













How to Create Greedy Algorithms?
A greedy algorithm makes the choice that appears best at that instance of time with the hope of finding the best possible result. In general, the greedy algorithm follows the below four steps:
- Firstly, the solution set (that is supposed to contain answers) is set to empty.
- Secondly, at each step, an item is pushed to the solution set.
- Only if the solution set is deemed feasible, the current item is kept for future purpose.
- Else, the current item is rejected and is never considered again (no reversal of decision)
Let us understand this by considering some examples.
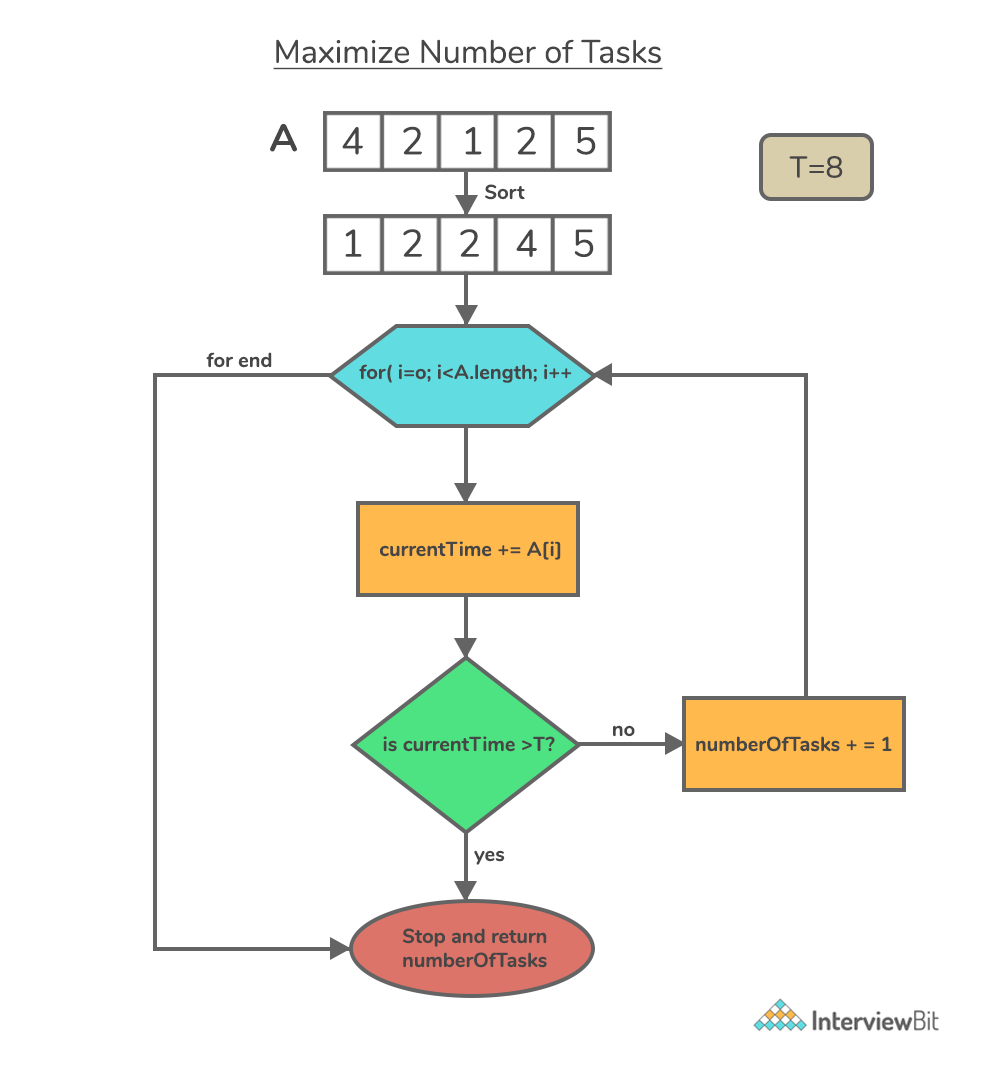
1. Maximising Number of Tasks:
Case Study:
Imagine you are a very busy person and you have lots of interesting things to be done within a short span of time T. You would want to do maximum of those interesting todo things in the short time you have.

You have a integer array A, where each element ai represents the time taken to complete a task. Your main task is now to compute the maximum number of things that can be done in the limited time T.
Analysis:
By carefully observing the problem, we can say that this problem requires nothing but a simple application of Greedy algorithm. Our natural greedy instinct says that in order to accomplish maximum tasks, we have to do the tasks that require minimum amount of time.
- In every iteration, we greedily select the tasks which takes minimum completion time. This is achieved by maintaining two variables
currentTimeandnumberOfTasks. In order to solve this problem, we follow the below steps:- Sort the given array A in ascending order.
- Select a to-do task one-by-one.
- Add the time taken to complete that task to the
currentTimevariable. - Increment
numberOfTasksby 1. - Repeat this until
currentTime<= T.
- Let array A = {4, 2, 1, 2, 5} and fixed time T = 8
- After sorting the array, A = {1, 2, 2, 4, 5}
- 1st iteration:
- currentTime = 1
- numberOfTasks = 1
- 2nd iteration:
- currentTime = 1 + 2 = 3
- numberOfTasks = 2
- 3rd iteration:
- currentTime = 3 + 2 = 5
- numberOfTasks = 3
- 4th iteration:
- currentTime = 5 + 4 = 9 > T. Therefore, stop looping.
- Hence, the final answer is 3.
Java Implementation:
import java.util.*;
public class InterviewBit{
public static int maximiseTasks(int[] A, int T){
Arrays.sort(A);
int currentTime =0;
int numberOfTasks = 0;
for(int i = 0;i < A.length;i++)
{
currentTime+= A[i];
if(currentTime > T)
break;
numberOfTasks++;
}
return numberOfTasks;
}
public static void main(String[] args){
Scanner s = new Scanner(System.in);
int N = s.nextInt();
//Time limit
int T = s.nextInt();
//populate A array
int[] A = new int[N];
for(int i =0;i<N;i++){
A[i] = s.nextInt();
}
int result = InterviewBit.maximiseTasks(A,T);
System.out.println("Maximum number of tasks achievable: " + result);
}
}2. Fractional Knapsack Problem:
Case Study:
Given weights and values of n items and the flexibility that you are allowed to break items or choose fraction of the items. Your task is to put these items in a knapsack of capacity W to get the maximum total value of the items in the knapsack.
Input:
Number of items, n = 3
int[] weights = { 10, 20, 30 };
int[] values = { 60, 100, 120 };
int capacity = 50;
Output:
Maximum Value Attainable - 240
Considering items of weight 10 kg and 20 kg and 2/3 fraction of 30 kg.
Hence total price will be 60+100+(2/3)(120) = 240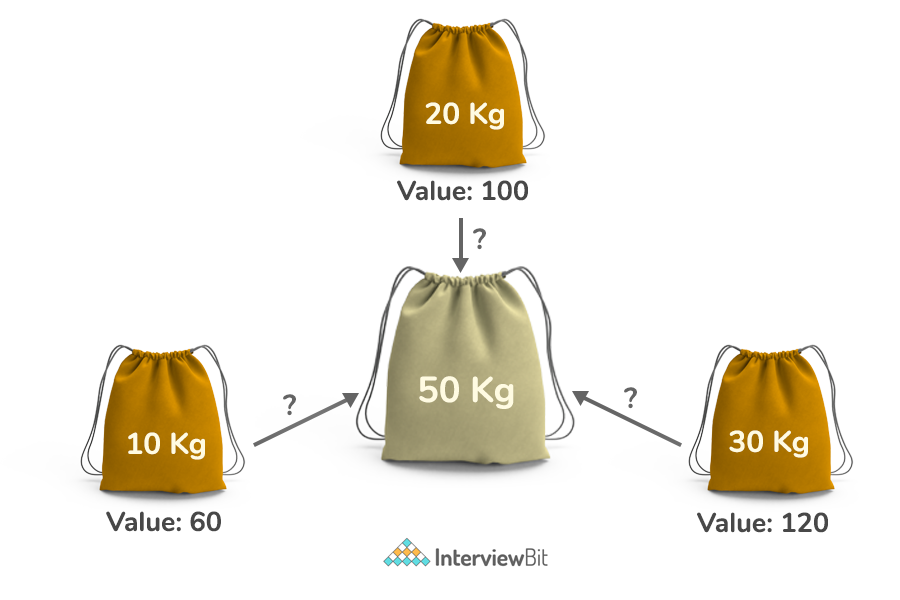
Analysis:
Brute Force:
The brute force approach that comes to our mind first is to try all possible subset with all different fraction and then choose the best out of it. This approach is really time consuming and the time complexities could be exponential.
Efficient Approach:
The efficient approach that can be used is to use Greedy Approach.
- The main idea of this approach is to calculate the ratio
value/weightfor each item and then sort the items on basis of this ratio. - Then, from this sorted list, take the item with the highest ratio and add them until we can’t add the next item as a whole. At the end, add the next item as much as we can.
- This will ensure that the solution will always be the optimal to this problem.
Java Program:
import java.util.Arrays;
import java.util.Comparator;
public class IBFractionalKnapsack
{
// function to get maximum value attainable
private static double getMaxValue(int[] weights, int[] val,
int capacity)
{
WeightValue[] weightValue = new WeightValue[weights.length];
// Populate with the values
for (int i = 0; i < weights.length; i++) {
weightValue[i] = new WeightValue(weights[i], val[i], i);
}
// sorting items by value/weight ratio;
Arrays.sort(weightValue, new Comparator() {
@Override
public int compare(WeightValue o1, WeightValue o2)
{
return o2.ratio.compareTo(o1.ratio);
}
});
double totalValue = 0d;
for (WeightValue i : weightValue) {
int curWeight = (int)i.weight;
int curValue = (int)i.value;
if (capacity - curWeight >= 0)
{
// this weight can be picked while
capacity = capacity - curWeight;
totalValue += curValue;
}
else
{
// item cant be picked whole
double fraction
= ((double)capacity / (double)curWeight);
totalValue += (curValue * fraction);
capacity
= (int)(capacity - (curWeight * fraction));
break;
}
}
return totalValue;
}
// Weight value class
static class WeightValue
{
Double ratio;
double weight, value;
// item value function
public WeightValue(int weight, int value)
{
this.weight = weight;
this.value = value;
ratio = new Double((double)value / (double)weight);
}
}
// Driver code
public static void main(String[] args)
{
int[] weights = { 10, 20, 30 };
int[] values = { 60, 100, 120 };
int capacity = 50;
double maxValue = getMaxValue(weights, values, capacity);
System.out.println("Maximum Value Attainable - "
+ maxValue);
}
}
3. Task Scheduling:
The previous example of maximising number of tasks was quite simple. We could easily understand how greedy approach could be applied to solve the problem. Let us focus on a more complicated example which is the problem of task scheduling based on priorities of each work. Note that a work (or a job) requires one or more tasks for completion.
Case Study:
The problem statement states that we have the following information:
- Total jobs to be done- N
- List of jobs that has to be done by today - J
- List of all the tasks that has to be completed by today for each job
- Time duration required to complete each task ( T )
- Weight or Priority of each task. ( P )
You need to determine in what order you should complete the tasks to get the most optimum result. What is the condition for the optimal scheduling of tasks? Can priority[i] can be applied to any job J or just to J[i]? Let us find answers to these questions in depth in the upcoming “Analysis” section
Analysis:
Let us start by analysing our inputs. We have J as the number of jobs that has to be done today. T as the list of time duration of each task and P is the list of priorities assigned to each task.
-
To understand the criteria that needs optimisation, we must first compute the total time taken to complete each task for a job Ji.
-
Mathematically,
J(i) = T[1] + T[2] + .... + T[i] where 1 <= i <= N - The i-th work has to wait till the first (i-1) tasks are completed after which it requires T[i] time for completion.
-
Consider this example, given that T = [1, 2, 3], the completion time for a job will be:
J(1) = T[1] = 1 J(2) = T[1] + T[2] = 1 + 2 = 3 J(3) = T[1] + T[2] + T[3] = 1 + 2 + 3 = 6 - We obviously want completion times of the jobs to be as less as possible.
- In a given job sequence, let us assume that the jobs queued up at the beginning require shorter time to complete and the ones that are queued up at the end require longer time to complete.
-
Now, what can be the optimal method to complete the tasks?
-
Well, this depends on our objective functions (final goal states after executing tasks). There are many objective functions available in the “Scheduling” problems. But in case of our example, the objective function F would be the weighted sum of the completion times of the job. Mathematically, the expression becomes:
F = (P[1] * J(1)) + (P[2] * J(2)) + ...... + (P[N] * J(N)) - Our main task is now to optimise this object function.
-
Well, this depends on our objective functions (final goal states after executing tasks). There are many objective functions available in the “Scheduling” problems. But in case of our example, the objective function F would be the weighted sum of the completion times of the job. Mathematically, the expression becomes:
-
Mathematically,
- Now that we have established what is the criteria for optimisation, let us see how this problem can be solved. Considering the given objective function, we have the following cases which needs to be considered while minimising the function.
-
The main rule for optimising the objective function in these special cases is to give preference to the tasks:
- 1. having higher priority
- 2. taking lesser completion times
-
Natural Intuition:
- Let us consider reasonably intuition of optimising our objective function. Just by doing this, we can come up with several greedy algorithmic tactics and then based on careful analysis, we can narrow down to what tactic works best and why it works the best.
-
The two special cases that can be thought of by doing natural intution are:
-
If the priorities of different tasks are the same i.e.
P[j] = P[k] where 1 <= j, k <= Nbut they take different time durations to complete, then in what order do can we schedule the jobs? -
If the time taken to complete different tasks are the same i.e.
T[j] = T[k] where 1 <= j, k <= N, but those tasks have different priorities assigned, then in what order can we schedule the jobs?
-
If the priorities of different tasks are the same i.e.
- By evaluating the above listed special cases, if 2 or more tasks take same time to complete, then the task with higher priority is given more preference.
-
Case 1: Tasks taking same time to execute but different priority
-
Consider the objective function we deduced and also assume that the time required to complete the different tasks is
ti.eT[i] = t where 1 <= i <= N -
Irrespective of the sequence of tasks, the completion time would be same for each task and the equations become:
J(1) = T[1] = t J(2) = T[1] + T[2] = 2 * t J(3) = T[1] + T[2] + T[3] = 3 * t J(4) = T[1] + T[2] + T[3] + T[4] = 4 * t : : J(N) = N * t - To minimise/optimise the objective function, it is natural that the highest priority task must be associated with the shortest completion time.
-
Consider the objective function we deduced and also assume that the time required to complete the different tasks is
-
Case 2: Same priorities but different completion time:
-
In this case, it is obvious that we must choose the task that takes least time of completion. Let us assume that the priorities of the tasks is
p. Then our minimised objective function becomes:F = (P[1] * J(1)) + (P[2] * J(2)) + ...... + (P[N] * J(N)) F = (p * J(1)) + (p * J(2)) + ...... + (p * J(N)) //Since P[i] = p F = p * (J(1) + J(2) + ...... + J(N)) -
To minimize F, we now must minimize focus on minimising
(J(1) + J(2) + ...... + J(N)), which is possible only if we start to work on the tasks that require the shortest completion time.
-
In this case, it is obvious that we must choose the task that takes least time of completion. Let us assume that the priorities of the tasks is
-
General Case: Different Priorities, Different Completion Times
-
In this case, the priorities and the completion times of each task are totally different. This is the most common scenario that usually occurs.
-
Consider the scenario where you have 2 or more tasks and the main rules of choosing tasks i.e we select the task that has higher priority and shorter completion time first. But what if this results in conflict? Assume that we have tasks where one of them has higher priority but longer completion time and the other one has least priority and shorter completion time? ( i.e. P[1] > P[2] and T[1] > T[2] ). Which task should be completed first?
-
We can think of aggregating the varying parameters (completion time and the task priority) into a single defining parameter so that based on this parameter, we can schedule the tasks in a optimal manner. Now what should this parameter be?
- By using the rules of selecting tasks, we can come up with a simple function that takes 2 parameters - time and priority - as input and return a single judging parameter as output that combines the properties.
-
We can look into the following 2 algorithms:
-
Algo #1: Schedule the jobs based on the decreasing value of
(P[i] - T[i]) -
Algo #2: Schedule the jobs based on decreasing value of
(P[i] / T[i])
-
Algo #1: Schedule the jobs based on the decreasing value of
-
Since we have 2 algorithms, we can say that atleast one of the algorithms is wrong. Let’s see which one.
-
Consider
T = [7, 3]andP = [5, 2] -
As per Algo #1,
(P[1] - T[1]) < (P[2] - T[2]). Hence second task can be completed first. The objective function becomes:F = (P[1] * J(1))+ (P[2] * J(2)) = (2 * 3) +(5 * (7+3)) = 56 -
Now, based on Algo #2,
(P[1] / T[1]) > (P[2] / T[2]). Hence, the first task can be completed first. The objective function becomes:F = (P[1] * J(1)) + (P[2] * J(2)) = (5 * 7) + (2 * (7+3)) = 55 - We can see that the result from Algo #2 is lesser than the result obtained from Algo #1. Hence, we can consider that Algo #1 does not give us the optimal answer. This also concludes that the results from Algo #1 doesnt always gives the correct answer.
-
Consider
Pseudo-Code based on Algorithm 2:
/** * Let S = array of pairs to store the scores and their indices * J = completion times of job * F = objective function * P = List of priorities * T = time taken of task * N = number of job */ ObjectiveFunctionF (P, T, N) { for i from 1 to N: S[i] = ( P[i] / T[i], i ) Arrays.sort(S) J = 0 F = 0 for i ranging from 1 to N: // Greedy selection J = J + T[S[i].second] F = F + P[S[i].second]*J return F }-
Time Complexity: The time complexity of this algorithms is O(N*logN) because we have 2 loops that takes
O(N)time each and one sorting functionality which takesO(N * logN). Hence,O((2 * N) + (N*logN)) = O(N*logN).
Proof of correctness of Algo #2:
- Let us try to prove why Algo #2 is the best and correct approach for task scheduling by means of proof by contradiction i.e by assuming the thing we are trying to prove is false and in that process derive that the thing we assumed earlier was originally correct.
-
Let us assume that Algo #2 does not give optimal solution and there is another non-greedy algorithm which gives us an even more better solution.
- G = Greedy schedule (which is assumed as non-optimal schedule)
- O = Optimal Schedule (Non-Greedy approach)
-
Consider the below 2 assumptions:
-
1. (P[i] / T[i])is different. 2. ( P[1] / T[1] ) > ( P[2] / T[2] ) > .... > ( P[N] / T[N] )
-
-
Because of assumption #2, the greedy schedule will be
G = ( 1, 2, 3, ....., N ). Since G is considered as non optimal and G is not equal to O, we can say that O must contain two consecutive jobs(i,j)in such a way thati > j. This is true as the only schedule that has the indices increase monotonically isG = ( 1, 2, 3, ...., N )Therefore,O = ( 1, 2, ..., i, j, ... , N )wherei > j. -
We also need to consider what is the profit or loss impact in case of swapping 2 jobs. Let us see what is the effect due to the below swapping:
-
Work on task
kother thaniandj -
Work on task
iand then -
Work on task
j
-
Work on task
-
For task
know there will be 2 cases:-
When
klies on left ofiandjin O, while swapping tasksiandj, there is no effect on the completion of taskksinceJ(k) = T[1] + T[2] + ..T[k]+.. + T[j] + T[i] + .. -
When
klies on the right ofiandjin O, after the swap, the completion time ofkisJ(k) = T[1] + T[2] + .. + T[j] + T[i] + .. T[k]+..,kwill again remain the same.
-
When
-
For task
i, the completion time before swap wasJ(i) = T[1] + T[2] + ... + T[i]and after swap isJ(i) = T[1] + T[2] + ... + T[j] + T[i]. As we can see, clearly, the completion time ofiwent up byT[j]and there by deduce that the completion time forjgoes down byT[i]. Due to swap:-
Loss is
(P[i] * T[j]) -
Profit is
(P[j] * T[i])
-
Loss is
-
Using the second assumption,
i > jsignifies(P[i] / T[i]) < (P[j] / T[j]). Therefore, we have(P[i] * T[j]) < (P[j] * T[i])which means that theLoss < Profit. This signifies that the swap effect improves algorithm O further but this contradicts the initially assumed fact that O is already an optimal schedule. Hence, we can say that greedy approach gave us the optimal algorithm.
-
Greedy Algorithm Applications
Though greedy algorithms don’t provide correct solution in some cases, it is known that this algorithm works for the majority of problems. However, greedy algorithms are fast and efficient which is why we find it’s application in many other most commonly used algorithms such as:
- Dijkstra’s Algorithm: This algorithm is the most famous graph traveral one that is used for finding the shortest path between nodes in a graph.
- Minimal Spanning Tree (MST): This algorithm is widely used in Cluster Analysis, Handwriting recognition and Image segmentation.
- Huffman Coding: This is the most common algorithm in the field of data compression. It analyzes a given message and based on the frequencies of the characters present in the message, a variable-length code for each symbol is assigned.
The most basic purpose of greedy algorithm is optimisation which can be either minimisation or maximisation based on our problem statement requirements.
FAQs
What is the time complexity of a greedy algorithm?
- The time complexity of a greedy algorithm depends on what problem you are trying to solve, what is the data structure used to represent the problem, whether the given inputs require sorting and so many other factors.
-
The most common time complexities of commonly solved problems are:
-
Activity Selection Problem
- With Unsorted Activities: O(n * log n)
- With Sorted Activities: O(n)
-
Dijkstra’s Shortest Path Algorithm: V= Nodes, E= Edges
- Matrix Representation: O(V2)
- Adjacency List: O(E * log V)
-
Activity Selection Problem
Is Dijkstra a greedy algorithm?
- Yes.
Are greedy algorithms optimal?
- Greedy algorithms are simple and intuitive way of solving any problems which attempt to find the optimal solution. But there are some cases when using greedy algorithms leads to incorrect results. Hence, these are not always optimal.
Is greedy an heuristic algorithm?
- Heuristic algorithms are the ones that make choices that are known to be theoretically suboptimal but produce reasonable results during practical implementations.
- Greedy algorithm is just an example of heuristic algorithm. The vice versa is not true.
Does greedy always work?
- Greedy fails to give optimal and correct results in some scenarios because it attempts to find the overall optimal solution just by finding locally best solution at a particular instant and not by operating exhaustively on the dataset given.
Why does the greedy algorithm fail?
- Sometimes greedy algorithms fail to find the globally optimal solution because they do not consider all the data. The choice made by a greedy algorithm may depend on choices it has made so far, but it is not aware of future choices it could make.
How do you identify greedy algorithms problems?
-
For a greedy approach to work correctly, we must have a problem that has the below 2 components:
- Optimal substructures: The optimal solution for the problem lies in the optimal solutions to the sub-problems.
- Greedy property: The choice that appears to be the best at that moment for all the sub-problems, leads us to an overall optimal solution by never reconsidering our earlier decisions. Read More
Why is greedy algorithm called greedy?
- In this algorithm, it is believed that the locally best choices made would be leading towards globally best results without reconsidering the previously made choices again. Hence, a greedy algorithm is called as “greedy”.


 Video Courses
Video Courses











