarding. The only limit to Data Lake analytics is your imagination.
- It also has a large ecosystem of open-source and licensed software, which allows for a large number of plug-and-play solutions. The Data Lake offers all the necessary tools to power analytics, such as Spark, Hadoop, and SQL. It doesn’t matter if you’re using Hadoop, Spark, or some other engine. The Data Lake gives you the ability to run your analysis in any of these engines. It also has a large ecosystem of open-source and licensed software, which allows for a large number of plug-and-play solutions.
- This enables the ability to make decisions based on real-time data, instead of only looking at historical data. The Data Lake also provides a platform for future growth by enabling the creation of new data sources. Analytics on the Data Lake stimulates innovation by enabling data engineers to experiment with new algorithms and data sources in ways that were not possible before.
Challenges of Data Lakes
With so many different players in the market today, it is difficult to make informed decisions when building a data lake ecosystem. This can lead to a data lake with half-baked features and limited scalability. Moreover, with so many different technologies and tools being used in the data lake ecosystem, dependencies and interoperability among the pieces are challenging. This can lead to inconsistency and inaccuracies in the data.
The following are the problems that affect the design, development, and use of Data Lakes:
- Data lakes are great for storing data. However, they’re not so great at managing data. As data sets grow, it’s difficult to maintain a grasp on the security and privacy of data. Data governance, which is a collection of best practices for managing the data you collect and how it’s used, is often overlooked. Data governance is the process of planning, creating, and maintaining a common set of best practices for managing your data. Data governance is important, but it’s not something you can do on the fly. It’s something you need to plan and implement. Data governance is a process, not an event.
- The new members may not be familiar with the tools and services and require explanation. As the process progresses, the company will have to train the new members on how to use the tools and services. This training can be performed by the company or by external partners.
- If you are using a third-party data source and you want to integrate it into your Data Lake, you will need to acquire the data from the source and then convert it into a format that your Data Lake Engine can process. This can be a challenge if your source does not support the ingestion of large amounts of data at once. If the source does not support importing large amounts of data into your Data Lake, it is a good idea to consider using tools that help you with this task, such as Google Cloud Dataflow.
- Data Lakes are not a one-time solution. They require ongoing investments in data management systems and personnel. An enterprise with a Data Lake must also have a process in place to identify and delete duplicate data. It is also essential to regularly monitor the Data Lake to make sure it is not running dry. Finally, an enterprise with a Data Lake must have a process in place to scale the platform as needed to ensure the company’s data isn’t being stored in an underutilized or underresourced solution. Data lakes solve a lot of problems, but they are not a magic bullet. They require an enterprise to invest in the process.
Conclusion
The data lake is a great way for organizations to collect and store structured data. It is a way to centralize all of your data and make it accessible across the organization. It can be used as a hosting facility for other data types, a staging area for data analysis, or to store non-technical staff who might assist with data analysis. The data lake is not only a good way to collect structured data, it can also be used to store unstructured data such as images, videos, financial data, etc. It is important to remember that data lakes are not just about data, they are about an ecosystem of technologies and processes that work together to make storing and processing large volumes of structured data as easy as possible.