











 Download PDF
Download PDF






About Informatica:
Founded in 1993 and headquartered in Redwood City, California, Informatica is a software development company that provides its users with enterprise data integration and cloud data management solutions. The company provides products for ETL, data masking, data quality, data replication, data virtualization, master data management, etc. Its products were newly launched but quickly gained popularity.
Informatica, a powerful ETL tool developed by Informatica Corporation, is widely used by companies to build data warehouses. In the current era, Informatica is the most sought-after product worldwide, making it an excellent career prospect. Having a career with Informatica offers you plenty of opportunities and benefits that come with working for a leading organization.
Well, this was just a quick introduction to Informatica.
Here’s a comprehensive guide covering the most commonly asked interview questions with their answers and a few tips that can help you ace your Informatica Interview and land your dream job.
Informatica Basic Interview Questions
1. What do you mean by Enterprise data warehouse?
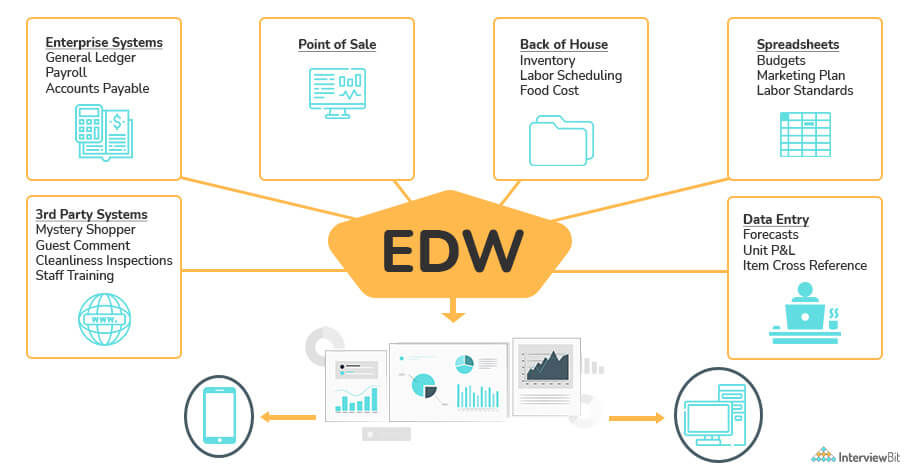
Data warehouses (DW) or Enterprise Data Warehousing (EDW), a form of the corporate repository, generally store and manage enterprise data and information collected from multiple sources. Enterprise data is collected and made available for analysis, business intelligence, to derive valuable business insights, and to improve data-driven decision-making. Data contained here can be accessed and utilized by users (with privileges) across the organization. With EDW, data is accessed through a single point and delivered to the server via a single source.


 Real-Life Problems
Real-Life Problems
 Prep for Target Roles
Prep for Target Roles
 Custom Plan Duration
Custom Plan Duration
2. What is target load order?
Target load order also referred to as Target load plan, is generally used to specify the order in which target tables are loaded by an integration service. Based on the source qualifier transformations in a mapping, you can specify a target load order. In Informatica, you can specify the order in which data is loaded into targets when there are multiple source qualifier transformations connected to multiple targets.
3. What is ETL (Extract, transform, Load) and write some ETL tools.
Essentially, ETL means to extract, transform, and load. The ETL process involves extracting, transforming, and loading data from different databases into the target database or file. It forms the basis of a data warehouse. Here are a few ETL tools:
- IBM Datastage
- Informatica PowerCenter
- Abinitio
- Talend Studio, etc.

It performs the following functions:
- Obtains data from sources
- Analyze, transform, and cleans up data
- Indexes and summarizes data
- Obtains and loads data into the warehouse
- Monitors changes to source data needed for the warehouse
- Restructures keys
- Keeps track of metadata
- Updates data in the warehouse
4. What is Informatica PowerCenter? Write its components
ETL tools such as Informatica PowerCenter enable data integration (combining data from different sources into a single dataset). In order to build enterprise data warehouses, it provides the ability to extract, transform, and load data from heterogeneous OLTP (Online Transaction Processing) sources systems. US Air Force, Allianz, Fannie Mae, ING, and Samsung are among the top clients using Informatica PowerCenter. There is no doubt that it has a wide range of applications. Informatica PowerCenter 9.6.0 is the latest version available. Informatica PowerCenter is available in the following editions:
- Standard edition
- Advanced edition
- Premium edition
PowerCenter consists of seven important components:
- PowerCenter Service
- PowerCenter Clients
- PowerCenter Repository
- PowerCenter Domain
- Repository Service
- Integration Service
- PowerCenter Administration Console
- Web Service Hub
5. Name different types of transformation that are important?
Transformations in Informatica are the repository objects that transform the source data according to the needs of the target system and ensure that the quality of loaded data is maintained. The following transformations are provided by Informatica to accomplish specific functionalities:
- Aggregator Transformation: An active transformation used to compute averages and sums (especially across multiple rows or groups).
- Expression transformation: A passive transformation suitable for calculating values in one row. In addition, conditional statements can be tested before they are written to target tables or other transformations.
- Filter transformation: An active transformation used for filtering rows in mappings that don't meet the given condition.
- Joiner transformation: An active transformation joins data from different sources or from the same location.
- Lookup transformation: In order to get relevant data, a lookup transformation looks up a source, source qualifier, or target. Results of the lookup are returned to another transformation or the target object. Active Lookup transformation returns more than one row, whereas passive transformation returns only a single row.
- Normalizer transformation: An active transformation used for normalizing records sourced from Cobol sources whose data is usually in de-normalized format. A single row of data can be transformed into multiple rows using it.
- Rank transformation: An active transformation used to select top or bottom rankings.
- Router transformation: An active transformation provides multiple conditions for testing the source data.
- Sorter transformation: An active transformation sorts data according to a field in ascending or descending order. Additionally, to set case-sensitive sorting.
- Sequence Generator transformation: A passive transformation used to generate numeric values. Each record in the table is uniquely identified by creating unique primary keys or surrogate keys.
- Source Qualifier transformation: An active transformation reads rows from a flat-file or relational source while running a session and adds them to mapping. Using this tool, Source Data Types are transformed into Informatica Native Data Types
- Stored Procedure transformation: A passive transformation used to automate time-consuming processes or labor-intensive tasks. Additionally, used to handle errors, determine the database space, drop and recreate indexes, and perform specialized calculations.
- Update strategy transformation: An active transformation used to update data in a target table, either to maintain its history or incorporate recent updates.
 Learn via our Video Courses
Learn via our Video Courses
6. Write the difference between connected lookup and unconnected lookup.
Lookup transformations can both be used in connected and unconnected modes. Following is a comparison of the connected and unconnected lookup transformations:
| Connected Lookup | Unconnected Lookup |
|---|---|
| Data is directly received as input values from the transformation and also contributes to the data flow. | It does not directly take the values; it only receives them from the result or function of the LKP expression. |
| For synchronization, it is connected to the database. | No synchronization technique is in place. |
| Expressions and other transformations can't be done with it. | Though unconnected lookup does not take input directly from other transformations, it is still useful in any transformation. |
| This method cannot be called more than once in a mapping. | This method can be called multiple times in a mapping. |
| User-defined default values are supported. | User-defined default values are not supported. |
| It supports both dynamic and static cache. | It supports only static cache. |
| More than one column value can be returned, i.e., output port. | Only one column value can be returned. |
7. An unconnected lookup can have how many input parameters?
An unconnected lookup can include numerous parameters. No matter how many parameters are entered, the return value will always be one. You can, for instance, put parameters in an unconnected lookup as column 1, column 2, column 3, and column 4, but there is only one return value.

 Real-Life Problems
Real-Life Problems
 Detailed reports
Detailed reports
8. Explain the difference between active and passive transformation.
Transformation can be classified into two types:
- Active transformation: In this, the number of rows that pass from the source to the target is reduced as it eliminates the rows that do not meet the transformation condition. Additionally, it can change the transaction history or row type.
- Passive transformation: Unlike active transformations, passive transformations do not eliminate the number of rows, so all rows pass from source to target without being modified. Additionally, it can maintain the transaction boundary and row type.
9. Name the output files that are created by the Informatica server at runtime.
During runtime, the Informatica server creates the following output files:
- Informatica server log: Generally, this type of file is stored in Informatica's home directory and is used to create a log for all status and error messages (default name: pm.server.log). In addition, an error log can also be generated for all error messages.
- Session log file: For each session, session log files are created that store information about sessions, such as the initialization process, the creation of SQL commands for readers and writers, errors encountered, and the load summary. Based on the tracing level that you set, the number of details in the session log file will differ.
- Session detail file: Each target in mapping has its own load statistics file, which contains information such as the target name and the number of written or rejected rows. This file can be viewed by double-clicking the session in the monitor window.
- Performance detail file: This file is created by selecting the performance detail option on the session properties sheet and it includes session performance details that can be used to optimize the performance.
- Reject file: This file contains rows of data that aren't written to targets by the writer.
- Control file: This file is created by the Informatica server if you execute a session that uses the external loader and it contains information about the target flat file like loading instructions for the external loader and data format.
- Post-session email: Using a post-session email, you can automatically inform recipients about the session run. In this case, you can create two different messages; one for the session which was successful and one for the session that failed.
- Indicator file: The Informatica server can create an indicator file when the flat file is used as a target. This file contains a number indicating whether the target row has been marked for insert, update, delete or reject.
- Output file: Based on the file properties entered in the session property sheet, the Informatica server creates the target file if a session writes to it.
- Cache files: Informatica server also creates cache files when it creates the memory cache.
10. Can we store previous session logs in Informatica? If yes, how?
Yes, that is possible. The automatically session logout will not overwrite the current session log if any session is running or active in timestamp mode.
Click on Session Properties –> Config Object –> Log Options.
The properties should be chosen as follows:
- Save session log by –> SessionRuns
- Save session log for these runs –> Set the number of log files you wish to keep (default is 0)
- When you want to save all log files generated by each run, you should choose the option Save session log for these runs – > Session TimeStamp.
The properties listed above can be found in the session/workflow properties.
11. Explain data driven sessions.
In Informatica Server, data-driven properties determine how the data should be treated when an Update Strategy Transformation is used for mapping. When using an Update Strategy Transformation, it must be specified whether you want DD_UPDATE (constant for updating record) or DD_INSERT (constant for inserting record) or DD_DELETE (constant for deleting record). It is possible for mapping to contain more than one Update Strategy Transformation. Thus, a Data-Driven property must be specified in a session property for that specific mapping in order for the session to execute successfully.
Example:
- DD_UPDATE (Any time a record is marked as an update in the mapping, it will be updated in the target.)
- DD_INSERT (Any time a record is marked as an insert in the mapping, it will be inserted in the target.)
- DD_DELETE (Any time a record is marked as delete in the mapping, it will be deleted in the target.)
12. What is the role of a repository manager?
A repository manager is an administrative tool used to administer and manage repository folders, objects, groups, etc. A repository manager provides a way to navigate through multiple folders and repositories, as well as manage groups and user permissions.
13. What is Domain in Informatica?
PowerCenter services are administered and managed by the Informatica Domain. It consists of nodes and services. Each relationship and node are categorized according to the administration requirements into special folders and sub-folders.
Informatica Scenario Based Interview Questions
1. How can we improve the performance of Informatica Aggregator Transformation?
To increase the performance of Informatica Aggregator Transformation, consider the following factors:
- Using sorted input reduces the amount of data cached, thus improving session performance.
- Reduce the amount of unnecessary aggregation by filtering the unnecessary data before it is aggregated.
- To reduce the size of a data cache, connect only the inputs/outputs needed to subsequent transformations.
2. What are different ways of parallel processing?
As the name suggests, parallel processing involves processing data in parallel, which increases performance. In Informatica, parallel processing can be implemented by using a number of methods. According to the situation and the preference of the user, the method is selected. The following types of partition algorithms can be used to implement parallel processing:
- Database Partitioning: This partitioning technique involves querying the database for table partition information and reading partitioned data from corresponding nodes in the database.
- Round-Robin Partitioning: With this service, data is evenly distributed across all partitions. It also facilitates a correct grouping of data.
- Hash Auto-keys partitioning: The power center server uses the hash auto keys partition to group data rows across partitions. The Integration Service uses these grouped ports as a compound partition.
- Hash User-Keys Partitioning: In this type of partitioning, rows of data are grouped according to a user-defined or a user-friendly partition key. Ports can be selected individually that define the key correctly.
- Key Range Partitioning: By using key range partitioning, we can use one or more ports to create compound partition keys specific to a particular source. The Integration Service passes data based on the mentioned and specified range for each partition.
- Pass-through Partitioning: In this portioning, all rows are passed without being redistributed from one partition point to another by the Integration service.
3. State the difference between mapping parameter and mapping variable?
Mapping Parameter: Mapping parameters in Informatica are constant values that are set in parameter files before a session is run and retain the same values until the session ends. To change a mapping parameter value, we must update the parameter file between session runs.
Mapping Variable: Mapping variables in Informatica are values that do not remain constant and change throughout the session. At the end of the session run, the integration service saves the mapping variable value to the repository and uses it for the next round of sessions. SetMaxVariable, SetMinVariable, SetVariable, SetCountVariable are some variables functions used to change the variable value.
4. What is OLAP and write its type?
The Online Analytical Processing (OLAP) method is used to perform multidimensional analyses on large volumes of data from multiple database systems simultaneously. Apart from managing large amounts of historical data, it provides aggregation and summation capabilities (computing and presenting data in a summarized form for statistical analysis), as well as storing information at different levels of granularity to assist in decision-making. Among its types are DOLAP (Desktop OLAP), ROLAP (Relation OLAP), MOLAP (Multi OLAP), and HOLAP (Hybrid OLAP).
5. What is the scenario in which the Informatica server rejects files?
Servers reject files when they encounter rejections in the update strategy transformation. Data and information in a database also get disrupted. As you can see, this is a rare scenario or situation.
6. What do you mean by surrogate key?
Surrogate keys also referred to as artificial keys or identity keys, are system-generated identifiers used to uniquely identify each and every record in the Dimension table. As a replacement for the natural primary key (changes and makes updates more difficult), the surrogate key makes updating the table easier. Also, it serves as a method for preserving historical information in SCDs (Slowly Changing Dimension).
7. Give a few mapping design tips for Informatica.
Tips for mapping design
- Standards: Following a good standard consistently will benefit a project in the long run. These standards include naming conventions, environmental settings, documentation, parameter files, etc.
- Re-usability: Reusable transformations enable you to react quickly to potential changes. You should use Informatica components like mapplets, worklets, and transformations.
- Scalability: While designing, it is important to consider scalability. The volume must be correct when developing mappings.
- Simplicity: Different mappings are always better than one complex mapping. A simple and logical design process is ultimately more important than a complex one.
- Modularity: Utilize modular techniques in designing.
Informatica Interview Questions for Experienced
1. What are different lookup caches?
There are different types of Informatica lookup caches, such as static and dynamic. The following is a list of the caches:
- Static Cache
- Dynamic Cache
- Persistent Cache
- Shared Cache
- Reached
2. What is the difference between static and dynamic cache?
| Static Cache | Dynamic Cache |
|---|---|
| Caches of this type are generated once and re-used throughout a session. | During the session, data is continuously inserted/updated into the dynamic cache. |
| As our static cache cannot be inserted or updated during the session, it remains unchanged. | The dynamic cache changes as we can add or update data into the lookup, then pass it on to the target. |
| Multiple matches can be handled in a static cache. | Multiple matches can't be handled in the dynamic cache. |
| You can use both flat-file lookup types as well as relational lookup types. | It can be used with relational lookups. |
| It is possible to use relational operators such as =&=. | The dynamic cache supports only the = operator. |
| In both unconnected and connected lookup transformations, a static cache can be used. | You can use the dynamic cache only for connected lookups. |
3. What is pmcmd command? How to use it?
The Informatica features are accessed via four built-in command-line programs as given below:
-
pmcmd: This command allows you to complete the following tasks:
- Start workflows.
- Start workflow from a specific task.
- Stop, Abort workflows and Sessions.
- Schedule the workflows.
- infacmd: This command will let you access Informatica application services.
- infasetup: Using this command, you can complete installation tasks such as defining a node or a domain.
- pmrep: By using this command, you can list repository objects, create, edit and delete groups, or restore and delete repositories. Overall, you can complete repository administration tasks.
In Informatica, a PMCMD command is used as follows:
-
Start workflows
- pmcmd startworkflow -service informatica-integration-Service -d domain-name -u user-name -p password -f folder-name -w workflow-name
-
Start workflow from a specific task
- pmcmd startask -service informatica-integration-Service -d domain-name -u user-name -p password -f folder-name -w workflow-name -startfrom task-name
-
Stop workflow and task
- pmcmd stopworkflow -service informatica-integration-Service -d domain-name -u user-name -p password -f folder-name -w workflow-name
- pmcmd stoptask -service informatica-integration-Service -d domain-name -u user-name -p password -f folder-name -w workflow-name task-name
-
Schedule the workflows
- pmcmd scheduleworkflow -service informatica-integration-Service -d domain-name -u user-name -p password -f folder-name -w workflow-name
-
Aborting workflow and task
- pmcmd abortworkflow -service informatica-integration-Service -d domain-name -u user-name -p password -f folder-name -w workflow-name
- pmcmd aborttask -service informatica-integration-Service -d domain-name -u user-name -p password -f folder-name -w workflow-name task-name
4. What do you mean by mapplet in Informatica?
A mapplet is a reusable object that contains a set of transformations and is usually created using mapplet designer. Using it, you can reuse transformation logic across multiple mappings. Below are two types of mapplets:
- Active mapplet: This mapplet is created using an active transformation.
- Passive mapplet: This mapplet is created using a passive transformation.
5. What is the difference between Router and Filter?
Router and Filter are types of transformations offered by Informatica. There are a few differences between them as given below:
| Router transformation | Filter transformation |
|---|---|
| Using router transformation, rows of data that don't meet the conditions are captured to a default output group. | In this, data is tested for one condition, and rows that don't meet it are removed from the filter. |
| It allows records to be divided into multiple groups based on the conditions specified. | It doesn’t take care of the division of records. |
| This transformation has a single input and multiple output group transformations. | This transformation has a single input and a single output group transformation. |
| There can be more than one condition specified in a router transformation. | A single filter condition can be specified in filter transformation. |
| Input rows and failed records are not blocked by the router transformation. | There is a possibility that records get blocked in a filter transformation. |
6. Explain tracing level.
In Informatica, tracing levels determine how much data you want to write to the session log as you execute a workflow. Informatica's tracing level is a very important component as it aids in error analysis, locates bugs in the process, and can be set for every transformation. Each transformation property window contains an option for tracing level. As shown below, there are different types of tracing levels:
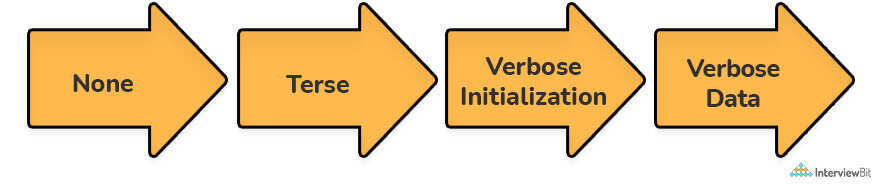
7. What is the difference between SQL Override and Lookup Override?
| Lookup Override | SQL Override |
|---|---|
| By using Lookup Override, you can avoid scanning the whole table by limiting the number of lookup rows, thus saving time and cache. | By using SQL Override, you can limit how many rows come into the mapping pipeline. |
| By default, it applies the "Order By" clause. | When we need it, we need to manually add it to the query. |
| It only supports one kind of join i.e., non-Equi join. | By writing the query, it can perform any kind of 'join'. |
| Despite finding multiple records for a single condition, it only provides one. | This is not possible with SQL Override. |
8. Write difference between stop and abort options in workflow monitor.
| STOP option | ABORT option |
|---|---|
| It executes the session tasks and allows another task to run simultaneously. | This fully terminates the currently running task. |
| It will stop the integration services from reading the data from the source file. | It waits for the services to be completed before taking any action. |
| Processes data either to the source or to the target. | It has a 60-second timeout. |
| The data can be written and committed to the targets with this option. | There are no indications of such commitment. |
| In other words, it doesn't kill any processes, but it does stop processes from sharing resources. | It ends the DTM (Data Transformation Manager) process and terminates the active session. |
9. Explain what is DTM (Data transformation manager) Process.
PowerCenter Integration Service (PCIS) started an operating system process, known as DTM (Data Transformation Manager) process or pmdtm process to run sessions. Its primary role is creating and managing threads responsible for carrying out session tasks. Among the tasks performed by DTM are:
- Read the session information
- Form dynamic partitions
- Create partition groups
- Validate code pages
- Run the processing threads
- Run post-session operations
- Send post-session email
10. Describe workflow and write the components of a workflow manager.
Workflow in Informatica is typically seen as a set of interconnected tasks that all need to execute in a specific order or a proper sequence. In every workflow, a start task, as well as other tasks linked to it, are triggered when it's executed. A workflow represents a business's internal routine practices, generates output data, and performs routine management tasks. The workflow monitor is a component of Informatica that can be used to see how well the workflow is performing. You can create workflows both manually and automatically in the Workflow Manager.

To help you develop a workflow, the Workflow Manager offers the following tools:
- Task Developer: This tool allows you to create workflow tasks.
- Worklet Designer: Worklet designer is an option in Workflow Manager which combines (groups) multiple tasks together to form a worklet. The term worklet refers to an object that groups multiple tasks together. Unlike workflows, worklets don't include scheduling information. It is possible to nest worklets inside workflows.
- Workflow Designer: This tool creates workflows by connecting tasks to links in the Workflow Designer. While developing a workflow, you can also create tasks in the Workflow Designer.
11. What are different types of tasks in informatica?
Workflow Manager allows you to create the following types of tasks so that you can design a workflow:
- Assignment task: A value is assigned to a workflow variable via this task type.
- Command task: This task executes a shell command during workflow execution.
- Control task: It halts or aborts workflow execution.
- Decision task: It describes a condition to be evaluated.
- Email task: This is used during workflow execution to send emails.
- Event-Raise task: This task notifies Event-Wait about the occurrence of an event.
- Event-Wait task: It waits for an event to complete before executing the next task.
- Session tasks: These tasks are used to run mappings created in Designer.
- Timer task: This task waits for an already timed event to occur.
12. What do you mean by incremental loading in Informatica?
Unlike full data loading, where all data is processed every time the data is loaded, incremental data loading involves loading only selective data (either updated or created new) from the source to the target system. This method provides the following benefits:
- ETL (Extract, transform, and load) process overhead can be reduced by selectively loading data, reducing runtime overall.
- Several factors can lead to an ETL load process failing or causing errors. The likelihood of risk involved is reduced by the selective processing of the data.
- Data accuracy is preserved in the historical record. Therefore, it becomes easy to determine the amount of data processed over time.
13. Explain complex mapping and write its features.
When a mapping contains a lot of requirements, which are based on too many dependencies, it is considered complex. Even with just a few transformations, a mapping can be complex; it doesn't need hundreds of transformations. When the requirement has a lot of business requirements and constraints, mapping becomes complex. Complex mapping also encompasses slowly changing dimensions. Complex mapping consists of the following three features.
- Large and complex requirements
- Complex business logic
- Several transformations
14. What is the importance of partitioning a session?
Parallel data processing improves the performance of PowerCenter with the Informatica PowerCenter Partitioning Option. With the partitioning option, a large data set can be divided into smaller parts that can be processed in parallel, which improves overall performance. In addition to optimizing sessions, it helps improve server performance and efficiency.
15. What do you mean by the star schema?
The star schema comprises one or more dimensions and one fact table and is considered the simplest data warehouse schema. It is so-called because of its star-like shape, with radial points radiating from a center. A fact table is at the core of the star and dimension tables are at its points. The approach is most commonly used to build data warehouses and dimensional data marts.

16. Explain the dimension.
Dimension tables are tables in a star schema of a data warehouse that contains keys, values, and attributes of dimensions. A dimension table generally contains the description or textual information about the facts contained within a fact table.
Tips to Prepare for Informatica Interview
1. Informatica Interview Preparation
Whether you are applying for your first job in the industry after college or looking for a new role after years in the industry (or something in between), you will face the hurdle of interviewing. Your preparation is the key to a successful tech interview. You must be thorough, whether you are searching within your own domain or for what the company is looking for. Here are a few tips which will significantly improve your preparation process.
- Do some research on the company: You should have a basic understanding of how Informatica has evolved over time. Informatica's mission, values, and goals should be familiar to you when you attend interviews. Researching an organization's culture is also very important. Talking about the culture and values of an organization during an interview will help recruiters see you as a good match. Research the products offered by Informatica and its areas of focus so you know what to expect if you're selected.
- Prepare Well: Practice the kinds of questions that will likely be asked before attending an interview. The technical interview includes a number of questions related to coding, computer fundamentals like DSA, computer networks, systems design, etc. Prepare all in advance and clarify your data warehouse concepts also. Since Informatica will be used in the same project, the interviewer is certain to ask to discuss these concepts. In addition to technical interviews, there are also behavioral interviews. They are designed to help employers assess your behavior in specific situations and to see if you're a good fit. Preparing for these interview sessions is often overlooked, but they are just as important as the technical sessions.
- Be passionate: Demonstrate your value, particularly in HR. Interviewers should be able to see why you would be a great member of their company. Your passion for coding and ability to create new programs demonstrate why you are the best candidate for the job.
- Don't let mistakes bother you: Ask questions and get clarification when you need it. Don't let a mistake affect your interview. Many questions will be asked and the interviewer will often overlook a mistake. So, if something goes wrong, move on to the next part of the interview. If you aren't sure of an answer to a question, be honest about it. You should interact with the interviewer for more information on the topic.
- Practice, Practice, Practice: Interviews can be challenging and hard to prepare for. It is necessary, however, to practice what you preach in order to increase your chance of success. Make sure you practice both technical and behavioral interviews. Data software such as Informatica is widely used around the world. You would, therefore, be well advised to stay up to date with the latest developments of this software. Become as knowledgeable as you can.
FAQ
1. Does Informatica have a future?
There is a bright future ahead for Informatica Professionals. Informatica specialists can look forward to a promising and exciting future. With the rapid growth of big data, there are plenty of job openings for Informatica wannabes and working specialists.
2. How many rounds are there in an Informatica interview?
Generally, 5-6 rounds are conducted in Informatica Interview:
- Online Round (MCQs only)
- Coding Round
- Technical Round (2-3)
- Managerial/HR Round
3. Is Informatica a good career choice?
Working at Informatica is a great experience. It can also be highly profitable if you meet your goals. As a team member, you will be part of a supportive, diverse, global team that solves real-life problems, makes a difference, and makes a global impact. You'll have great exposure to technology, wonderful colleagues to learn from, a relaxed and friendly environment, and fast growth potential.
4. Is Informatica difficult to learn?
Informatica is an easy-to-understand and easy-to-implement tool. It is a much better and more advanced SQL tool than other SQL tools available in the market.
5. How can I prepare for Informatica?
In this article, we provide you with 30+ frequently asked Informatica questions with their answers that you can study and prepare for. It is also a good idea to review the list of questions two or three times to make sure that you retain them for the tech interview.
Check out the above section for more tips.
6. What do you know about Informatica?
Using Informatica, a data processing tool, you can extract required data from all operational systems, transform it on a server, and load it into a data warehouse. They provide data integration services and software to many businesses, industries, and government organizations including telecommunications, health care, financial, and insurance services. In simple words, it is a leader in ETL, data quality, and data explorer.
7. How many days will it take to learn Informatica?
The learning curve for Informatica can be shortened if you have ample time. However, you will need a thorough working knowledge of SQL, including functions, joins, sub-queries, etc. You should also be familiar with PL/SQL.
Informatica MCQ
Source and target information can be found where?
In Informatica, which component is reusable?
When a workflow is running, which of the following components of Informatica is used to track its performance?
___ is the process of pulling data from heterogeneous source systems.
During the mapping process, ____ are objects that can be referenced (to access their values), and their values can be changed.
ETL stands for ___ .
What one of the following statements about filter transformation is incorrect?
Which of the following terminologies is not related to Informatica?
OLAP stands for __ .
When using the update strategy in a mapping, which session property is enabled?
To deal with Cobol sources, which of the following transformations is used?
___is required to run a mapping in Informatica.










