













Breadth First Search (BFS) is an algorithm for traversing or searching layerwise in tree or graph data structures. BFS was first invented in 1945 by Konrad Zuse which was not published until 1972. It was reinvented in 1959 by Edward F. Moore for finding the shortest path out of a maze. BFS was further developed by C.Y.Lee into a wire routing algorithm (published in 1961). The strategy used here is opposite to depth first search (DFS) which explores the nodes as far as possible (depth-wise) before being forced to backtrack and explore other nodes. The algorithm starts at the tree root (or any arbitrary node of a graph called ‘source node’), and investigates all of the neighboring nodes (directly connected to source node) at the present level before moving on to the nodes at the next level. The process is repeated until the desired result is obtained.
Table of content
- Application
- BFS Algorithm
- BFS Algorithm Example
- Pseudocode of BFS
- Implementation of BFS
- Complexity Analysis of BFS
- FAQs
Application
Most of the concepts in computer science and real world can be visualized and represented in terms of graph data structure. BFS is one such useful algorithm for solving these problems easily. The architecture of BFS is simple, accurate and robust. It is very seamless as it is guaranteed that the algorithm won’t get caught in an infinite loop.
- Shortest Path: In an unweighted graph, the shortest path is the path with least number of edges. With BFS, we always reach a node from given source in shortest possible path. Example: Dijkstra’s Algorithm.
- GPS Navigation Systems: BFS is used to find the neighboring locations from a given source location.
- Finding Path: We can use BFS to find whether a path exists between two nodes.
- Finding nodes within a connected component: BFS can be used to find all nodes reachable from a given node.
- Social Networking Websites: We can find number of people within a given distance ‘k’ from a person using BFS.
- P2P Networks: In P2P (Peer to Peer) Networks like BitTorrent, BFS is used to find all neighbor nodes from a given node.
- Search Engine Crawlers: The main idea behind crawlers is to start from source page and follow all links from that source to other pages and keep repeating the same. DFS can also be used here, but Breadth First Traversal has the advantage in limiting the depth or levels traversed.
Breadth First Search Algorithm
- BFS is a traversing algorithm where we start traversing from a selected source node layerwise by exploring the neighboring nodes.
- The data structure used in BFS is a queue and a graph. The algorithm makes sure that every node is visited not more than once.
-
BFS follows the following 4 steps:
- Begin the search algorithm, by knowing the key which is to be searched. Once the key/element to be searched is decided the searching begins with the root (source) first.
- Visit the contiguous unvisited vertex. Mark it as visited. Display it (if needed). If this is the required key, stop. Else, add it in a queue.
- On the off chance that no neighboring vertex is discovered, expel the first vertex from the Queue.
- Repeat step 2 and 3 until the queue is empty.
- The above algorithm is a search algorithm that identifies whether a node exists in the graph. We can convert the algorithm to traversal algorithm to find all the reachable nodes from a given node.
Note:
- If the nodes are not marked as visited, then we might visit the same node more than once and we will possibly end up in an infinite loop.
BFS Algorithm Example
Consider the following graph structure where S is the Source node to begin BFS with:

The goal here is to find whether the node E is present in the graph. Just by seeing the graph, we can say that node E is not present. Lets see how BFS works to identify this.
Step 1: We enqueue S to the QUEUE.
Step 2: Mark S as Visited.

Step 3: Now, call the BFS function with S in the queue.
- Dequeue S from queue and we compare dequeued node with key E. It doesnt match. Hence, proceed by looking for the unexplored nodes from S. There exist three namely, A, B, and C.
- We start traversing from A. Mark it as visited and enqueue.
- After this, there are two neighboring nodes from A, i.e., B and C. We next visit B. And insert it into the queue and mark as visited.
- The similar procedure begins with node C, and we insert it into the queue.

Step 4: Dequeue A and check whether A matches the key. It doesnt match, hence proceed by enqueueing all unvisited neighbours of A (Here, D is the unvisited neighbor to A) to the queue.

Step 5: Dequeue B and check whether B matches the key E. It doesnt match. So, proceed by enqueueing all unvisited neighbors of B to queue. Here all neighboring nodes to B has been marked visited. Hence, no nodes are enqueued.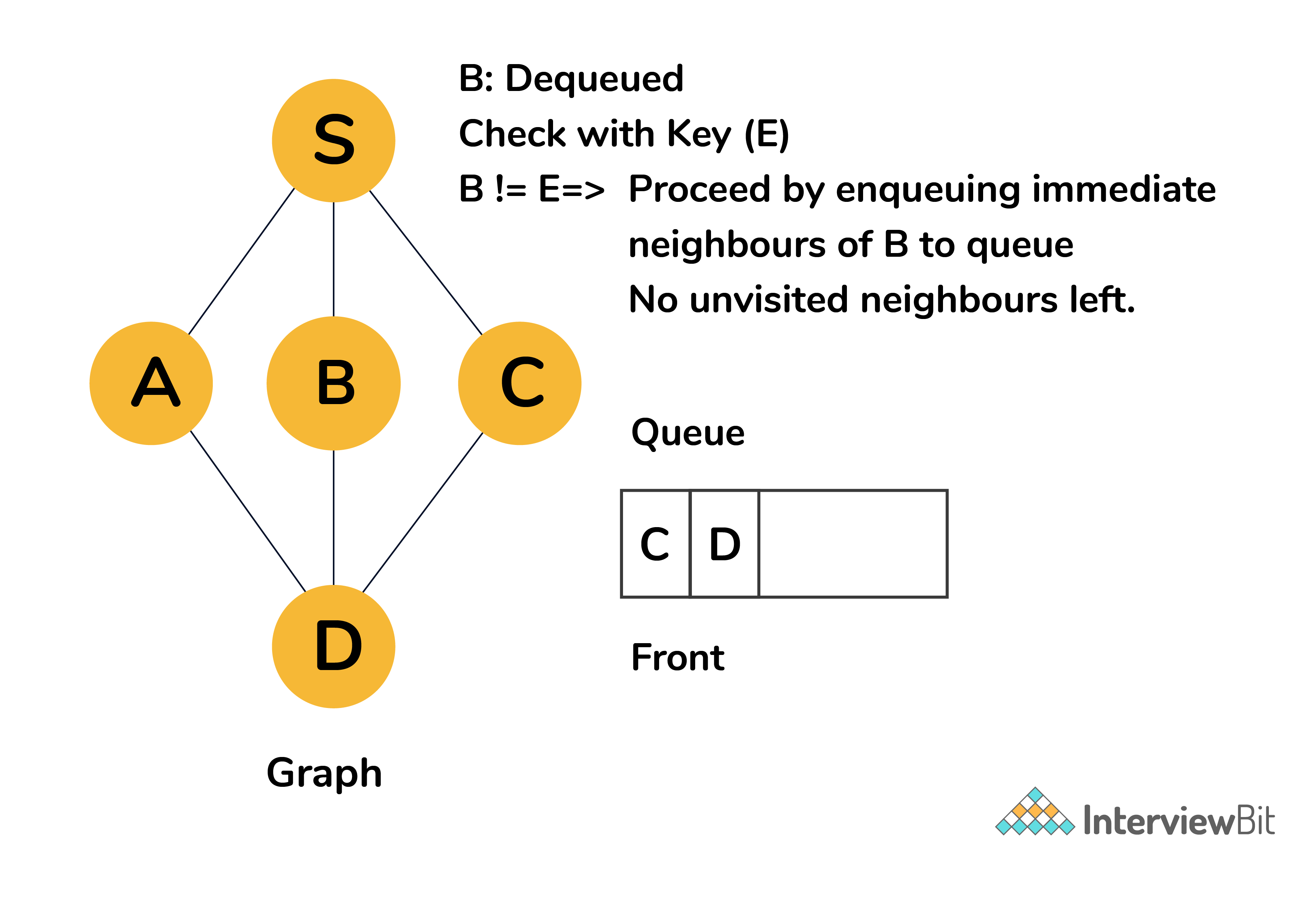
Step 6: Dequeue C and check whether C matches the key E. It doesnt match. Enqueue all unvisited neighbors of C to queue. Here again all neighboring nodes to C has been marked visited. Hence, no nodes are enqueued.
Step 7: Dequeue D and check whether D matches the key E. It doesnt match. So, enqueue all unvisited neighbors of D to queue. Again all neighboring nodes to D has been marked visited. Hence, no nodes are enqueued.
Step 8: As we can see that the queue is empty and there are no unvisited nodes left, we can safely say that the search key is not present in the graph. Hence we return false or “Not Found” accordingly.
This is how a breadth-first search works, by traversing the nodes levelwise. We stop BFS and return Found when we find the required node (key). We return Not Found when we have not found the key despite of exploring all the nodes.
Pseudocode of Breadth First Search
Recursive BFS
/**
* Pseudo code for recursive BFS
* @Parameters: Graph G represented as adjacency list,
* Queue q, boolean[] visited, key
* Initially q has s node in it.
*/
recursiveBFS(Graph graph, Queue q, boolean[] visited, int key){
if (q.isEmpty())
return "Not Found";
// pop front node from queue and print it
int v = q.poll();
if(v==key) return "Found";
// do for every neighbors of node v
for ( Node u in graph.get(v))
{
if (!visited[u])
{
// mark it visited and push it into queue
visited[u] = true;
q.add(u);
}
}
// recurse for other nodes
recursiveBFS(graph, q, visited, key);
}
Queue q = new Queue();
q.add(s);
recursiveBFS(graph, q, visited, key);
Iterative BFS
/**
* Pseudo code for iterative BFS
* @Parameters: Graph G, source node s, boolean[] visited, key
*/
iterativeBFS(Graph graph, int s, boolean[] visited, int key){
// create a queue neeeded for BFS
Queue q = Queue();
// mark source node as discovered
visited[s] = true;
// push source node into the queue
q.add(s);
// while queue isnt empty
while (!q.isEmpty())
{
// pop front node from queue and print it
v = q.poll();
if(v==key) return "Found";
// for every neighboring node of v
for (int u : graph.get(v)) {
if (!visited[u]) {
// mark it visited and enqueue to queue
visited[u] = true;
q.add(u);
}
}
}
//If key hasnt been found
return "Not Found";
}
Implementation:
Following are C, C++, Java and Python implementations of Breadth First Search.
BFS Implementation In C:
#include<stdio.h>
#include<stdlib.h>
#define MAX 100
int n;
int adj[MAX][MAX]; //adjacency matrix, where adj[i][j] = 1, denotes there is an edge from i to j
int visited[MAX]; //visited[i] can be 0 / 1, 0 : it has not yet printed, 1 : it has been printed
void create_graph();
void BF_Traversal();
void BFS();
int queue[MAX], front = -1,rear = -1;
void push_queue(int vertex);
int pop_queue();
int isEmpty_queue();
int main()
{
create_graph();
BFS();
return 0;
}
void BFS()
{
int v;
for(v=0; v<n; v++)
visited[v] = 0;
printf("Enter Start Vertex for BFS: \n");
scanf("%d", &v);
int i;
push_queue(v);
while(!isEmpty_queue())
{
v = pop_queue( );
if(visited[v]) //if it has already been visited by some other neighbouring vertex, it should not be printed again.
continue;
printf("%d ",v);
visited[v] = 1;
for(i=0; i<n; i++)
{
if(adj[v][i] == 1 && visited[i] == 0)
{
push_queue(i);
}
}
}
printf("\n");
}
void push_queue(int vertex)
{
if(rear == MAX-1)
printf("Queue Overflow\n");
else
{
if(front == -1)
front = 0;
rear = rear+1;
queue[rear] = vertex ;
}
}
int isEmpty_queue()
{
if(front == -1 || front > rear)
return 1;
else
return 0;
}
int pop_queue()
{
int delete_item;
if(front == -1 || front > rear)
{
printf("Queue Underflow\n");
exit(1);
}
delete_item = queue[front];
front = front+1;
return delete_item;
}
void create_graph()
{
int count,max_edge,origin,destin;
printf("Enter number of vertices : ");
scanf("%d",&n);
max_edge = n*(n-1); //assuming each vertex has an edge with remaining (n-1) vertices
for(count=1; count<=max_edge; count++)
{
printf("Enter edge %d( -1 -1 to quit ) : ",count);
scanf("%d %d",&origin,&destin);
if((origin == -1) && (destin == -1))
break;
if(origin>=n || destin>=n || origin<0 || destin<0)
{
printf("Invalid edge!\n");
count--;
}
else
{
adj[origin][destin] = 1;
adj[destin][origin] = 1; // assuming it is a bi-directional graph, we are pushing the reverse edges too.
}
}
}
BFS Implementation in C++
#include<bits/stdc++.h>
using namespace std;
#define MAX 1005
vector <int> adj[MAX]; // adjacency matrix, where adj[i] is a list, which denotes there are edges from i to each vertex in the list adj[i]
bool visited[MAX]; // boolean array, hacing value true / false, which denotes if a vertex 'i' has been visited or not.
void init(){ // initialization function
int i;
for(i = 0; i < MAX; i++){
visited[i] = false; // marking all vertex as unvisited
adj[i].clear(); // clearing all edges
}
}
void BFS(int start){
init();
queue <int> q;
q.push(start);
int iterator, current_node, next_node;
cout<<"BFS Traversal is:\n";
while(q.empty() == false){
current_node = q.front();
q.pop();
if(visited[current_node] == true){
continue;
}
cout<<current_node<<" ";
visited[current_node] = true;
for(iterator = 0; iterator < adj[current_node].size(); iterator++){
next_node = adj[current_node][iterator];
if(visited[next_node] == false) {
q.push(next_node);
}
}
}
}
int main(){
int vertices, edges;
cout<<"Enter Number of Vertices:\n";
cin>>vertices;
cout<<"Enter number of edges:\n";
cin>>edges;
int i;
int source, destination;
cout<<"Enter Edges as (source) <space> (destination):\n";
for(i=0; i<edges; i++){
cin>>source>>destination;
if(source > vertices || destination > vertices){
cout<<"Invalid Edge";
i--;
continue;
}
adj[source].push_back(destination);
adj[destination].push_back(source);
}
int start;
cout<<"Enter Starting Vertex:";
cin>>start;
BFS(start);
}
BFS Implementation In Java
import java.io.*;
import java.util.*;
// This class represents a directed graph using adjacency list
// representation
class Graph
{
private int V; // No. of vertices
private LinkedList<Integer> adj[]; //Adjacency Lists
// Constructor
Graph(int v)
{
V = v;
adj = new LinkedList[v];
for (int i=0; i<v; ++i)
adj[i] = new LinkedList();
}
// Function which adds an edge from v -> w
void addEdge(int v,int w)
{
adj[v].add(w);
}
// Function which prints BFS traversal from a given source 's'
void BFS(int s)
{
// mark all vertices as false, (i.e. they are not visited yet)
boolean visited[] = new boolean[V];
// Create a new queue for BFS
LinkedList<Integer> queue = new LinkedList<Integer>();
// Mark the current node as visited and enqueue it
visited[s]=true;
queue.add(s);
while (queue.size() > 0)
{
// pop a vertex from queue and print it
s = queue.poll();
System.out.print(s+" ");
//Traverse all the adjacent vertices of current vertex,
//check if they are not visited yet, mark them visited and push them into the queue.
Iterator<Integer> it = adj[s].listIterator();
while (it.hasNext() == true)
{
int n = it.next();
if (!visited[n])
{
visited[n] = true;
queue.add(n);
}
}
}
}
}
class Main {
// Driver method to Create and Traverse Graph
public static void main(String args[])
{
Scanner sc = new Scanner(System.in);
System.out.println("Enter Number of vertices");
int vertices = sc.nextInt();
Graph g = new Graph(vertices);
System.out.println("Enter Number of edges");
int edges = sc.nextInt();
int i;
int source, destination;
System.out.println("Enter Source <space> Destination (0-indexing)");
for(i = 0; i < edges; i++){
source = sc.nextInt();
destination = sc.nextInt();
if(source >= vertices || destination >= vertices){
System.out.println("Invalid Edge");
i--;
}
g.addEdge(source, destination);
}
System.out.println("Enter starting vertex");
int start = sc.nextInt();
System.out.println("Following is Breadth First Traversal, starting from vertex " + start);
g.BFS(start);
}
}BFS implementation in python
import collections
class graph:
def __init__(self,adjacency=None):
if adjacency is None:
adjacency = {}
self.adjacency = adjacency
def bfs(graph, startnode):
# Track the visited and unvisited nodes using queue
seen, queue = set([startnode]), collections.deque([startnode])
while queue:
vertex = queue.popleft()
print(vertex)
for node in graph[vertex]:
if node not in seen: #checking if not visited
seen.add(node)
queue.append(node)
# The graph dictionary
adjacency = {
"a" : set(["b","c"]),
"b" : set(["a", "d"]),
"c" : set(["a", "d"]),
"d" : set(["e"]),
"e" : set(["a"])
}
bfs(adjacency, "a")
Complexity Analysis of Breadth First Search
Time Complexity
- The time complexity of BFS if the entire tree is traversed is O(V) where V is the number of nodes.
-
If the graph is represented as adjacency list:
- Here, each node maintains a list of all its adjacent edges. Let’s assume that there are V number of nodes and E number of edges in the graph.
- For each node, we discover all its neighbors by traversing its adjacency list just once in linear time.
- For a directed graph, the sum of the sizes of the adjacency lists of all the nodes is E. So, the time complexity in this case is O(V) + O(E) = O(V + E).
- For an undirected graph, each edge appears twice. Once in the adjacency list of either end of the edge. The time complexity for this case will be O(V) + O (2E) ~ O(V + E).
-
If the graph is represented as an adjacency matrix (a V x V array):
- For each node, we will have to traverse an entire row of length V in the matrix to discover all its outgoing edges.
- Note that each row in an adjacency matrix corresponds to a node in the graph, and that row stores information about edges emerging from the node. Hence, the time complexity of BFS in this case is O(V * V) = O(V2).
- The time complexity of BFS actually depends on the data structure being used to represent the graph.
Space Complexity
- Since we are maintaining a priority queue (FIFO architecture) to keep track of the visited nodes, in worst case, the queue could take upto the size of the nodes(or vertices) in the graph. Hence, the space complexity is O(V).
FAQs
-
Why do we prefer queues instead of other data structures while implementing BFS?
- BFS searches for nodes levelwise, i.e. it searches the nodes w.r.t their distance from the root (or source).
- From the above example, we could see that BFS required us to visit the child nodes in order their parents were discovered.
- Whenever we visit a node, we insert all the neighboring nodes into our data structure. If a queue data structure is used, it guarantees that, we get the nodes in order their parents were discovered as queue follows the FIFO (first in first out) flow.
-
Why is time complexity more in the case of graph being represented as Adjacency Matrix?
- Every time we want to find what are the edges adjacent to a given node ‘U’, we have to traverse the whole array AdjacencyMatrix[U], which is of length |V|.
-
During BFS, you take a starting node S, which is at level 0. All the adjacent nodes are at level 1. Then, we mark all the adjacent nodes of all vertices at level 1, which don’t have a level, to level 2. So, every vertex will belong to one level only and when an element is in a level, we have to check once for its adjacent nodes which takes
O(V)time. Since the level coversVelements over the course of BFS, the total time would beO(V * V)which is O(V2). -
In short, for the case of Adjacency Matrix, to tell which nodes are adjacent to a given vertex, we take
O(V)time, irrespective of edges. -
Whereas, when Adjacency List is used, it is immediately available to us and it just takes time complexity proportional to adjacent nodes itself, which upon summation over all nodes
VisE. So, BFS when using Adjacency List givesO(V + E).
-
What is 0-1 BFS?
- This type of BFS is used to find shortest distance or path from a source node to a destination node in a graph with edge values 0 or 1.
- When the weights of edges are 0 or 1, the normal BFS techniques provide erroneous results because in normal BFS technique, its assumed that the weight of edges would be equal in the graph.
- In this technique, we will check for the optimal distance condition instead of using bool array to mark visited nodes.
-
We use double ended queue to store the node details. While performing BFS, if we encounter a edge having weight = 0, the node is pushed at front of double ended queue and if a edge having weight = 1 is found, the node is pushed at back of double ended queue.
- The above approach is similar to Dijkstra’s algorithm where if the shortest distance to node is relaxed by the previous node then only it will be pushed in the queue.
- Pseudo Code:
/* * edges[v][i]: adjacency list in the form of pairs * i.e. edges[v][i].first contains the node to which v is connected * and edges[v][i].second contains distance between v and edges[v][i].first. * * Q: Double ended queue * distance: Array where distance[v] contain the distance from the start node to v node. * Initially, the distance from the source node to every other node is marked infinity. */ void Zero_One_BFS(int start) { Deque <Integer > Q; //Double-ended queue Q.push_back( start); distance[start] = 0; while(!Q.empty()) { int v = Q.pop_front(); for( int i = 0 ; i < edges[v].size(); i++){ // if distance of neighbour of v from start node is greater // than sum of distance of v from start node and edge weight // between v and its neighbour (distance between v and its //neighbour of v) ,then update it if(distance[edges[v][i].first] > distance[v] + edges[v][i].second ) { distance[edges[v][i].first] = distance[v] + edges[v][i].second; //if edge weight between v and its neighbour is 0 then push it to front of Deque if(edges[v][i].second == 0) { Q.push_front(edges[v][i].first); } // else push it at back else { Q.push_back(edges[v][i].first); } } } } }-
Analysis:
- The approach is quite similar to BFS + Dijkstra combined.
- But the time complexity of this code is O(E + V), which is linear and more efficient than Dijkstra algorithm.
- The analysis and proof of correctness for this algorithm is also same as that of normal BFS.
-
Why can’t we use normal queue in 0-1 BFS technique?
-
The normal queue lacks methods which helps us to perform the below functions necessary for performing 0-1 BFS:
- Removing Top Element (To get vertex for BFS)
- Inserting at the beginning of queue
- Inserting at the end
- All the above operations are supported in Double ended Queue data structure and hence we go for that.
-
The normal queue lacks methods which helps us to perform the below functions necessary for performing 0-1 BFS:
-
What are the classifications of edges in a BFS graph?
- For the given graph below, the general types of edges are as follows:

- Tree Edge: The edge which is present in the tree obtained after applying DFS on the graph. All the Green edges are tree edges.
-
Forward Edge:
Edge (u, v)such that v is descendant but not part of the DFS tree. Edge from node 1 to node 6 is a forward edge. -
Back edge:
-
Edge (u, v)such thatvis ancestor of edge u but not part of DFS or BFS tree. Edge from node 4 to node 1 is a back edge. - Presence of back edge indicates a cycle in the directed graph.
-
- Cross Edge: It is a edge which connects two nodes such that they do not have any ancestor and a descendant relationship between them. Edge from node 3 to node 2 is a cross edge.
-
What are the types of edges present in BFS of a directed graph?
- A BFS of a directed graph has only Tree Edge, Cross Edge and Back Edge.
-
The BFS has NO Forward edges.
- For Edge A->B as forward edge, node B should have been visited before the edge A-B is discovered and this can happen only when B is visited via some other node using more than one edge.
- As BFS finds shortest path from source by using optimal number of edges, when node A is enqueued, edge A-B will have been discovered and would be marked as a tree or cross edge. Hence, forward edges is never possible in BFS.
-
Can BFS be used for finding shortest possible path?
- Yes. BFS is mostly used for finding shortest possible path.
-
What is the difference between DFS and BFS? When is DFS and BFS used?
- BFS is less space efficient than DFS as BFS maintains a priority queue of the entire level while DFS just maintains a few pointers at each level by using simple stack.
- If it is known priorly that an answer will likely be found far into a tree (depths of tree), DFS is a better option than BFS.
- BFS is useful when the depth of the tree can vary or when a single answer is needed. For instance, the shortest path in a maze. BFS will perform better here because DFS is most likely to start out on a wrong path, exploring a large portion of the maze before reaching the goal.
- If it is known that the solution is not far from the root of the tree, a breadth first search (BFS) might be better.
- If the tree is very deep and solutions are rare, depth first search (DFS) might take an extremely long time, but BFS could be faster.
- If the tree is very wide, a BFS might need too much memory, so it might be completely impractical. We go for DFS in such cases.
- If solutions are frequent but located deep in the tree we opt for DFS.
-
Is BFS a complete algorithm?
- A search algorithm is said to be complete if at least one solution exists then the algorithm is guaranteed to find a solution in a finite amount of time.
- BFS is complete.
-
Is BFS a optimal algorithm?
- A search algorithm is optimal if it finds a solution, it finds that in the best possible manner.
- BFS is optimal which is why it is being used in cases to find single answer in optimal manner.


 Video Courses
Video Courses











