- Introduction
- What is Big Data Architecture?
- Types of Big Data Architecture
- Big Data Tools and Techniques
- Massively Parallel Processing (MPP)
- No-SQL Databases
- Distributed Storage and Processing Tools
- Cloud Computing Tools
- Big Data Architecture Application
- Benefits of Big Data Architecture
- Big Data Architecture Challenges
- Conclusion
- Additional Resources
Big data tools and techniques demand special big data tools and techniques. When it comes to managing large quantities of data and performing complex operations on that massive data, big data tools and techniques must be used. The big data ecosystem and its sphere are what we refer to when we say using big data tools and techniques. There is no solution that is provided for every use case and that requires and has to be created and made in an effective manner according to company demands. A big data solution must be developed and maintained in accordance with company demands so that it meets the needs of the company. A stable big data solution can be constructed and maintained in such a way that it can be used for the requested problem.
We will go through the Big Data Architecture, Big Data architecture and application, the technology used in big data architecture, the tools and methods available for big data, and big data architecture courses in this article.
Introduction
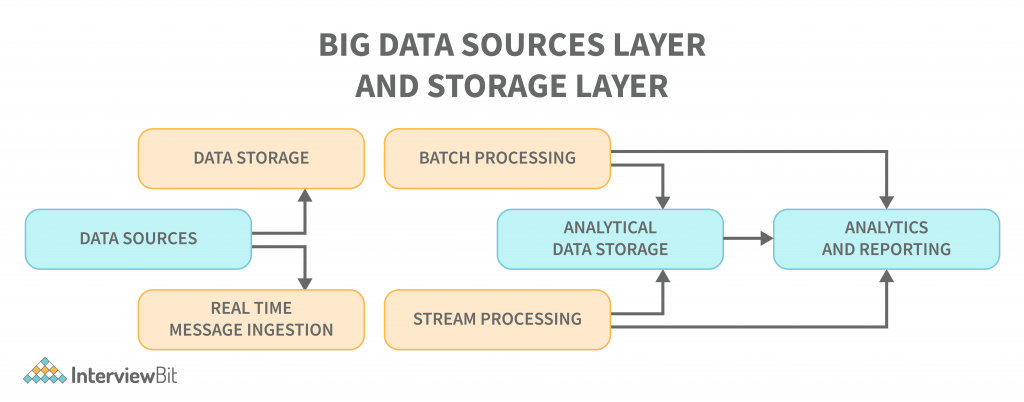
Big data architecture is a comprehensive solution to deal with an enormous amount of data. It details the blueprint for providing solutions and infrastructure for dealing with big data based on a company’s demands. It clearly defines the components, layers, and methods of communication. The reference point is the ingestion, processing, storing, managing, accessing, and analysing of the data. A big data architecture typically looks like the one shown below, with the following layers:
Confused about your next job?
- A database management system that handles data ingestion, processing, and analysis is too complex or too large to handle a traditional architecture. A traditional architecture handles all of that in one fell swoop, while a database management system handles it in chunks.
- Some organisations have threshold values for gigabytes or terabytes, while others, even millions of gigabytes or terabytes, are not good enough.
- As an example, if you look at storage systems and commodity markets, the values and costs of storage have significantly decreased due to this occurrence. There is lots of data that requires different methods to be stored.
- A big data architecture addresses some of these problems by providing a scalable and efficient method of storage and processing data. Some of them are batch-related data that occurs at a particular time and therefore the jobs must be scheduled in the same way as batch data. Streaming class jobs require a real-time streaming pipeline to be built to meet all of their demands. This process is accomplished through big data architecture.
What is Big Data Architecture?
There is more than one workload type involved in big data systems, and they are broadly classified as follows:
- Merely batching data where big data-based sources are at rest is a data processing situation.
- Real-time processing of big data is achievable with motion-based processing.
- The exploration of new interactive big data technologies and tools.
- The use of machine learning and predictive analysis.
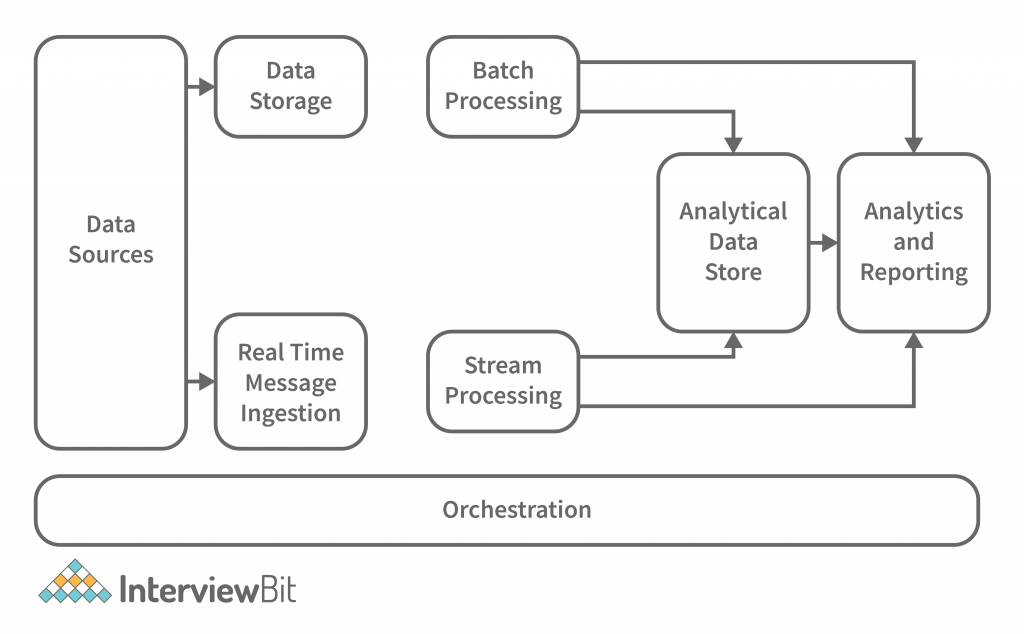
- Data Sources: All of the sources that feed into the data extraction pipeline are subject to this definition, so this is where the starting point for the big data pipeline is located. Data sources, open and third-party, play a significant role in architecture. Relational databases, data warehouses, cloud-based data warehouses, SaaS applications, real-time data from company servers and sensors such as IoT devices, third-party data providers, and also static files such as Windows logs, comprise several data sources. Both batch processing and real-time processing are possible. The data managed can be both batch processing and real-time processing.
- Data Storage: There is data stored in file stores that are distributed in nature and that can hold a variety of format-based big files. It is also possible to store large numbers of different format-based big files in the data lake. This consists of the data that is managed for batch built operations and is saved in the file stores. We provide HDFS, Microsoft Azure, AWS, and GCP storage, among other blob containers.
- Batch Processing: Each chunk of data is split into different categories using long-running jobs, which filter and aggregate and also prepare data for analysis. These jobs typically require sources, process them, and deliver the processed files to new files. Multiple approaches to batch processing are employed, including Hive jobs, U-SQL jobs, Sqoop or Pig and custom map reducer jobs written in any one of the Java or Scala or other languages such as Python.
- Real Time-Based Message Ingestion: A real-time streaming system that caters to the data being generated in a sequential and uniform fashion is a batch processing system. When compared to batch processing, this includes all real-time streaming systems that cater to the data being generated at the time it is received. This data mart or store, which receives all incoming messages and discards them into a folder for data processing, is usually the only one that needs to be contacted. Message-based ingestion stores such as Apache Kafka, Apache Flume, Event hubs from Azure, and others, on the other hand, must be used if message-based processing is required. The delivery process, along with other message queuing semantics, is generally more reliable.
- Stream Processing: Real-time message ingest and stream processing are different. The latter uses the ingested data as a publish-subscribe tool, whereas the former takes into account all of the ingested data in the first place and then utilises it as a publish-subscribe tool. Stream processing, on the other hand, handles all of that streaming data in the form of windows or streams and writes it to the sink. This includes Apache Spark, Flink, Storm, etc.
- Analytics-Based Datastore: In order to analyze and process already processed data, analytical tools use the data store that is based on HBase or any other NoSQL data warehouse technology. The data can be presented with the help of a hive database, which can provide metadata abstraction, or interactive use of a hive database, which can provide metadata abstraction in the data store. NoSQL databases like HBase or Spark SQL are also available.
- Reporting and Analysis: The generated insights, on the other hand, must be processed and that is effectively accomplished by the reporting and analysis tools that utilize embedded technology and a solution to produce useful graphs, analysis, and insights that are beneficial to the businesses. For example, Cognos, Hyperion, and others.
- Orchestration: Data-based solutions that utilise big data are data-related tasks that are repetitive in nature, and which are also contained in workflow chains that can transform the source data and also move data across sources as well as sinks and loads in stores. Sqoop, oozie, data factory, and others are just a few examples.
Types of Big Data Architecture
Lambda Architecture
A single Lambda architecture handles both batch (static) data and real-time processing data. It is employed to solve the problem of computing arbitrary functions. In this deployment model, latency is reduced and negligible errors are preserved while retaining accuracy. The big data architecture illustrated below is similar to that described:
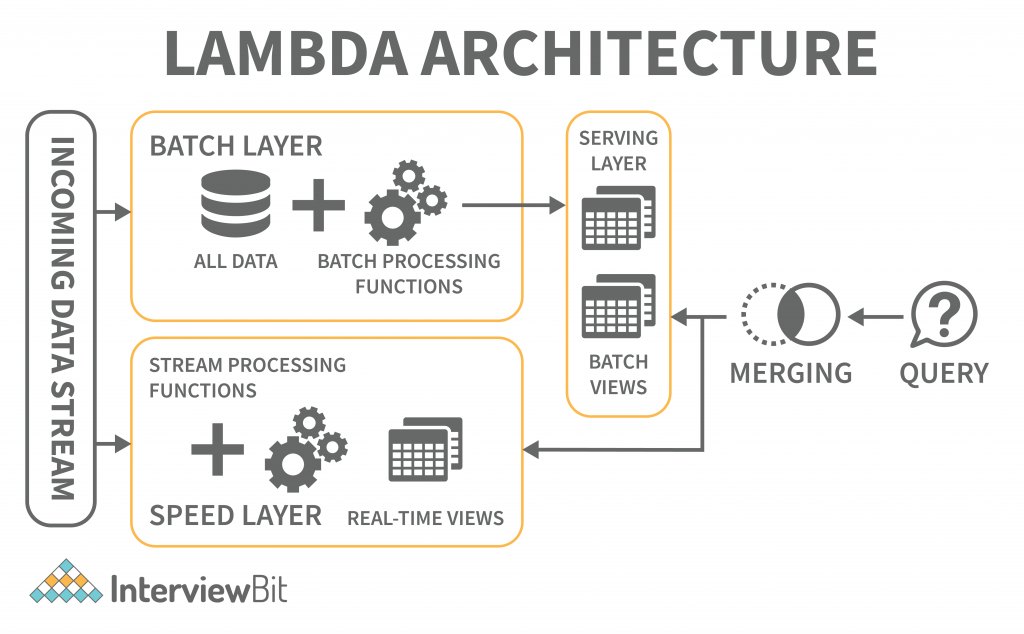
The lambda architecture is comprised of these layers:
- Batch Layer: The batch layer of the lambda architecture saves incoming data in its entirety as batch views. The batch views are used to prepare the indexes. The data is immutable, and only copies of the original data are created and preserved. The batch layer ensures consistency by making the data append-only. It is the first layer in the lambda architecture that saves incoming data in its entirety as batch views. The data cannot be changed, and only copies of the original data are created and preserved. The data that is saved is immutable, meaning that it cannot be changed, and only copies of the original data are preserved and stored. The data that is saved is append-only, which ensures that it is prepared before it is presented. The master dataset and then pre-computing the batch views are handled this way.
- Speed Layer: The speed layer delivers data straight to the batch layer, which is responsible for computing incremental data. However, the speed layer itself may also be reduced in latency by reducing the number of computations. The stream layer processes the processed data from the speed layer to produce error correction.
- Serving Layer: The batch views and the speed outcomes traverse to the serving layer as a result of the batch layers batch views. The serving layer indexes the views and parallelizes them to ensure users’ queries are fast and are exempt from delays.
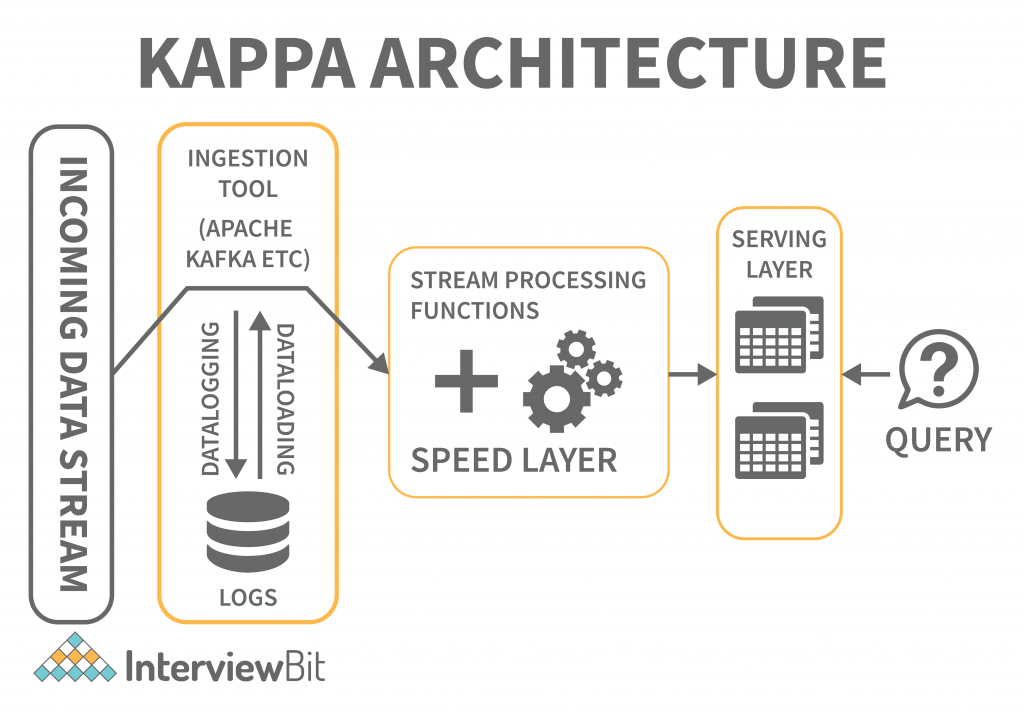
Kappa Architecture
When compared to Lambda architecture, Kappa architecture is also intended to handle both real-time streaming and batch processing data. The Kappa architecture, in addition to reducing the additional cost that comes from the Lambda architecture, replaces the data sourcing medium with message queues.
The messaging engines store a sequence of data in the analytical databases, which are then read and converted into appropriate format before being saved for the end-user.
The architecture makes it easy to access real-time information by reading and transforming the message data into a format that is easily accessible to end users. It also provides additional outputs by allowing previously saved data to be taken into account.
The batch layer was eliminated in the Kappa architecture, and the speed layer was enhanced to provide reprogramming capabilities. The key difference with the Kappa architecture is that all the data is presented as a series or stream. Data transformation is achieved through the steam engine, which is the central engine for data processing.
Big Data Tools and Techniques
A big data tool can be classified into the four buckets listed below based on its practicability.
- Massively Parallel Processing (MPP)
- No-SQL Databases
- Distributed Storage and Processing Tools
- Cloud Computing Tools
Massively Parallel Processing (MPP)
A loosely coupled or shared nothing storage system is a massively parallel processing construct with the goal of dividing up a large number of computing machines into discrete pieces and proceeding in parallel. An MPP system is also referred to as a loosely coupled or shared nothing system. Processing is accomplished by breaking a large number of computer processors into separate bits and proceeding in parallel.
Each processor works on separate tasks, has a different operating system, and does not share memory. It is also possible for up to 200 or more processors to work on applications connected to this high-speed network. In each case, the processor handles a different set of instructions and has a different operating system, which is not shared. MPP may also send messages between processes via a messaging system that allows it to send commands to the processors.
MPP-based databases are IBM Netezza, Oracle Exadata, Teradata, SAP HANA, EMC Greenplum.
No-SQL Databases
Structures are employed to help associate data with a particular domain. Data cannot be stored in a structured database unless it is first converted to one. SQL (or NoSQL) is a non-structured language used to encapsulate unstructured data and create structures for heterogeneous data in the same domain. NoSQL databases offer a vast array of configuration scalability, as well as versatility, and scalability in handling large quantities of data. There is also distributed data storage, making data available locally or remotely.
NoSQL databases include the following categories:
- Key-value Pair Based
- Graphs based
- Column-oriented Graph
- Document-oriented
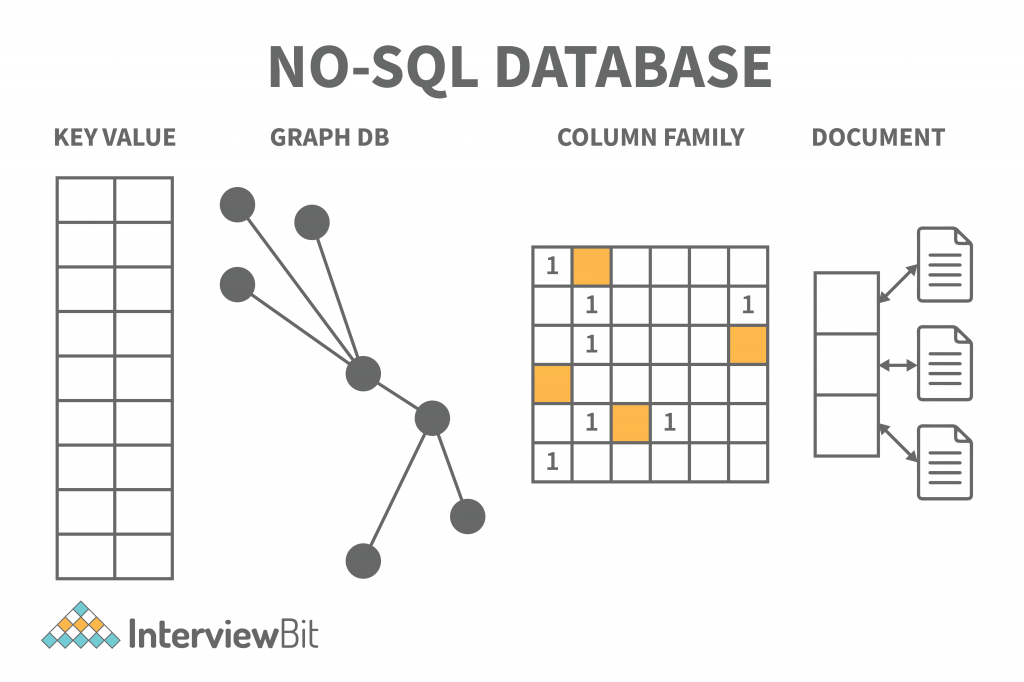
Key-value model: Dictionaries, collections, and associative arrays can often use hash tables to store data, but this database stores information in a unique key-value pair. The key is required to access data and the value is used to record information. It helps store data without a schema. The key is unique and used to retrieve and update data, while the value is a string, char, JSON, or BLOB. Redis, Dynamo, and Riak are the key-value store databases.
Graph-based model: Graph databases store both entities and relationships between them, and they are multi-relational. Nodes and links and entities are stored as elements on the graph, and relationships between these elements are represented by edges (or nodes). Graph databases are employed for mapping, transportation, social networks, and spatial data applications. They may also be used to discover patterns in semi-structured and unstructured data. The Neo4J, FlockDB, and OrientDB graph databases are available.
Column-based NoSQL database: Columnar databases work on columns. Compared to relational databases, they have a set of columns rather than tables. Each column is significant, and it is viewed independently. The values in the database are stored in a contiguous manner and may not have values. Because columns are easy to assess, columnar databases are efficient at performing summarisation jobs such as SUM, COUNT, AVG, MIN, and MAX.
Column families are also known as Wide columns or Columnar columns or Column stores. These are used for data structures, business intelligence, CRM, and catalogues of library cards.
The columnar databases Cassandra, HBase, and Hypertable use NoSQL databases that use columnar storage.
Document-Oriented NoSQL database: The document-oriented database stores documents in order to make them essentially document-oriented rather than data-oriented. JSON or XML are the formats used for data, and key-value pairs and the format of JSON or XML are used for data. E-commerce applications, blogging platforms, real-time analytics, Content Management systems (CMS), are among the applications that benefit from these databases.
MongoDB, CouchDB, Amazon SimpleDB, Riak, Lotus Notes. NoSQL document databases are MongoDB, CouchDB, Amazon SimpleDB, Riak, and Lotus Notes.
Distributed Storage and Processing Tools
A distributed database is a set of data storage chunks that is distributed over a network of computers. Data centres may have their own processing units for distributed databases. The distributed databases may be physically located in the same location or dispersed over an interconnected network of computers. The distributed databases are heterogeneous (having a variety of software and hardware), homogeneous (having the same software and hardware across all instances), and different, supported by distinct hardware.
The leading big data processing and distribution platforms are Hadoop HDFS, Snowflake, Qubole, Apache Spark, Azure HDInsight, Azure Data Lake, Amazon EMR, Google BigQuery, Google Cloud Dataflow, MS SQL.
Distributed databases are often equipped with the following tools:
- The purpose of working with big data is to process it, and Hadoop is one of the most effective solutions for this purpose. It is used to store, process, and analyse huge amounts of data. Loading processing tools are required to process the vast amount of data.
- The MapReduce programming model facilitates the efficient formatting and organisation of huge quantities of data into precise sets by performing operations of compilation and organisation of the data sets.
- Hadoop is an open-source software project from the Apache Foundation that allows for the computation of computational software. Spark, another open-source project from the Apache Foundation, is to fasten computational computing software processes.
Cloud Computing Tools
Cloud Computing Tools refers to the network-based computing services that utilise the Internet’s development and services. The shared pool of configurable computing resources, which are available at any time and anywhere and at any time, are shared by all network-based services. This service is available for paid-for use when required and is provided by the service provider. The platform is very useful in handling large amounts of data.
Amazon Web Services (AWS) is the most popular cloud computing tool, followed by Microsoft Azure, Google Cloud, Blob Storage, and DataBricks. Oracle, IBM, and Alibaba are also popular cloud computing tools.
Big Data Architecture Application
An important aspect of a big data architecture is using and applying big data applications, in particular, the big data architecture utilises and applies big data applications are:
- The data structure of the big data architecture allows deleting of sensitive data right at the beginning because of its data ingesting procedure and because of its data lake storage.
- A batch-or real-time-involving big data architecture ingests data both in the batch and real-time. Batch processing has a frequency and recurring schedule. The ingestion process and the job scheduling for the batch data are simplified as the data files can be partitioned. The query performance is improved by partitioning the tables. Hive, U-SQL, or SQL queries are used to partition the table data.
- Distributed batch files can be split further using parallelism and reduced job time. Another application is to disperse the workload across processing units. The static batch files are created and saved in formats that can be split further. The Hadoop Distributed File System (HDFS) can cluster hundreds of nodes and can parallelly process the files, eventually decreasing job times.
Benefits of Big Data Architecture
- High-performance parallel computing: Big data architectures employ parallel computing, in which multiprocessor servers perform lots of calculations at the same time to speed up the process. Large data sets can be processed quickly by parallelising them on multiprocessor servers. Part of the job can be handled simultaneously.
- Elastic scalability: Big Data architectures can be scaled horizontally, allowing the environment to be tuned to the size of the workloads. A big data solution is usually operated in the cloud, where you only have to pay for the storage and processing resources you actually utilise.
- Freedom of choice: Big Data architectures may use various platforms and solutions in the marketplace, such as Azure-managed services, MongoDB Atlas, and Apache technologies. You can pick the right combination of solutions for your specific workloads, existing systems, and IT expertise levels to achieve the best result.
- The ability to interoperate with other systems: You can use Big Data architecture components for IoT processing and BI as well as analytics workflows to create integrated platforms across different types of workloads.
Big Data Architecture Challenges
- Security: When it comes to static big data, the data lake is the norm. Because security is required to safeguard your data from intrusion and theft, robust security is required. In addition, setting up secure access can be difficult. Other applications must also consume data in order for them to function.
- Complexity: The moving parts of a Big Data architecture typically consist of many interlocking elements. These components may have their own data-injection pipelines and various configuration settings to improve performance, in addition to many cross-component configuration interventions. Big Data procedures are demanding in nature and require a lot of knowledge and skill.
- Evolving technologies: Choosing the right solutions and components is critical to meeting Big Data business objectives. It can be challenging to determine which Big Data technologies, practices, and standards are still in the midst of a period of advancement, as many of them are relatively new and still evolving. Core Hadoop components such as Hive and Pig have reached a stable stage, but other technologies and services are still in development and are likely to change over time.
- Expertise in a specific domain: As Big Data APIs built on mainstream languages gradually become popular, we can see Big Data architectures and solutions using atypical, highly specialized languages and frameworks. Nevertheless, Big Data architectures and solutions do generally use unique, highly specialised languages and frameworks that impose a substantial learning curve for developers and data analysts alike.
Conclusion
Big data architectures can deal with large amounts of data that is too complex or big for traditional database systems. Big data architecture framework serves as a reference blueprint for big data infrastructures and solutions, since big data infrastructures and solutions are used to process, ingest, and analyse large amounts of data. Big data infrastructures and solutions handle large quantities of data for business purposes, steer data analytics, and provide an environment in which big data analytics tools can extract vital business information, in addition big data infrastructure and solutions serve as a blueprint for big data infrastructures and solutions.
We hope you enjoyed reading about the requirements for big data architectures in this post.

