












Measures of central tendency, also called measures of a central location, could be defined as a single value that attempts to describe the data by identifying the central position within that set of data. These are also referred to as summary statistics. These measures usually contain:
Mean:
Generally denoted by the average of the numbers, sum of all the numbers by the total numbers. Mathematically, it is denoted by: 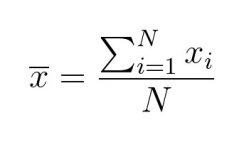
Where the term ‘x̄’ defines mean, ‘Σ Xi’ represents the sum of all data values, and N defines the size of the data space.
E.g.: For an array = [1, 2, 3, 4, 5], mean would be sum of the array / length = 15/5 = 3
At times, we get confused about the notations used to represent the mean. Is it 𝛍 or x̄? In general, 𝛍 is used for the population mean whereas x̄ is used for the sample mean.
Mean as a central tendency has certain use-cases and drawbacks as well. Speaking of use-cases, it involves all the data points of the sample or population. Though often the mean is not one of the actual values, it is the value that minimizes the error than all other data points. In addition, it is the central tendency with the sum of deviations of each value from it is always 0.
Given the wide range of applications, it also comes with some constraints. Mean is susceptible to the influence of outliers as it involves all the data points. Speaking of, Median is preferred over mean where we have skewness in the data points.
Median:
The middle element of the numbers when they are sorted in an order.
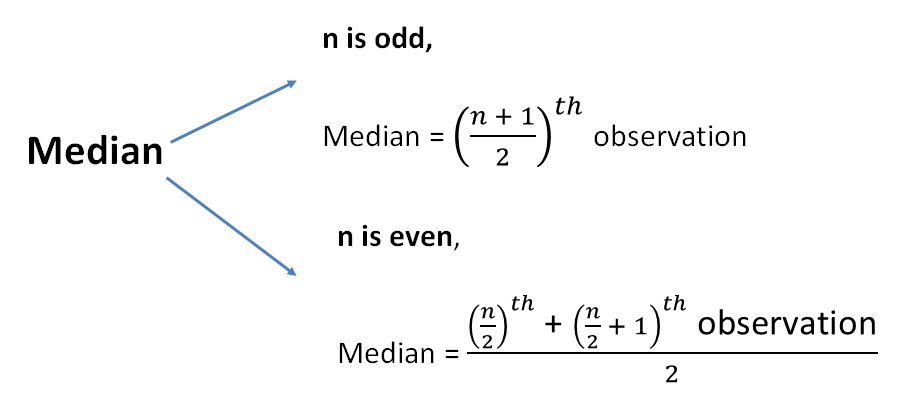
n denoting the size of the sample space X
E.g., for an array say, [1, 3, 4, 5, 7], the median is the array[4/2] = array[2] = 4
Mode:
The most frequently occurring number in the data.
E.g., for an array, say, [1, 3, 2, 3, 4, 5], the mode will be 3 in this case.
It is mainly considered while dealing with categorical values to observe the rank in appearances or the count.

 Video Courses
Video Courses











