Hadoop is an open-source framework for distributed storage and processing. It can be used to store large amounts of data in a reliable, scalable, and inexpensive manner. It was created by Yahoo! in 2005 as a means of storing and processing large datasets. Hadoop provides MapReduce for distributed processing, HDFS for storing data, and YARN for managing compute resources. By using Hadoop, you can process huge amounts of data quickly and efficiently. Hadoop can be used to run enterprise applications such as analytics and data mining. HDFS is the core component of Hadoop. It is a distributed file system that provides capacity and reliability for distributed applications. It stores files across multiple machines, enabling high availability and scalability. HDFS is designed to handle large volumes of data across many servers. It also provides fault tolerance through replication and auto-scalability. As a result, HDFS can serve as a reliable source of storage for your application’s data files while providing optimum performance. HDFS is implemented as a distributed file system with multiple data nodes spread across the cluster to store files.
What is Hadoop HDFS?
Hadoop is a software framework that enables distributed storage and processing of large data sets. It consists of several open source projects, including HDFS, MapReduce, and Yarn. While Hadoop can be used for different purposes, the two most common are Big Data analytics and NoSQL database management. HDFS stands for “Hadoop Distributed File System” and is a decentralized file system that stores data across multiple computers in a cluster. This makes it ideal for large-scale storage as it distributes the load across multiple machines so there’s less pressure on each individual machine. MapReduce is a programming model that allows users to write code once and execute it across many servers. When combined with HDFS, MapReduce can be used to process massive data sets in parallel by dividing work up into smaller chunks and executing them simultaneously.
HDFS Architecture
HDFS is an Open source component of the Apache Software Foundation that manages data. HDFS has scalability, availability, and replication as key features. Name nodes, secondary name nodes, data nodes, checkpoint nodes, backup nodes, and blocks all make up the architecture of HDFS. HDFS is fault-tolerant and is replicated. Files are distributed across the cluster systems using the Name node and Data Nodes. The primary difference between Hadoop and Apache HBase is that Apache HBase is a non-relational database and Apache Hadoop is a non-relational data store.
Confused about your next job?
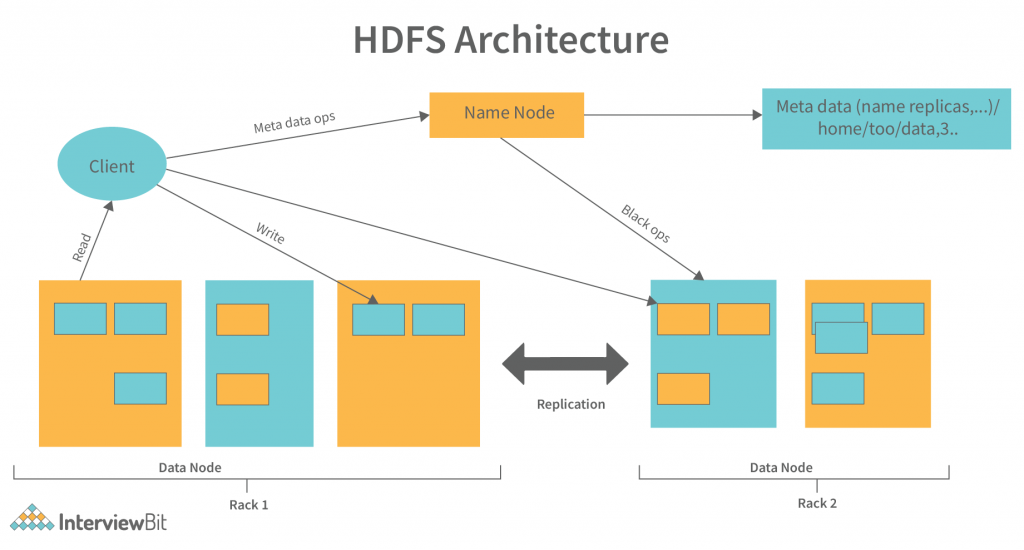
HDFS is composed of master-slave architecture, which includes the following elements:
NameNode
All the blocks on DataNodes are handled by NameNode, which is known as the master node. It performs the following functions:
- Monitor and control all the DataNodes instances.
- Permits the user to access a file.
- Stores all of the block records on a DataNode instance.
- EditLogs are committed to disk after every write operation to Name Node’s data storage. The data is then replicated to all the other data nodes, including Data Node and Backup Data Node. In the event of a system failure, EditLogs can be manually recovered by Data Node.
- All of the DataNodes’ blocks must be alive in order for all of the blocks to be removed from the data nodes.
- Therefore, every UpdateNode in a cluster is aware of every DataNode in the cluster, but only one of them is actively managing communication with all the DataNodes. Since every DataNode runs their own software, they are completely independent. Therefore, if a DataNode fails, the DataNode will be replaced by another DataNode. This means that the failure of a DataNode will not impact the rest of the cluster, since all the DataNodes are aware of every DataNode in the cluster.
There are two kinds of files in NameNode: FsImage files and EditLogs files:
- FsImage: It contains all the details about a filesystem, including all the directories and files, in a hierarchical format. It is also called a file image because it resembles a photograph.
- EditLogs: The EditLogs file keeps track of what modifications have been made to the files of the filesystem.
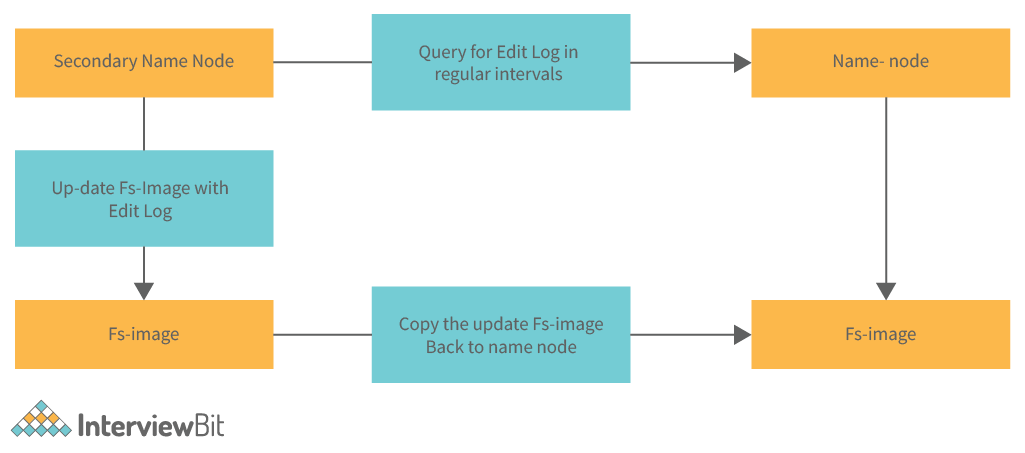
Secondary NameNode
When NameNode runs out of disk space, a secondary NameNode is activated to perform a checkpoint. The secondary NameNode performs the following duties.
- It stores all the transaction log data (from all the source databases) into one location so that when you want to replay it, it is at one single location. Once the data is stored, it is replicated across all the servers, either directly or via a distributed file system.
- The information stored in the filesystem is replicated across all the cluster nodes and stored in all the data nodes. Data nodes store the data. The cluster nodes store the information about the cluster nodes. This information is called metadata. When a data node reads data from the cluster, it uses the metadata to determine where to send the data and what type of data it is. This metadata is also written to a hard drive. The cluster nodes will write this information if the cluster is restarted. The cluster will read this information and use it to determine where to send the data and what type of data it is.
- The FsImage can be used to create a new replica of data, which can be used to scale up the data. If the new FsImage needs to be used to create a new replica, this replication will start with a new FsImage. There are some cases when it is necessary to recover from a failed FsImage. In this situation, a new FsImage must be created from an old one. The FsImage can be used to create backups of data. Data stored in the Hadoop cluster can be backed up and stored in another Hadoop cluster, or the data can be stored on a local file system.
DataNode
Every slave machine that contains data organsises a DataNode. DataNode stores data in ext3 or ext4 file format on DataNodes. DataNodes do the following:
- DataNodes store every data.
- It handles all of the requested operations on files, such as reading file content and creating new data, as described above.
- All the instructions are followed, including scrubbing data on DataNodes, establishing partnerships, and so on.
Checkpoint Node
It establishes checkpoints at specified intervals to generate checkpoint nodes in FsImage and EditLogs from NameNode and joins them to produce a new image. Whenever you generate FsImage and EditLogs from NameNode and merge them to create a new image, checkpoint nodes in HDFS create a checkpoint and deliver it to the NameNode. The directory structure is always identical to that of the name node, so the checkpointed image is always available.
Backup Node
Backup nodes are used to provide high availability of the data. In case one of the active NameNode or DataNodes goes down, the backup node can be promoted to active and the active node switched over to the backup node. Backup nodes are not used to recover from a failure of the active NameNode or DataNodes. Instead, you use a replica set of the data for that purpose. Data nodes are used to store the data and to create the FsImage and editsLogs files for replication. Data nodes connect to one or more replica sets of the data to create the FsImage and editsLogs files for replication. Data nodes are not used to provide high availability.
Blocks
This default size can be changed to any value between 32 and 128 megabytes, depending on the performance required. Data is written to the DataNodes every time a user makes a change, and new data is appended to the end of the DataNode. DataNodes are replicated to ensure data consistency and fault tolerance. If a Node fails, the system automatically recovers the data from a backup and replicates it across the remaining healthy Nodes. DataNodes do not store the data directly on the hard drives, instead using the HDFS file system. This architecture allows HDFS to scale horizontally as the number of users and data types increase. When the file size gets bigger, the block size gets bigger as well. When the file size becomes bigger than the block size, the larger data is placed in the next block. For example, if the data is 135 MB and the block size is 128 MB, two blocks will be created. The first block will be 128 MB, while the second block will be 135 MB. When the file size gets bigger than that, the larger data will be placed in the next block. This ensures that the most data will always be stored at the same block.
Features of HDFS
The following are the main advantages of HDFS:
- HDFS can be configured to create multiple replicas for a particular file. If any one replica fails, the user can still access the data from other replicas. HDFS provides the option to configure automatic failover in case of a failure. So, in case of any hardware failure or an error, the user can get his data from another node where the data has been replicated. HDFS provides the facility to perform software failover. This is similar to automatic failover; however, it is performed at the data provider level. So, in case of any hardware failure or an error, the user can get his data from another node where the data has been replicated.
- Horizontal scalability means that the data stored on multiple nodes can be stored in a single file system. Vertical scalability means that data can be stored on multiple nodes. Data can be replicated to ensure data integrity. Replication occurs through the use of replication factors rather than the data itself. HDFS can store up to 5PB of data in a single cluster and handles the load by automatically choosing the best data node to store data on. Data can be read/updated quickly as it is stored on multiple nodes. Data stored on multiple nodes through replication increases the reliability of data.
- Data is stored on HDFS, not on the local filesystem of your computer. In the event of a failure, the data is stored on a separate server, and can be accessed by the application running on your local computer. Data is replicated on multiple servers to ensure that even in the event of a server failure, your data is still accessible. Data can be accessed via a client tool such as the Java client, the Python client, or the CLI. Access to data is accessible via a wide variety of client tools. This makes it possible to access data from a wide variety of programming languages.
Replication Management in HDFS Architecture
HDFS is able to survive computer crashes and recover from data corruption. HDFS operates on the principle of duplicates, so in the event of failure, it can continue operating as long as there are replicas available. When working on the principle of replicas, data is duplicated and stored on different machines in the DHFS cluster. A replica of every block is stored on at least three DataNodes. HDFS uses a technique referred to as nameNode maintenance to maintain copies on multiple DataNodes. The nameNode keeps track of how many blocks have been under- or over-replicated, and subsequently adds or deletes copies accordingly.
Write Operation
The process continues until all DataNodes have received the data. After DataNodes receive a copy of the file, they send back the location of the last block they received. This enables the NameNode to reconstruct the file. After receiving the last block, the DataNodes notify the NameNode that the job is complete. The NameNode then replies with a complete file that can be used by the application. When a file is split into segments, it must be reassembled to return the file data to the application. Splitting a file into segments is a method that enables the NameNode to optimize its storage capacity. Splitting a file into segments also improves fault tolerance and availability. When the client receives a split file, the process is similar to that of a single file. The client divides the file into segments, which are then sent to the DataNode. DataNode 1 receives the segment A and passes it to DataNode 2 and so on.
Read Operation
The client then sends the file to the Replicator. The Replicator does not have a copy of the file and must read the data from another location. In the background, data is then sent to the DataNode. The DataNode only has metadata and must contact the other data nodes to receive the actual data. The data is then sent to the Replicator. The Replicator again does not have a copy of the file and must read the data from another location. Data is then sent to the Reducer. The Reducer does have a copy of the data, but a compressed version.
Advantages of HDFS Architecture
- It is a highly scalable data storage system. This makes it ideal for data-intensive applications like Hadoop and streaming analytics. Another major benefit of Hadoop is that it is easy to set up. This makes it ideal for non-technical users.
- It is very easy to implement, yet very robust. There is a lot of flexibility you get with Hadoop. It is a fast and reliable file system.
- This makes Hadoop a great fit for a wide range of data applications. The most common one is analytics. You can use Hadoop to process large amounts of data quickly, and then analyze it to find trends or make recommendations. The most common type of application that uses Hadoop analytics is data crunching.
- You can increase the size of the cluster by adding more nodes or increase the size of the cluster by adding more nodes. If you have many clients that need to be stored on HDFS you can easily scale your cluster horizontally by adding more nodes to the cluster. To scale your cluster vertically, you can increase the size of the cluster. Once the size of the cluster is increased, it can serve more clients.
- This can be done by setting up a centralized database, or by distributing data across a cluster of commodity personal computers, or a combination of both. The most common setup for this type of virtualization is to create a virtual machine on each of your servers.
- Specialization reduces the overhead of data movement across the cluster and provides high availability of data.
- Automatic data replication can be accomplished with a variety of technologies, including RAID, Hadoop, and database replication. Logging data and monitoring it for anomalies can also help to detect and respond to hardware and software failures.
Disadvantages of HDFS Architecture
- It is important to have a backup strategy in place. The cost of downtime can be extremely high, so it is important to keep things running smoothly. It is also recommended to have a security plan in place. If your company does not have a data backup plan, you are putting your company’s data at risk.
- The chances are that the data in one location is vulnerable to hacking. Imagine the fear of losing valuable data when a disaster strikes. To protect data, backup data to a remote location. In the event of a disaster, the data can be quickly restored to its original location.
- This can be done manually or through a data migration process. Once the data is copied to the local environment, it can be accessed, analyzed, and used for any purpose.
Conclusion
The Hadoop Distributed File System (HDFS) is the most popular distributed storage system in the world. It is designed to scale up to large amounts of data, and it offers many advantages over traditional file systems. For example, HDFS can efficiently store and retrieve large amounts of data across a cluster of machines without having to worry about disk reliability. HDFS also makes it easy to add new nodes to an existing cluster, which makes it possible to scale out as the number of machines increases.
This architecture shows a three-tier design for storing data on the server. In the first tier, a single server stores all of the data for the entire cluster. In addition, each node in the cluster stores copies of this data, which allows for fast access even when one or more nodes are offline. In the second tier, each node stores its own local copy of all of the data that it has stored on its local hard drive or SSD drive. Finally, in the third tier, each node stores a copy on HDFS so that other nodes can access this data even when one or more nodes are offline.