Introduction
Data processing and data access using the Lambda Architecture are combined with a fast real-time stream pipeline in a data processing workflow. A common architecture model in IT and development toolkits as businesses strive to become more data-driven and event-oriented in the face of massive volumes of rapidly generated data, often referred to as “big data,” are businesses that are striving to become more data-oriented and event-oriented in the face of massive volumes of rapidly generated data, often referred to as “big data.”
We will discuss Lambda Architecture in great detail, including its applications, advantages, and disadvantages.
What is Lambda Architecture?
This architecture forms the basis for huge data ingestion and processing. It also captures and functions on historical data. We are trying to solve the problem of computing arbitrary functions as well as the problem of dealing with three layers of problems.
Confused about your next job?
- Batch layer
- Serving layer
- Speed layer
In the past, we called batch layers a “data lake” style system similar to Hadoop. They also used to be referred to as “batch layers.” This layer helps with batch queries in addition to supporting batch processing. We generate analytics or ad hoc using batch processing. The speed layer is similar to the batch layer in that it performs real-time analytics. It, however, calculates those analytics in real-time on the most recent data. The analytics calculated by the batch layer are referred to as analytics.
For example Fast-moving data that is zero to one hour old is the layer’s responsibility for calculating real-time analytics. It is based on data that one hour ago was fast-moving.
The third layer, which was formerly known as the serving layer, handled serving up results. Additionally, the speed and batch layers were both involved.
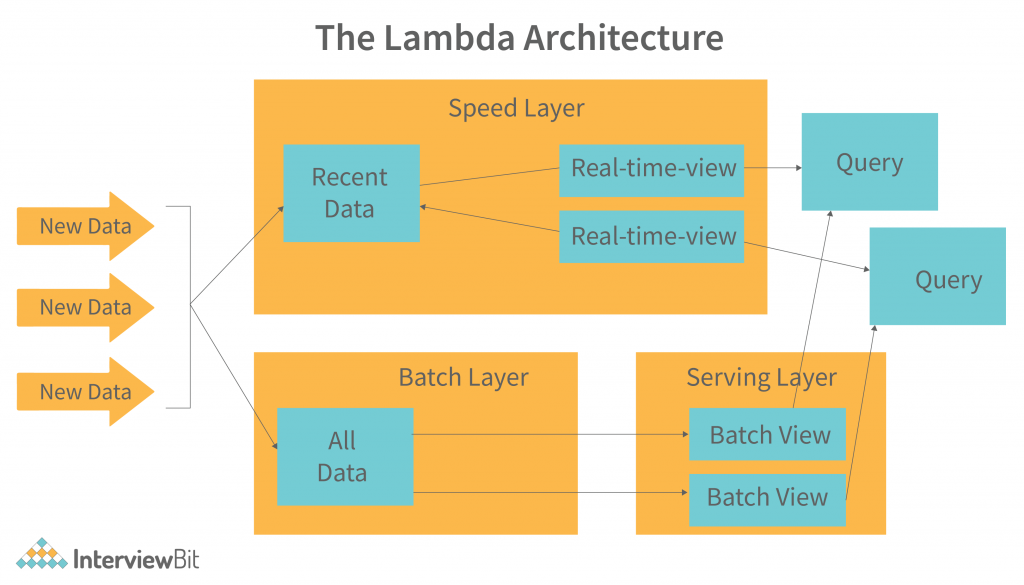
- The data arrives at both the batch layer and the speed layer in order to be processed.
- The batch layer performs two important functions:
- Managing the master dataset is part of the task.
- To pre-compute the batch views prior to the jobs starting.
- We also refer to this layer as a serving. The high latency of updates to the serving layer is compensated for by the speed layer, which handles recent data only. layer. It indexes batch views in order to make them low-latency, ad-hoc queries.
- The high latency of updates to the serving layer is compensated for by the speed layer, which handles recent data only.
- A batch view can be joined with a real-time view to answer any incoming query.
Data Sources
The Lambda Architecture can be used to conduct data analysis, and a variety of sources can be used to provide data. Apache Kafka, for instance, is not the original data source; rather, it is a between-store intermediary that is used to hold data in batches and at high speeds. The data is processed simultaneously to both the batch layer and the speed layer in order to speed up indexing.
Batch Layer
In preparation for indexing, the system saves batch views in a model that resembles a series of additions and deletions to a system of record, similar to what would occur when a change data capture (CDC) system generated a change record (CR). This model is commonly written as a comma-separated values (CSV) file. During a CDC system, the data is stored as immutable append only records and is processed using technologies such as Apache Hadoop.
Serving Layers
There are several layers to the Erlang Cache, including this one that indexes the latest batch of views and then also reindexes all data to fix a coding bug or to create different indexing schemes for different purposes. The serving layer must process the data in an extremely parallelized way to reduce the time to index the data. New data will be queued up for indexing in the next indexing job if they are not yet covered by an index.
Speed Layer
The speed layer helps fill in the gaps in the serving layer by indexing data that the serving layer is currently indexing as well as data that has recently been added. Data that has been added to the system after the indexing job started is expected to take a while to be indexed. The speed layer therefore needs to index the most recent data so that the gap between the most recent data and the most recent data can be narrowed. The stream processing software used to index incoming data in real time to reduce latency is usually leveraged to perform this function. In the Lambda Architecture, Apache Storm was the leading stream processing engine adopted prior to Lambda (but other technologies have since gained more popularity as alternatives). Nowadays, Hazelcast Jet, Apache Flink, and Apache Spark Streaming are all popular stream processing engines.
Query
The serving layer and the speed layer processes end user queries submitted to them by this component. The results of these processes are then consolidated by this component, resulting in near real-time analytics.
How Does Lambda Architecture Work?
The batch layers continue to index incoming data in batches. The speed layer, on the other hand, indexes all the new, unindexed data in near real-time to complement the batch/serving layers. This provides you with a detailed and constant view of data in the batch/serving layers, as well as a smaller index that is current and up-to-date.
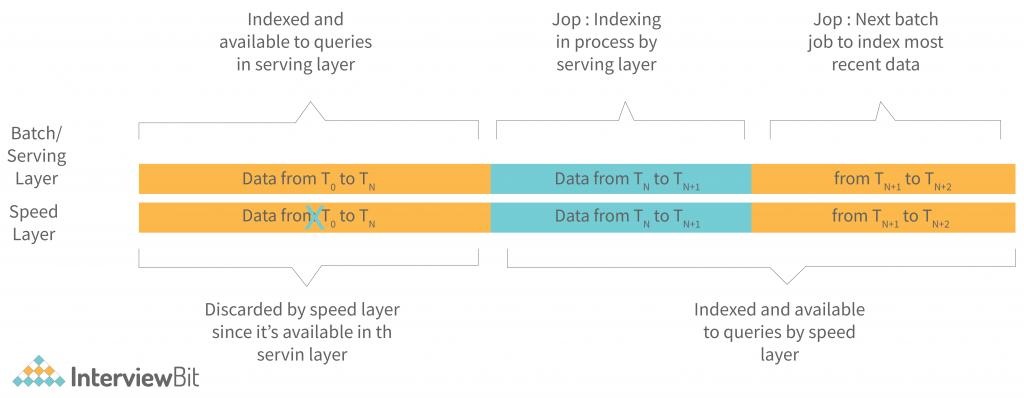
After a batch indexing job has finished, the newly batch-indexed data is available for querying, so the speed layer’s copy of the same data and indexes is removed and cannot be used to speed up the serving layer. The serving layer then begins indexing the most recently produced data in the system, which has already been indexed by the speed layer (so it is available for querying at the speed layer). This ongoing cross-layer transfer ensures that all data is available for querying and that latency is kept low.
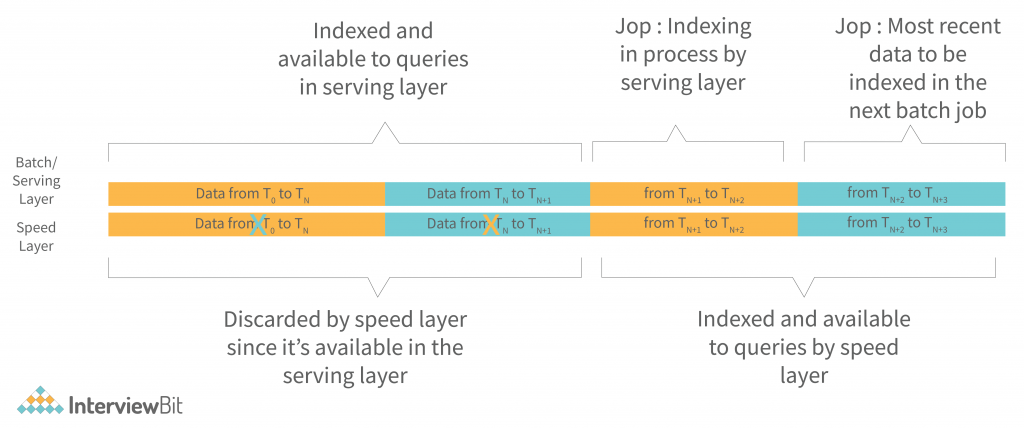
The speed layer discards the data copied by the serving layer when the serving layer completes a job.
Features of Lambda
A lambda architecture has the following benefits:
- No software management is required, so there are no installation, maintenance, or administration steps.
- To suit your application, you can either scale it automatically or manually adjust its capacity.
- There are no human errors or outages in serverless applications, because they are built-in with fault tolerance and availability.
- To be able to react to changing business and market conditions, you must be able to business agility.
Typical Lambda Applications
Lambda functions and triggers are the key components of developing on AWS Lambda. Code and runtime for Lambda functions are Lambda functions, while AWS services or applications that invoke them are triggers. In the following sections, you’ll learn about the following:
- A photo-sharing application stores user photos in an Amazon S3 bucket and creates thumbnail versions of each user’s photos for display on their profile page. You may implement a Lambda function to create a thumbnail automatically or you may choose to do it manually. A photo object can be retrieved from the S3 bucket by your Lambda function code, created a thumbnail version, and saved in a new S3 bucket.
- A DynamoDB table stores data and analyzes it. When you create a Lambda function that writes, updates, or deletes items in a table, DynamoDB streams publish item update events. In this scenario, the event data provides the item key, event name (such as insert, update, and delete), and other relevant data. You can aggregate raw data using a Lambda function to create custom metrics.
- A DynamoDB table stores data and analyzes it. When you create a Lambda function that writes, updates, or deletes items in a table, DynamoDB streams publish item update events. In this scenario, the event data provides the item key, event name (such as insert, update, and delete), and other relevant data. You can aggregate raw data using a Lambda function to create custom metrics.
- A Lambda function can be created to respond to events produced by a custom mobile app. You can, for example, configure a Lambda function to handle clicks within your custom mobile app.
Advantages of Lambda Architecture
A lambda architecture has the following advantages:
- Human-fault tolerance and robustness. The batch layer is human-fault tolerant, since it contains the entire data set from the beginning of time. Deleting and replacing corrupted batch views would restore all of the data from the point of corruption forward. All batch views can be swapped out for freshly created ones. The speed layer can be discarded. Since the system would be reset and running again as soon as new batch views are generated, the batch layer would take longer to process them.
- A Lambda Architecture is built with distributed systems at the top layers. Therefore, adding more machines will allow users to easily horizontally scale those systems.
- In Lambda Architecture, there is no one way to compute a batch view or perform a speed layer computation. Since it is a general paradigm, Lambda Architecture adopters do not have to limit themselves to a specific way of computing this or that batch view or layer computation. Batch views and speed layer computations may be designed to meet the needs of the data system if they are so inclined.
- New data enters the data system as extensibility. Data systems are not constrained by a set of batch views, as new views are needed as new data enters the system. Despite the constraints, resources can be expanded to allow for new views.
- Ad hoc queries are still possible even if the high-latency for these ad hoc queries is permissible. The batch layer can still be used for ad hoc queries that were not available in the batch views, assuming the high-latency for these ad hoc queries is permissible.
- The typical incarnation of Lambda Architecture relies on Apache Hadoop for the batch job layer and ElephantDB for the serving layer. Both can be maintained relatively easily.
- Debuggability, An input to the batch layer’s computation of batch views is always the entire data set, whereas the inputs and outputs for each layer in Lambda Architecture are not subject to movement. As a result, debugging computations and queries is considerably simpler in Lambda Architecture.
- The speed layer of Lambda Architecture provides real-time queries of the latest data set in low latency reads and updates.
Disadvantages of Lambda Architecture
A lambda architecture has the following disadvantages:
- A high level of coding is incurred because of the comprehensive processing that occurs.
- Every batch cycle that is not advantageous in certain situations is re-processed.
- In order to move or reorganize data modeled with Lambda architecture, it is difficult to model it with lambda architecture.
- The complexity of lambda architectures is often high. Both batch and streaming layers must be maintained as two distinct code bases, which may result in difficult debugging.
Conclusion
We have discussed Lambda Architecture and determined its functioning and applications. In addition, we have studied Lambda Architecture’s limitations and benefits. Lambda architecture is a software architecture pattern that is designed to encourage the separation of concerns and decoupling of logic from data. Lambda architecture is a popular approach to software development that aims to reduce the coupling between logic and data by decoupling logic from data. The key idea behind lambdas is that the logic of a program can be abstracted away from its data, allowing it to be written in a way that makes it easy to test and maintain. The most common use of lambdas is in development environments such as web frameworks, which often consist of a single set of code that is responsible for handling all the logic of the application. By separating logic from data, it becomes easier to test and maintain code, which can lead to more reliable applications. Lambda architecture can also be used to decouple logic from data in other areas of software development, such as databases and web services. By separating logic from data, it becomes easier to develop applications that are more maintainable and flexible.