Introduction
Before diving into architectural details, it’s important to understand the purpose of a data warehouse. Data warehouses are unique in that they store both live and archived data in one location. This means that the same data is available both as a result of business processes being completed or operations being performed and also because it is simply existing data stored in one place. The data warehouse is a repository of data that has been extracted from a variety of sources, including data reported by users, manufacturers, and third-party vendors. It has been organized into tables and other databases to make it more accessible and easier to use. Although the term “data warehouse” may conjure up images of large, detailed repositories with high storage requirements, many modern data warehouses are optimized for speed and accessibility so that they can be used efficiently by businesses of all sizes.
This article covers everything you need to know about designing a data warehouse architecture. We explain why data warehouses are necessary and how they can be implemented; we discuss the primary types of architectures available; and we highlight factors to consider when deciding between various options.
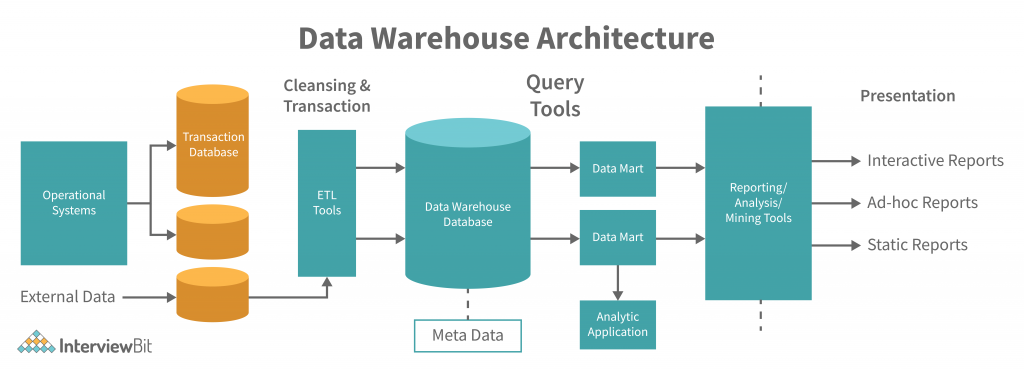
Data Warehouse Architecture
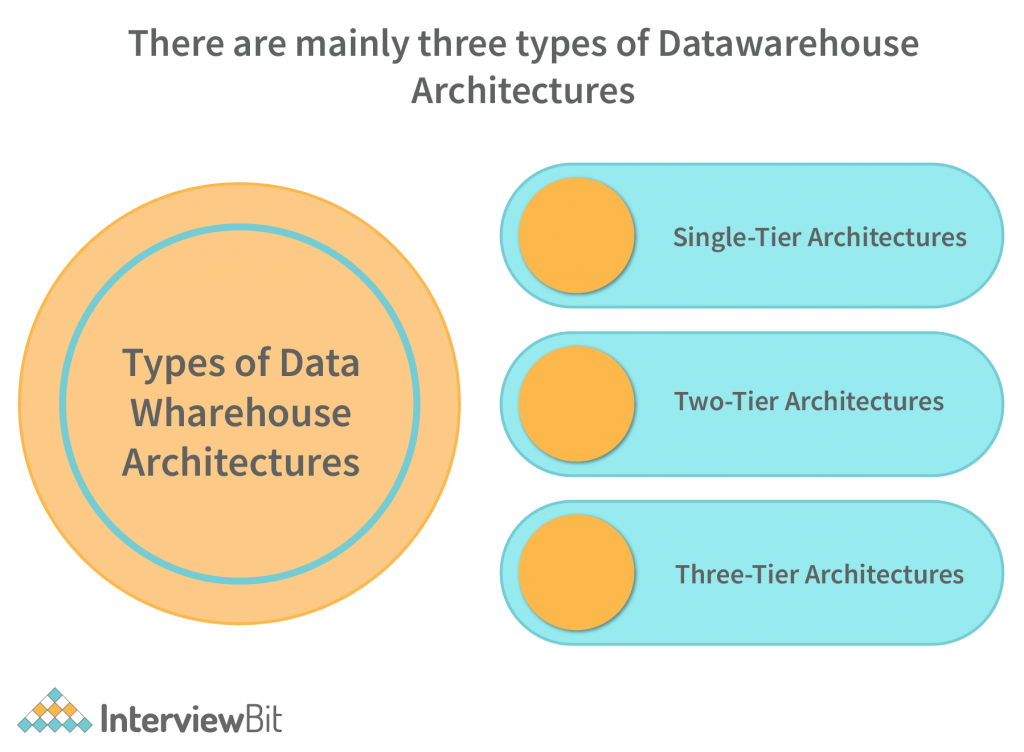
The single-tier Data Warehouse architecture is composed of a single hardware layer. This hardware layer is composed of a single hardware layer. There are three approaches to creating a data warehouse layer: Single-tier, two-tier, and three-tier.
Confused about your next job?
Single-tier architecture: A single-layer structure aimed at keeping data space minimal. This structure is rarely used in real life.
Two-tier architecture: Data warehouse is the aggregation of data in a format that is easy to transform and load into a database. Data warehouses can be implemented in a number of different ways, and it is important to pick the right one for your business needs. The most important thing to consider is scalability. If you want to store large amounts of data in a small amount of space, then you should consider using a data warehouse.
Three-Tier Data Warehouse Architecture: The Top, Middle, and Bottom Tiers of this Architecture of Data Warehouse are collectively referred to as the Top Tier.
- The bottom tier of the Datawarehouse is a relational database system. This database system typically contains a relational database system. Back-end tools clean, transform, and load data into this layer.
- A middle tier OLAP server is either ROLAP or MOLAP-based. It abstracts OLAP from the end user by serving as a middle tier OLAP server. Data warehouses that facilitate end-user interaction with the database and middle tier OLAP servers that abstract OLAP from the end user are known as middle tier OLAP servers.
- The front-end client layer of the top-tier is important because it is the first point of interaction with the data. It is where data is presented to the end user, and decisions are made with the data. The front-end client layer of top-tier must work with real-time data and must be able to process data quickly. It is also important to work with data that is in a format that top-tier can understand and use. Typically, top-tier data is in a relational database format, but it could be a file or a stream. Top-tier data must be well-structured, must be validated, and must be structured in a way that allows for easier data profiling and analytics.
Data Warehouse Architecture Properties
A data warehouse system must meet the following architectural features:
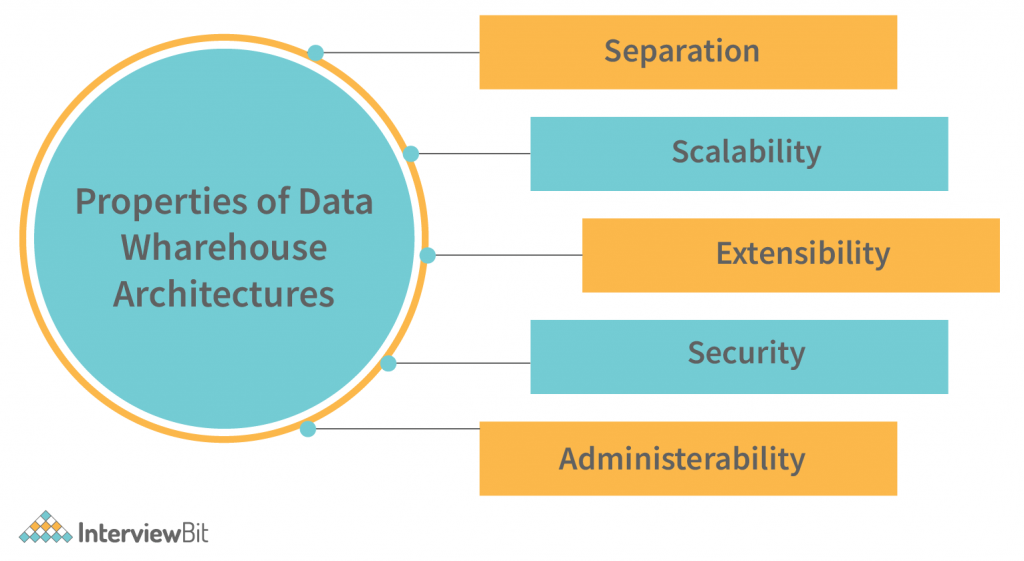
- We sometimes wish to keep analytical and transactional processing as far away as possible.
- The scalability of the solution should be demonstrated by the ability to process a huge volume of data and stream it to different destinations, at high speed, in various formats. The data stream should be processed and presented in the required format, at the right time and location, with the minimum impact to the existing infrastructure. The data stream must be protected and managed with the highest level of confidentiality and integrity. The size of the data stream and the rate at which the data is being generated must be determined by the business requirements, and the available hardware and software resources must be utilized to the fullest extent possible.
- The architecture should be extensible; new functionality can be implemented in an existing service by extending the service’s APIs. For example, an insurance company could extend their customer service platform to provide a new feature that allows customers to obtain a personalized quote based on their preferences. Newer technologies, such as artificial intelligence, can be implemented in an existing service by extending the service’s APIs. For example, an insurance company could extend their customer service platform to provide a new feature that allows customers to obtain a personalized quote based on their preferences. Newer technologies, such as artificial intelligence, should be implemented in the core services; the core services can be extended for new business functions, such as customer relationship management.
- Data security is a critical aspect of the data governance strategy. Data security controls at the source include establishing data access controls and data encryption. Data security controls at the perimeter include data security policies and monitoring access to the data.
- It should be simple and straightforward, and users should be able to work with the data in an efficient and effective manner. Data Warehouse management should be easy to understand and implement. Data Warehouse management should not be complicated and difficult for beginners should not find their way into data warehouse management. It should be simple to use and easy to understand.
Types of Data Warehouse Architectures
There are basically three different data warehouse architectures.
Single-Tier Architecture
Single-tier architectures are not implemented in real-time systems. They are used for batch and real-time processing. The data is first transferred to a single-tier architecture where it is converted into a format that is suitable for real-time processing. This architecture is known as “single-threaded”. After this, the data is transferred to a real-time system. Single-tier architectures are currently the most preferred way to process operational data. It is important to note that single-tier architectures are not implemented in real time systems.
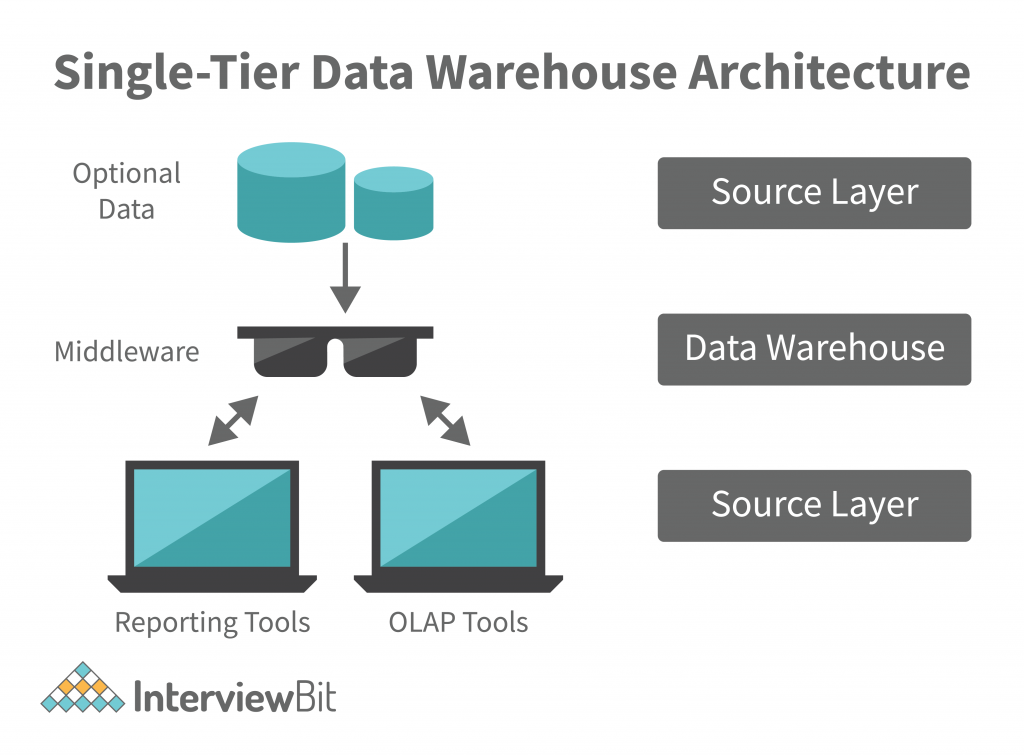
The data storage and processing middleware should be able to determine the quality of the data before the data is accepted by the analytical engine and transformed into relevant information. If these steps are not performed, then the middleware can be penetrated by malicious or faulty code. As an example, consider a credit score calculation. If a malicious hacker controls the middleware, then the hacker can modify the score and extract valuable data.
Two-Tier Architecture
In a two-tier data warehouse, an analytical process is separated from a business process. This allows for greater levels of control and efficiency. A two-tier system also provides a better understanding of the data and allows for more informed decisions.
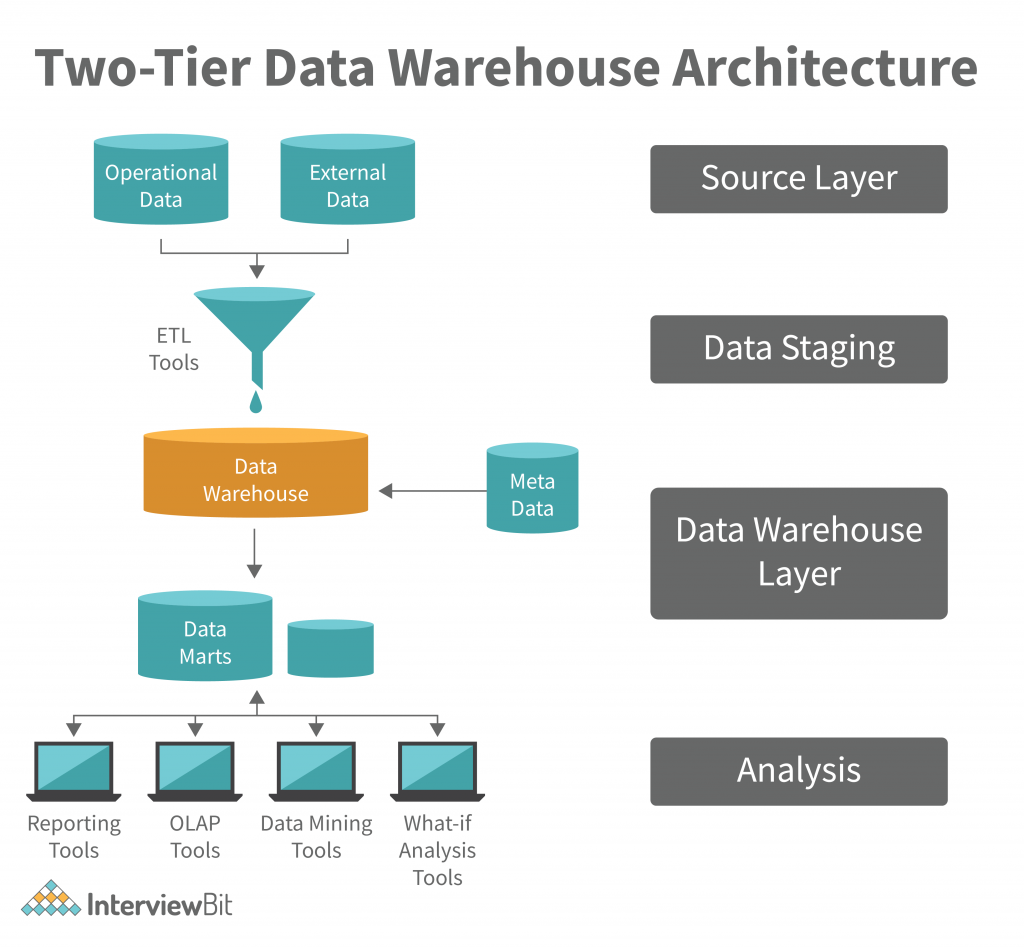
Two-layer architecture describes a four-stage data flow in which physical sources are separated from data warehouses by a two-layered architecture.
- The source of the data is critical to the data warehouse’s integrity. The integrity of the data stored in the data warehouse must be guaranteed. Data integrity is the degree to which data values in a database record are true or accurate. A data warehouse is a system that stores information in a database so that it can be searched and analyzed.
- Data staging is a key process in the ETL process, and one that can significantly reduce the time it takes to extract, transform, and load (ETL) a large data set. ETL tools can extract data from various storage sources, transform the data with corporate-specific functions, and load the data into a data warehouse. Data warehouse functions such as monitoring the system, provisioning new data, and making decisions on the basis of the data are all done through data warehouse functions such as ETL. Data warehouse functions such as ETL can be implemented through a data warehouse.
- Data warehouse metadata is a critical component of the data warehouse. It is the information that helps a data warehouse administrator decide which data to delete, which data to retain, and which data to use in future reports. It is also important to maintain data warehouse consistency. Data warehouse administrators must determine which data should be updated or deleted when new data arrives, and which data should be left untouched. When data warehouse consistency is not guaranteed, application developers and users must be careful about which tables and reports they create.
- Data profiling is also very important for this level as it helps in validating data integrity and presentation standards. It also comes with advanced analytics such as real-time and batch reporting, data profiling and visualizations, and rating functions. It is important to keep in mind that this is not just a data warehouse but a live data platform that receives and analyzes massive amounts of data. This is why it is important to keep track of data changes, scalability, and performance of the system.
Three-Tier Architecture
A three-tier structure is employed in the source layer, the reconciled layer, and the data warehouse layer. The reconciled layer sits between the source data and data warehouse. The main disadvantage of the reconciled layer is the fact that it is not possible to completely ignore the problems of the data before it is reconciled. Therefore, the main focus of the reconciler should be on data integrity, accuracy, and consistency. For example, assume that the data warehouse contains a collection of company data elements that are updated frequently, such as order book information. In such a case, the best approach would be to use a web-based data warehouse refresh tool, which extracts the latest data from the data warehouse and refreshes the data in the corporate application. This architecture is appropriate for systems with a long-life cycle. Whenever a change occurs in the data, an extra layer of data review and analysis is done to ensure that no erroneous data was entered. This architecture is also known as data-driven architecture. This structure is mainly used for large-scale systems. It is important to note that the extra layers of data review and analysis created by this structure does not consume any extra space in the storage device.
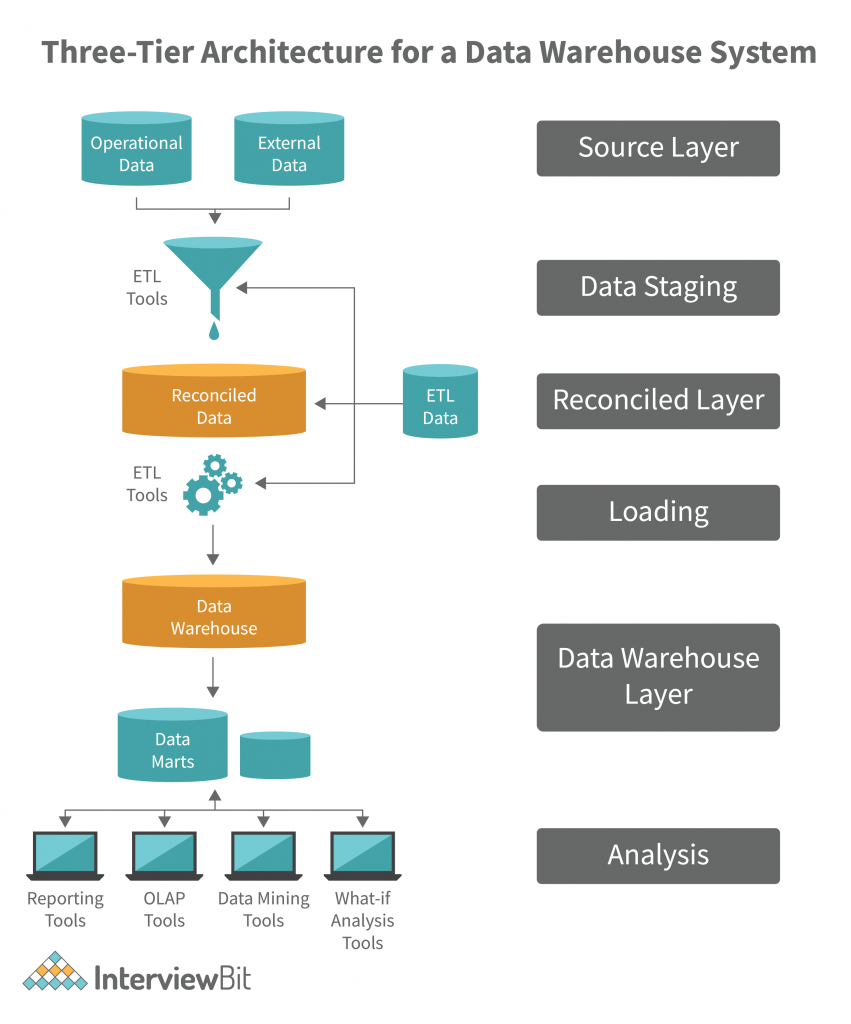
Advantages of Data WarehouseArchitecture
- The data mart is a collection of data model definitions that captures the data model at a high level and provides a common data access strategy for the data warehouse. The data mart provides a common data access strategy for the data warehouse, consistency, and governance from one location to manage the diverse data sources. The data mart is an important building block for the data warehouse. It provides a way to standardize data access, create a common strategy for data integration, and make the data model available for data profiling and analytics. The data mart does not create data – it only provides the data access strategy.
- The process of change starts with identifying the problems and pain points of your current system, and then mapping out a plan to solve those problems using the new system. After that, the system is tested to make sure that everything is working as expected. Once the system is deemed fit for purpose, the process of change starts. The first thing is to make sure that the existing stakeholders are comfortable with the new system. Then, the process of change has to be validated by conducting an assessment. This is how the model is considered the most appropriate for business transformation.
- There is a good reason why over 90% of the data businesses collect is in the form of data warehouses. Data warehouses are huge collections of data, usually stored in a database, that are used to help make business decisions. Many data warehouses are designed to support ETL processes and deliver data to a CRM system so that business users can start looking at actual data and make decisions.
- With a data warehouse, you can also take advantage of ETL (extract, transform, and load) and ETL management processes to connect your data sources and process them together. In other words, a data warehouse is a central repository of your data that can be accessed by any of your analytic platforms.
- Data warehouses have increased in speed and scale with the adoption of NoSQL databases, like MongoDB or GARIA. When implemented in conjunction with a BI platform, data warehouse technology enables real-time analytics, enabling the streamlining of decision making, the reduction of lead and invoice inquiries, and increased profitability.
Disadvantages of Data Warehouse Architecture
- The maintenance of a data warehouse is a crucial task which needs to be done well. For a data warehouse to be maintained, there is a need to collect data, process it, and then analyze it. However, data collection, processing, and analysis need to be done within a certain timeframe. The maintenance of a data warehouse requires a great deal of effort, which may not be justified by the returns on investment. However, a data warehouse can be a critical component of an enterprise data management system.
- To speed up the process and minimize the time required for extracting data, you can leverage some ETL tools to automate the process. However, automated extraction does not guarantee that the data is properly cleaned and validated. It is best to do both manually and manually-enforced tasks in sequence. When the data has been validated and the cleanup process has been automated, the data is ready for ingestion into the warehouse.
- Such an omission might result in incorrect assessment of the property value, over estimation of expenses, or under estimation of sales. Data integration is essential for any organization that processes large amounts of data. It must be ensured that all required data is integrated in the warehouse. This can be done by using data trapping or data mining techniques.
- The majority of the data will be stored in a warehouse and analyzed using data profiling tools. The warehouse infrastructure will be required to support the analysis of massive amounts of data and the storage of the data in the most cost-effective manner. The warehouse will act as a repository for the data and will be the central depository for all data analysis tools.
- However, with the right approach, an organization can achieve better results by working with data warehouse tools in a disciplined and structured fashion. One important aspect of a data warehouse’s architecture that must be carefully considered is the data source. If the data comes from multiple sources such as external sources such as sensors or authorized partners, then data integration is even more important. An organization must first decide which sources of data it wants to work with and then work to integrate these data sources.
Conclusion
A data warehouse architecture is a set of interconnected databases that stores, organizes, and analyzes data. A data warehouse is a collection of databases that stores and organizes data in a systematic way. A data warehouse architecture consists of three main components: a data warehouse, an analytical framework, and an integration layer. The data warehouse is the central repository for all the data. The analytical framework is the software that processes the data and organizes it into tables. The integration layer is the software that connects the databases together and makes them accessible to other applications. A data warehouse architecture is an important part of any IT infrastructure because it helps to optimize the performance of the entire system. By organizing and storing all the data in one place, a data warehouse can make it easier to find, access, and analyze it. In addition, a well-designed data warehouse architecture can help to reduce costs by reducing the amount of redundant storage space required. In addition, a well-designed data warehouse architecture can help to reduce costs by reducing the amount of redundant storage space required.

