











 Download PDF
Download PDF






Machine data has increased exponentially over the past decade, thanks to the advent of IoT devices and the increasing number of machines in the IT infrastructure. Machine data contains a significant amount of valuable business-critical information that can enhance efficiency, productivity, and visibility. This is where Splunk comes in.
Splunk was founded in 2003 to derive insights and information from large volumes of machine data, and since then, Splunk's skills have become increasingly sought-after. The tool is one of the top DevOps solutions on the market, and so are its experts. Therefore, to secure a Splunk job, you must be capable of acing the interview.
Don't worry, we’ve compiled the list of top Splunk interview questions and answers that can help you not only improve your Splunk skills but also land the job you are looking for. Let's first understand what Splunk is.
What is Splunk?
Splunk is basically a software platform that provides users with the ability to access, analyze, and visualize machine-generated data from multiple sources, including hardware devices, networks, servers, IoT devices, and other sources. The machine data is analyzed and processed, and subsequently transformed into powerful operational intelligence that offers some real-time insight. It is widely used to search, visualize, monitor, and report enterprise data. Among Splunk's many capabilities are application management, security and compliance, business and web analytics, etc.

Splunk relies on its indexes to store all of its data, so it does not need any database to do so. Splunk gathered all relevant information into one central index, making it easy to search for specific data within a massive amount of data. Moreover, machine data is extremely important for monitoring, understanding, and optimizing machine performance.
In this article, we have created a list of Splunk interview questions and answers for Freshers and Experienced candidates so you can prepare for your job interview and move closer to achieving your dream career.
Splunk Interview Questions for Freshers
1. What is Splunk used for?
In general, machine data is difficult to understand and has an unstructured format (not arranged as per pre-defined data model), making it unsuitable for analysis and visualization of data. Splunk is the perfect tool for tackling such problems. Splunk is used to analyze machine data for several reasons:

- Provides business insights: The Splunk platform analyzes machine data for patterns and trends, providing operational insights that assist businesses in making smarter decisions for the profitability of the organization.
- Enhances operational visibility: Splunk obtains a comprehensive view of overall operations based on machine data and then aggregates it across the entire infrastructure.
- Ensures proactive monitoring: Splunk employs a real-time analysis of machine data to discover system errors and vulnerabilities (external/internal breaches and intrusions).
- Search and Investigation: Splunk uses machine data to pinpoint and fix problems by correlating events across numerous data sources and detecting patterns in large datasets.


 Real-Life Problems
Real-Life Problems
 Prep for Target Roles
Prep for Target Roles
 Custom Plan Duration
Custom Plan Duration
2. Can you explain how Splunk works?
In order to use Splunk in your infrastructure, you must understand how Splunk performs on the internal level. In general, Splunk processes data in three stages:
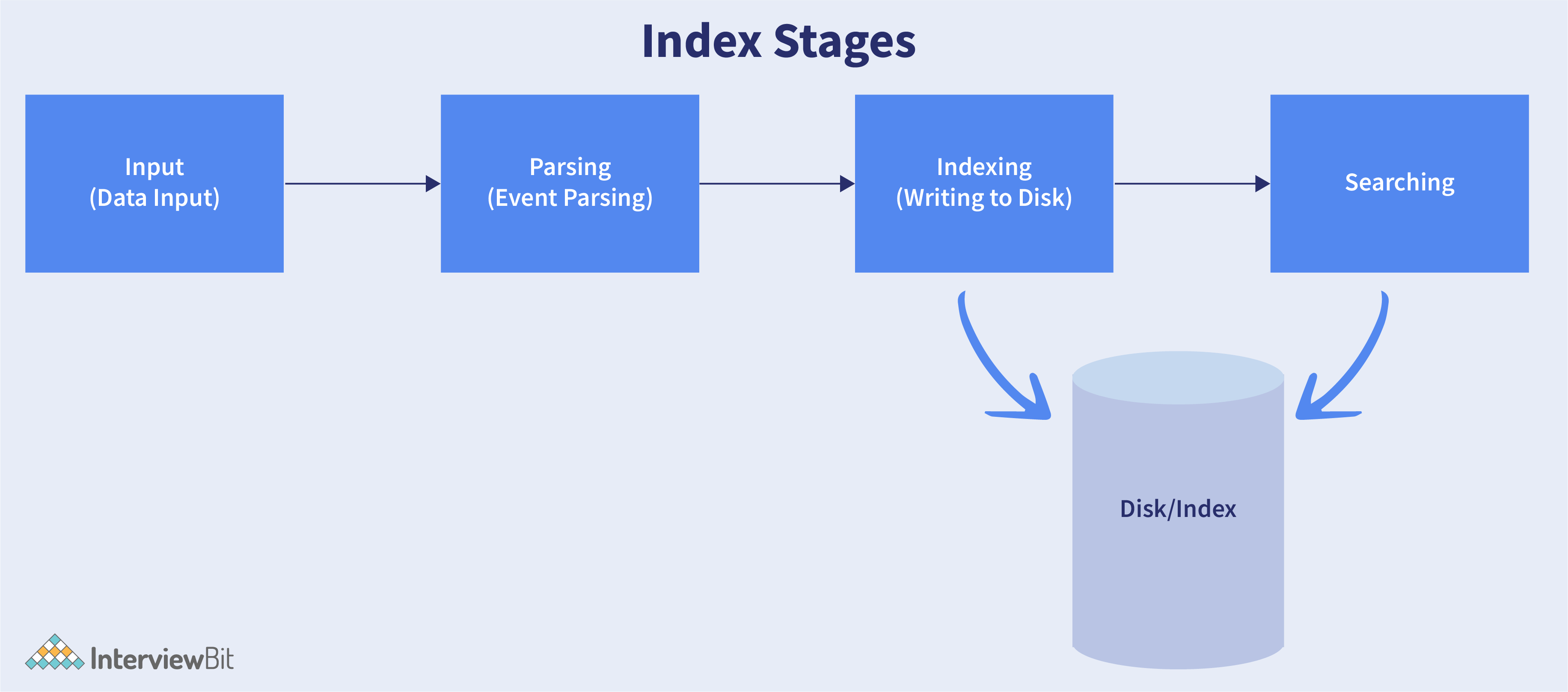
- Data Input Stage: This stage involves Splunk consuming raw data not from a single, but from many sources, breaking it up into 64K blocks, and annotating each block with metadata keys. A metadata key includes the hostname, source, and source type of the data.
-
Data Storage Stage: In this stage, two different phases are performed, Parsing and Indexing.
- In the Parsing phase, Splunk analyzes the data, transforms it, and extracts only the relevant information. This is also called "event processing," since it breaks down the data sets into different events.
- During the indexing phase, Splunk software writes the parsed events into the index queue. One of the main benefits of using this is to make sure the data is easily accessible for anyone during the search.
- Data Searching Stage: This stage usually controls how the index data is accessed, viewed, and used by the user. Reports, event types, dashboards, visualization, alerts, and other knowledge objects can be created based on the user's reporting requirements.
3. What are the main components of Splunk Architecture?
As shown below, Splunk Architecture is composed of three main components:

- Splunk Forwarder: These are components that you use to collect machine data/logs. This is responsible for gathering and forwarding real-time data with less processing power to Indexer. Splunk forwarder performs cleansing of data depending on the type of forwarder used (Universal or Heavy forwarder).
- Splunk Indexer: The indexer allows you to index i.e., transform raw data into events and then store the results data coming from the forwarder. Incoming data is processed by the indexer in real-time. Forwarder transforms data into events and stores them in indexes to enable search operations to be performed efficiently.
- Search Head: This component is used to interact with Splunk. It lets users perform various operations like performing queries, analysis, etc., on stored data through a graphical user interface. Users can perform searches, analyze data, and report results.
4. Write different types of Splunk forwarder.
A forwarder is a Splunk instance or agent you deploy on IT systems, which collects machine logs and sends them to the indexer. You can choose between two types of forwarders:
- Universal Forwarder: A universal forwarder is ideal for sending raw data collected at the source to an indexer without any prior processing. Basically, it's a component that performs minimal processing before forwarding incoming data streams to an indexer. Although it is faster, it also results in a lot of unnecessary information being forwarded to the indexer, which will result in higher performance overhead for the indexer.
- Heavy Forwarder: You can eliminate half of your problems using a heavy forwarder since one level of data processing happens at the source before forwarding the data to the indexer. Parsing and indexing take place on the source machine and only data events that are parsed are sent to the indexer.

5. What are the advantages of getting data into a Splunk instance through Forwarders?
Data entering into Splunk instances via forwarders has many advantages including bandwidth throttling, a TCP connection, and an encrypted SSL connection between the forwarder and indexer. By default, data forwarded to the indexers are also load-balanced, and if one indexer goes down for any reason, that data can always be routed to another indexer instance in a very short amount of time. Furthermore, the forwarder stores the data events locally before forwarding them, creating a temporary backup of the data.

6. What do you mean by Splunk Dashboards and write its type?
In a dashboard, tables, charts, event lists, etc., are used to represent data visualizations, and they do so by using panels. Dashboard panels present or display chart data, table data, or summarized data visually in a pleasing manner. On the same dashboard, we can add multiple panels, and therefore multiple reports and charts. Splunk is a popular data platform with lots of customization options and dashboard options.
There are three kinds of the dashboard you can create with Splunk:
- Dynamic form-based dashboards: They allow Splunk users to change the dashboard data based on values entered in input fields without leaving the page. A dashboard can be customized by adding input fields (such as time, radio buttons, text boxes, checkboxes, dropdowns, and so on) that change the data, depending on the selection made. Dashboards of this type are useful for troubleshooting issues and analyzing data.
- Static Real-time Dashboards: They are often displayed on a large screen for constant viewing. It also provides alerts and indicators to prompt quick responses from relevant personnel.
- Scheduled Dashboards: These dashboards can be downloaded as PDF files and shared with team members at predetermined intervals. There are times when active live dashboards can only be viewed by certain viewers/users only.
Some of the Splunk dashboard examples include security analytics dashboard, patient treatment flow dashboard, eCommerce website monitoring dashboard, exercise tracking dashboard, runner data dashboard, etc.
7. Explain Splunk Query.
Splunk queries allow specific operations to be run on machine-generated data. Splunk queries communicate with a database or source of data by using SPL (Search Processing Language). This language contains many functions, arguments, commands, etc., that can be used to extract desired information from machine-generated data. This makes it possible for users to analyze their data by running queries. Similar to SQL, it allows users to update, query, and change data in databases.
It is primarily used to analyze log files and extract reference information from machine-generated data. In particular, it is beneficial to companies that have a variety of data sources and need to process and analyze them simultaneously in order to produce real-time results.


 Topic Buckets
Topic Buckets
 Mock Assessments
Mock Assessments
 Reading Material
Reading Material
 Earn a Certificate
Earn a Certificate
8. What are different types of Splunk License?
A license is required for each Splunk instance. With Splunk, you receive a license that specifies which features you can use and how much data can be indexed. Various Splunk License types include:
- The Splunk Enterprise license: Among all Splunk license types, Enterprise licenses are the most popular. These licenses give users access to all the features of Splunk Enterprise within a specified limit of indexed data or vCPU usage per day. These licenses include enterprise features such as authentication and distributed search. Several types of Splunk Enterprise licenses are available, including the Splunk for Industrial IoT license and Splunk Enterprise Trial license.
- The Free license: Under the Free license, Splunk Enterprise is completely free to use with limited functionality. Some features are not available under this license, such as authentication. Only a limited amount of data can be indexed.
- The Forwarder license: A Forwarder license enables unlimited forwarding of data, as well as a subset of the Splunk Enterprise features that are required for authentication, configuration management, and sending data.
- The Beta license: Each Splunk beta release requires a separate beta license, which cannot be used with other Splunk releases. With a beta license, Splunk Enterprise features are enabled for a specific beta release period.
9. What is the importance of License Master in Splunk? If the License Master is not reachable, what will happen?
It is the responsibility of the license master in Splunk to ensure that the limited amount of data is indexed. Since each Splunk license is based on the amount of data that is coming into the platform in 24 hours, it is essential to keep the environment within the limits of its purchased volume.
Whenever the license master becomes unavailable, it is simply impossible to search the data. Therefore, only searching remains halted while the indexing of data continues. Data entering the Indexer won't be impacted. Your Splunk deployment will continue to receive data, and the Indexers will continue to index the data as usual. However, upon exceeding the indexing volume, you will receive a warning message on top of your Search head or web interface so that you can either reduce your data intake or purchase a larger capacity license.
10. Explain License violation. How will you handle or troubleshoot a license violation warning?
License violations occur after a series of license warnings, and license warnings occur when your daily indexing volume exceeds the license's limit. Getting multiple license warnings and exceeding the maximum warning limit for your license will result in a license violation. With a Splunk commercial license, users can receive five warnings within a 30-day period before Indexer stops triggering search results and reports. Users of the free version, however, will only receive three warnings.

Avoid License Warning:
- Monitor your license usage over time and ensure that you have enough license volume to meet your daily needs.
- Viewing the license usage report in the license master can help troubleshoot index volume.
- In the monitoring console, set up an alert to track daily license usage.
Troubleshoot License Violation Warning:
- Determine which index/source type recently received more data than usual.
- Splunk Master license pool-wise quotas can be checked to identify the pool for which the violation occurred.
- Once we know which pool is receiving more data, then we need to determine which source type is likely to be receiving more than normal data.
- Having identified the source type, the next step is to find out which machine is sending so many logs and the reason behind it.
- We can then troubleshoot the problem accordingly.
11. Write down some common Splunk ports.
The following are common ports used by Splunk:
- Web Port: 8000
- Management Port: 8089
- Network port: 514
- Index Replication Port: 8080
- Indexing Port: 9997
- KV store: 8191
12. Explain Splunk Database (DB) Connect.
Splunk Database (DB) Connect is a general-purpose SQL (Structured Query Language) database extension/plugin for Splunk that permits easy integration between database information and Splunk queries/reports. Splunk DB Connect is effectively used to combine structured data from databases with unstructured machine data, and Splunk Enterprise can then be used to uncover insights from the combined data.
Some of the benefits of using Splunk Database Connect connect are as follows:
- By using Splunk DB Connect, you are adding new data inputs for Splunk Enterprise, i.e., adding additional sources of data to Splunk Enterprise. Splunk DB Connect lets you import your database tables, rows, and columns directly into Splunk Enterprise, which then indexes them. Once that relational data is within Splunk Enterprise, you can analyze and visualize it the same way you would any other Splunk Enterprise data.
- In addition, Splunk DB Connect enables you to write your Splunk Enterprise data back to your relational databases.
- With DB Connect, you can reference fields from an external database that match fields in your event data, using the Database Lookup feature. This way, you can enrich your event data with more meaningful information.

 Interview Process
Interview Process
 CTC & Designation
Projects on the Job
CTC & Designation
Projects on the Job
 2 Lakh+ Roadmaps Created
2 Lakh+ Roadmaps Created
13. What are different versions of the Splunk product?
Splunk products come in three different versions as follows:
- Splunk Enterprise: A number of IT companies use Splunk Enterprise. This software analyzes data from diverse websites, applications, devices, sensors, etc. Data from your IT or business infrastructure can be searched, analyzed, and visualized using this program.
- Splunk Cloud: It is basically a SaaS (Software as a Service) offering many of the same features as enterprise versions, including APIs, SDKs, etc. User logins, lost passwords, failed login attempts, and server restarts can all be tracked and sorted.
- Splunk Light: This is a free version of Splunk which allows you to view, search, and edit your log data. This version has fewer capabilities and features than other versions.
14. Name some of the features that are not available in the Splunk free version.
The free version of Splunk lacks the following features:
- Distributed searching
- Forwarding of data through HTTP or TCP (to non-Splunk)
- Agile reporting and statistics based on a real-time architecture
- Scheduled searches/alerts and authentication
- Managing deployments.
15. Explain Splunk alerts and write about different options available while setting up alerts.
Splunk alerts are actions that get triggered when a specific criterion is met; these conditions are defined by the user. You can use Splunk Alerts to be notified whenever anything goes awry with your system. For instance, the user can set up Alerts so that an email notification will be sent to the admin when three unsuccessful login attempts are made within 24 hours.
The following options are available when setting up alerts:
- A webhook can be created to send messages to Hipchat or Github. With this email, you can send a message to a group of machines along with a subject, priority, and message body.
- Results can be attached as .csv files, pdf files, or inline with the message body to ensure the recipient understands what alerts have been fired, at what conditions, and what actions have been taken.
- You can also create tickets and control alerts based on conditions such as an IP address or machine name. As an example, if a virus outbreak occurs, you do not want every alert to be triggered as it will create a lot of tickets in your system, which will be overwhelming. Such alerts can be controlled from the alert window.
16. What do you mean by Summary Index in Splunk?
Summary indexes store analyses, reports, and summaries computed by Splunk. This is an inexpensive and fast way to run a query for a long period of time. Essentially, it is the default index that Splunk Enterprise uses if there isn't another one specified by the user. Among the key features of the Summary Index is that you can retain the analytics and reports even after the data has gotten older.
17. What is the way to exclude certain events from being indexed by Splunk?
In the case where you do not wish to index all of your events in Splunk, what can you do to prevent the entry of those events into Splunk? Debug messages are a good example of this in your application development cycle.
Such debug messages can be excluded by putting them in the null queue. This is achieved by specifying a regex that matches the necessary events and sending the rest to the NULL queue. Null queues are defined at the forwarder level in transforms.conf. Below is an example that drops all events except those containing the debug message.
In props.conf
[source::/var/log/foo]
#By applying transforms in this order
#events will be dropped to the floor
#before being routed to the index processor
TRANSFORMS-set = setnull, setparsing In transforms.conf
[setnull]
REGEX = .
DEST_KEY = queue
FORMAT = nullQueue
[setparsing]
REGEX = debugmessage
DEST_KEY = queue
FORMAT = indexQueue18. Write the commands used to start/stop the Splunk service.
The following commands can be used to start and stop Splunk services:
- Start Splunk service
./splunk start - Stop Splunk service
./splunk stop - Restart Splunk service ./
splunk restart
19. What is the importance of time zone property in Splunk?
A time zone is a crucial factor to consider when searching for events from a fraud or security perspective. This is because Splunk uses the time zone defined by your browser. Your browser then picks up the time zone associated with the machine/computer system you're working on. So, you will not be able to find your desired event if you search for it in the wrong time zone. The timezone is picked up by Splunk when data is entered, and it is particularly important when you are searching and comparing data from different sources. You can, for instance, look for events coming in at 4:00 PM IST, for your London data centre, or for your Singapore data centre, etc. The timezone property is therefore vital when correlating such events.
20. State difference between Splunk app and add-on.
Generally, Splunk applications and add-ons are separate entities, but both have the same extension, i.e., SPL files.
-
Splunk Apps: A Splunk app extends Splunk functionality with its own inbuilt user interface. Each of these apps are separate and serves a specific purpose. Each Splunk app consists of a collection of Splunk knowledge objects (lookups, tags, saved searches, event types, etc). They can also make use of other Splunk apps or add-ons. Multiple apps can be run simultaneously in Splunk. Several apps offer the option of restricting or limiting the amount of information a user can access. By controlling access levels, the user has access to only the information that is necessary for him and not the rest. You can open apps from the Splunk Enterprise homepage or through the App menu or in the Apps section of the Settings page.
Example: Splunk Enterprise Security App, etc. -
Splunk Add-on: These are types of applications that are built on top of the Splunk platform that add features and functionality to other apps, such as allowing users to import data, map data, save searches, macros. Add-ons typically do not run as standalone apps, rather they are reusable components that support other apps in different scenarios. Most of the time, it is used as a framework, where a team leverages its functionality to some extent and creates something new on top of it. As a rule, they do not have navigable user interfaces. You cannot open an Add-on from the Splunk Enterprise homepage or app menu.
Examples: Splunk Add-on for Checkpoint OPSEC LEA, Splunk Add-on for EMC VNX or the Splunk Common Information Model Add-on.
21. Mention some important configuration files in Slunk.
Configuration files that are of the utmost importance in Splunk are:
- Props.conf: It configures indexing properties, such as timezone offset, pattern collision priority, custom source type rules, etc.
- Indexes.conf: It configures and manages index settings.
- Inputs.conf: It is used to set up data inputs.
- Transforms.conf: It can be used to configure regex transformations to be performed on data inputs.
- Server.conf: There are a variety of settings available for configuring the overall state of the Splunk Enterprise instance.
Splunk Interview Questions for Experienced
1. State difference between Search head pooling and Search head clustering.
Splunk Enterprise instances, also called search heads, distribute search requests to other instances called search peers, that performs the actual data searching and indexing. Results are merged and returned to the user by the search head. You can implement Distributed Search using Search head pooling or Search head clustering in your Splunk deployment.
- Search head pooling: Pooling refers to sharing resources in this context. It uses shared storage for configuring multiple search heads to share user data and configuration. Quite simply, it allows you to have multiple search heads so they share user data and configuration. Multiplying search heads facilitate horizontal scaling when a lot of users are searching the same data.
- Search head clustering: In Splunk Enterprise, a search head cluster is a collection of search heads that are used as a centralized resource for searching. All members of the cluster can access and run the same searches, dashboards, and search results.
2. Name the commands used to enable and disable Splunk boot start.
In order to enable Splunk boot-start, we need to use the following command: $SPLUNK_HOME/bin/splunk enable boot-start
In order to disable Splunk boot-start, we need to use the following command: $SPLUNK_HOME/bin/splunk disable boot-start
Conclusion
Are you looking for a new job or trying to build a career in Splunk? There is no doubt that implementing Splunk will transform your business and catapult it to new heights. Therefore, prepare yourself for the most intense job interview because the competition is fierce.
Splunk consultants, Splunk developers, Splunk engineers, Splunk specialists, Information security analysts, etc., are in demand. A Splunk career requires knowledge of architectural and configuration points, Splunk files, indexers, forwarders, and others. Hopefully, these Splunk interview questions will assist you in getting into the flow and preparing for your interview.
Useful Resources:
3. Name the commands used to restart Splunk Web Server and Splunk Daemon.
In order to restart the Splunk Web Server, we need to use the following command: splunk start splunkweb.
In order to restart the Splunk Daemon, we need to use the following command: splunk start splunkd.
4. Explain how Splunk avoids duplicate indexing of logs.
Essentially, Splunk Fishbucket is a subdirectory within Splunk that is used to monitor and track the extent to which the content of a file has been indexed within Splunk.
The default location of the fish bucket subdirectory is: /opt/splunk/var/lib/splunk
It generally includes seeking pointers and CRCs (cyclic redundancy checks) for the files we are indexing so that Splunk knows whether it has already read them.
5. How to reset Splunk Admin (Administrator) password?
Depending on your Splunk version, you can reset the Admin password. In case you have Splunk 7.1 and higher version, then you need to follow these steps:
- Splunk Enterprise must be stopped first.
- Find and rename ‘passwd’ file to ‘passwd.bk’.
- In the below directory, create a file named 'user-seed.conf':
$SPLUNK_HOME/etc/system/local/- Enter the following command in the file. 'NEW_PASSWORD' will be replaced by our own new password here.
[user_info]
PASSWORD = NEW_PASSWORD- Restart Splunk Enterprise and log in with the new password again.
If you're using a version prior to 7.1, you need to follow these steps:
- Splunk Enterprise must be stopped first.
- Find and rename ‘passwd’ file to ‘passwd.bk’.
- Use the default credentials of admin/changeme to log in to Splunk Enterprise.
- If you're asked to change your admin username and password, just follow the instructions.
6. What is the best way to clear Splunk's search history?
The following file on the Splunk server needs to be deleted in order to clear Splunk search history: $splunk_home/var/log/splunk/searches.log.
7. Explain how will you set default search time in Splunk 6.
Using 'ui-prefs.conf' in Splunk 6, we can specify the default search time. If we set the value as follows, all users would see it as the default setting: $SPLUNK_HOME/etc/system/local
For example, if our $SPLUNK_HOME/etc/system/local/ui-prefs.conf file Includes
[search]
dispatch.earliest_time = @d
dispatch.latest_time = nowThe default time range that will appear to all users in the search app is today.
8. What do you mean by buckets? Explain Splunk bucket lifecycle?
A bucket is a directory in which Splunk stores index data. Each bucket contains data events in a particular time frame. As data ages, buckets move through different stages as given below:
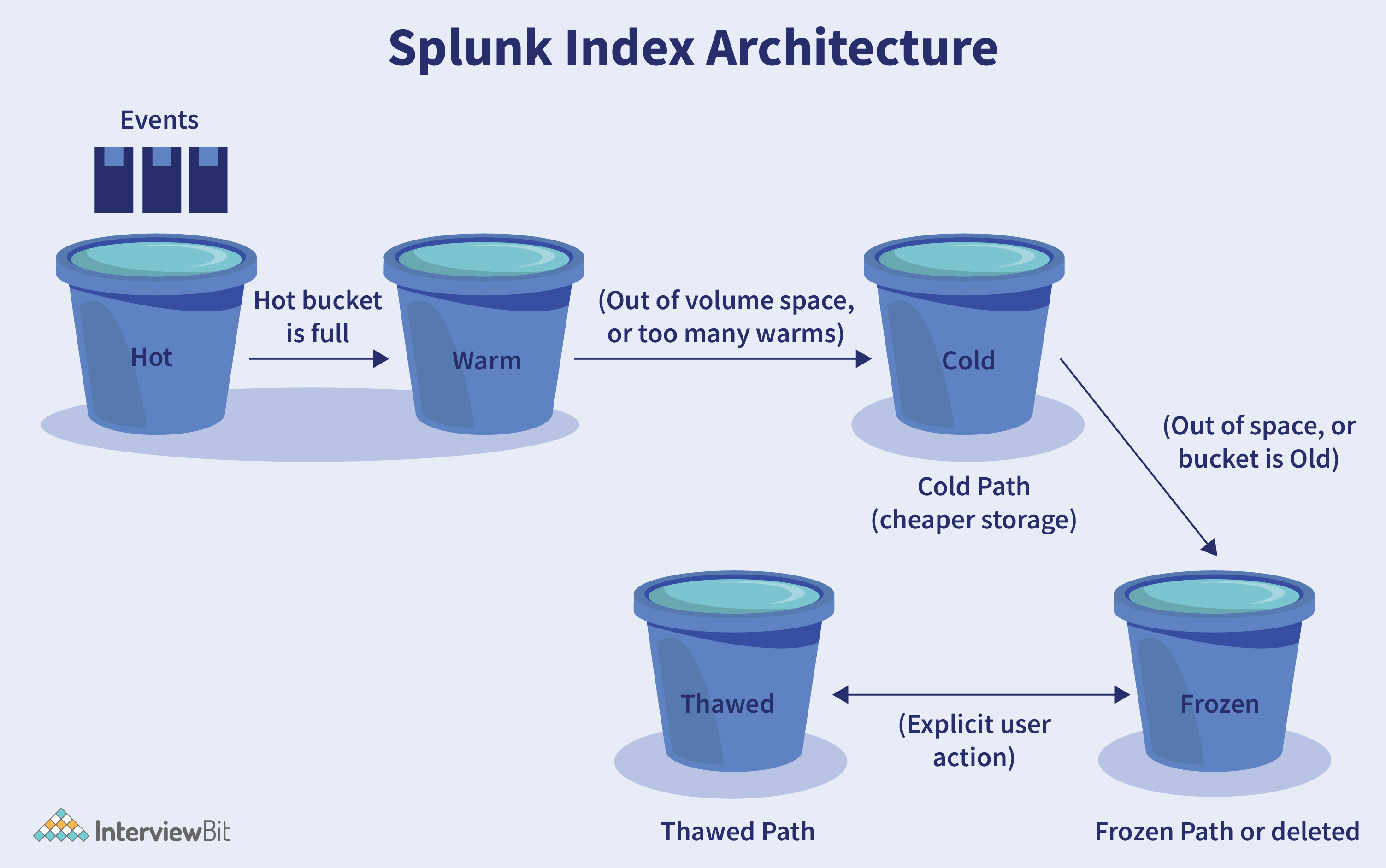
- Hot bucket: Newly indexed data is present in a hot bucket. Every index contains one or more hot buckets, and every index is open for writing.
- Warm bucket: This bucket contains data that has been rolled or pulled out of the hot bucket. The warm buckets are numerous.
- Cold bucket: This bucket contains data that has been rolled or pulled out of the warm bucket. The cold buckets are numerous.
- Frozen bucket: This bucket contains data that has been rolled or pulled out of the cold bucket. By default, the indexer removes frozen data, but we can archive it.
Buckets are by default located in:$SPLUNK_HOME/var/lib/splunk/defaultdb/db.
9. Explain what is a fish bucket and fish bucket index.
Essentially, Splunk Fishbucket is a subdirectory within Splunk that is used to monitor and track the extent to which the content of a file has been indexed within Splunk. For this feature, there are two types of contents: seek pointers and CRCs (cyclic redundancy checks).
The default location of the fish bucket subdirectory is: /opt/splunk/var/lib/splunk.
You can find it through the GUI (Graphical User Interface) by searching for: index=_thefishbucket.
10. What do you mean by SF (Search Factor) and RF (Replication Factor)?
SF (Search Factor) & RF (Replication Factor) are terms associated with Clustering techniques i.e., Search head clustering & Indexer clustering.
- Search Factor: It is only associated with indexer clustering. It determines how many searchable copies of data the indexing cluster maintains. By default, the value of the search factor is 2.
- Replication Factor: It is associated with both Search head clustering & Indexer clustering. In the case of the indexer cluster, replication factor determines the number of copies of the data that an indexer cluster maintains, while in the case of the search head cluster, replication factor determines the minimum number of copies of the search artefacts that a search head cluster maintains. For the replication factor, the default value is 3.
11. What are Splunk commands and list out some of the basic Splunk commands?
Many Splunk commands are available, including those related to searching, correlation, data or indexing, and identifying specific fields. Following are some of the basic Splunk commands:

- Accum: Maintains a running total of a numeric field.
- Bucketdir: Replaces a field value with a higher-level grouping, just like replacing filenames with directories.
- Chart: Provides results in a tabular format for charting.
- Timechart: Creates a time series chart and the corresponding statistics table.
- Rare: Displays the values that are least common in a field.
- Cluster: Groups/clusters similar events together.
- Delta: Calculates the difference between two search results.
- Eval: Calculates the expression and stores the result in a field.
- Gauge: Converts the output result into a format compatible with gauge chart types.
- K-means: Perform K-means clustering for selected fields.
- Top: Shows/displays the most common values of a field that are mostly used.
12. Explain what is Dispatch Directory.
A directory is included in the Dispatch Directory for each search that is running or has been completed.
The Dispatch Directory is configured as follows:
$SPLUNK_HOME/var/run/splunk/dispatch Take the example of a directory named 14333208943.348. This directory includes a CSV file of all search results, a search.log containing details/information about the search execution, as well as other pertinent information. You can delete this directory within 10 minutes after the search is completed using the default configuration. Search results are deleted after seven days if you have saved them.
13. State difference between ELK and Splunk.
IT Operations professionals are familiar with Splunk and ELK (ElasticSearch, LogStash, and Kibana), two of the most widely used tools in the area of Operational Data Analytics.
ELK vs Splunk -

| ELK | Splunk |
|---|---|
| ELK is a powerful open-source enterprise platform that combines ElasticSearch, LogStash, and Kibana for searching, visualizing, monitoring, and analyzing machine data. | The Splunk product is a closed-source tool for searching, visualizing, monitoring, and analyzing machine data. |
| The elasticsearch tool integrates with Logstash and Kibana to operate similarly to Splunk. Additionally, it can also be integrated with many other tools, such as Datadog, Amazon, Couchbase, Elasticsearch Services, and Contentful, etc. | Additionally, Splunk integrates with several other tools, including Google Anthos, OverOps, Wazuh, PagerDuty, Amazon Guard Duty, etc. |
| Some of the largest companies worldwide use ElasticStack to store, analyze, search and visualize data, including Uber, Stack Overflow, Udemy, Shopify, Instacart, and Slank, etc. | In contrast, Splunk is used by a range of companies, including Starbucks, Craftbase, Intuit, SendGrid, Yelp, Rent the Runway, and Blend. |
| Wizards and features are not pre-loaded in Elasticsearch. Even so, it doesn't have an interactive user interface, so users must install a plugin or use Kibana with it. | It comes preloaded with wizards and features that are easy and reliable to use. They allow managers to manage resources efficiently. |
| The ELK stack includes Kibana for visualization. Additionally, Kibana offers the same visualization features as Splunk Web UI, such as line charts, tables, etc., that can be presented on a dashboard. | Splunk Web UI comes with flexible controls that you can use to edit, add, and remove components to your dashboard. XML (Extensible Markup Language) can even be used to customize the application and visualization components on mobile devices. |
14. What do you mean by File precedence in Splunk?
A developer, administrator, and architect all have to consider file precedence when troubleshooting Splunk. All Splunk configurations are saved in plain text .conf files. Almost every aspect of Splunk's behaviour is determined by configuration files. There can be multiple copies of the same configuration file in a Splunk platform deployment. In most cases, these file copies are layered in directories that might affect users, applications, or the overall system. If you want to modify configuration files, you must know how the Splunk software evaluates those files and which ones have precedence when the Splunk software runs or is restarted.
Splunk software considers the context of each configuration file when determining the order of directories to prioritize configuration files. Configuration files can either be operated in a global context or in the context of the current application/user.
Directory priority descends as follows when the file context is global:
- System local directory -- highest priority ->
- Application local directories ->
- Application default directories ->
- System default directory -- lowest priority
Directory priority descends from user to application to system when file context is current application/user:
- User directories for the current user -- highest priority ->
- Application directories for the currently running application (local, followed by default) ->
- Application directories for all the other applications (local, followed by default) -- for exported settings only ->
- System directories (local, followed by default) -- lowest priority
15. Explain what is Splunk Btool.
The btool command-line tool can be used to figure out what settings are set on a Splunk Enterprise instance, as well as to see where those settings are configured. Using the Btool command, we can troubleshoot configuration file issues.
Conf files, also called Splunk software configuration files, are loaded and merged together to create a functional set of configurations that can be used by Splunk software when executing tasks. Conf files can be placed/found in many different folders under the Splunk installation. Using the on-disk conf files, Btool simulates the merging process and creates a report displaying the merged settings.
16. What do you mean by the Lookup command? State difference between Inputlookup and Outputlookup commands.
Splunk lookup commands can be used to retrieve specific fields from an external file (e.g., Python script, CSV file, etc.) to get the value of an event.
- Inputlookup: Inputlookup can be used to search the contents of a lookup table (CSV lookup or a KV store lookup). It is used to take input. This command, for instance, could take the product price or product name as input and match it with an internal field like the product ID.
- Outputlookup: Conversely, the outputlookup command outputs search results to a specified lookup table, i.e., it places a search result into a specific lookup table.
17. Name the commands included in the "filtering results” category.
Below are the commands included in the "filtering results" category:
- Search: This command retrieves events from indexes or filters the results of the previous search command. Events can be retrieved from your indexes by using keywords, wildcards, quoted phrases, and key/value expressions.
- Sort: The search results are sorted based on the fields that are specified. The results can be sorted in reverse, ascending, or descending order. When sorting, the results can also be limited.
- Where: The 'where' command, however, filters search results using 'eval' expressions. When the 'search' command is used, it retains only those search results for which an evaluation was successful, while the 'where' command enables a deeper investigation of those search results. By using a 'search' command, one can determine the number of active nodes, but the 'where' command will provide a matching condition of an active node that is running a specific application.
- Rex: You can extract specific fields or data from your events using the 'rex' command. For instance, when you want to determine specific fields in an email id, like scaler@interviewbit.co, you can use the 'rex' command. This will distinguish scaler as the user ID, interviewbit.co as the domain, and interviewbit as the company. Rex allows you to slice, split, and break down your events however you like.
18. State difference between stats vs eventstats command.
- Stats: The Stats command in Splunk calculates statistics for every field present in your events (search results) and stores these values in newly created fields.
- Eventstats: Similar to the stats command, this calculates a statistical result. While the Eventstats command is similar to the Stats command, it adds the aggregate results inline to each event (if only the aggregate is relevant to that event).
19. Name a few important Splunk search commands
Splunk provides the following search commands:
- Abstract: It provides a brief summary of the text of the search results. It replaces the original text with the summary.
- Addtotals: It sums up all the numerical fields for each result. You can see the results under the Statistics tab. Rather than calculating every numeric field, you can specify a list of fields whose sum you want to compute.
- Accum: It calculates a running total of a numeric field. This accumulated sum can be returned to the same field, or to a new field specified by you.
- Filldown: It will generally replace NULL values with the last non-NULL value for the field or set of fields. Filldown will be applied to all fields if there is no list of fields given.
- Typer: It basically calculates the eventtype field for search results matching a specific/known event type.
- Rename: It renames the specified field. Multiple fields can be specified using wildcards.
- Anomalies: It computes the "unexpectedness" score for a given event. The anomalies command can be used to identify events or field values that are unusual or unexpected.
Splunk MCQ
A search request is processed by the __________.
How many basic components are there in Splunk architecture?
What are the types of Splunk licenses?
What command would you use to display the most common values in a specific field?
What command would you use to display the values that are least common in a field?
What features aren't available in Splunk Free?
What is the Splunk tool used for?
Which of the following is a type of Splunk Forwarder?
Which of the following is not a component of Splunk?
Which of the following is not a version of Splunk product?










